






13
Jan
【中文分词系列】 6. 基于全卷积网络的中文分词
By 苏剑林 | 2017-01-13 | 57189位读者 | 引用之前已经写过用LSTM来做分词的方案了,今天再来一篇用CNN的,准确来说是FCN,全卷积网络。其实这个模型的主要目的并非研究中文分词,而是练习tensorflow。从两年前就开始用Keras了,可以说对它比较熟了,也渐渐发现了它的一些不足,比如处理变长输入时不方便、加入自定义的约束比较困难等,所以干脆试试原生的tensorflow了,试了之后发现其实也不复杂。嗯,都是python,能有多复杂。本文就是练习一下如何用tensorflow处理不定长输入任务,以中文分词为例,并在最后加入了硬解码,将深度学习与词典分词结合了起来。
CNN
另外,就是关于FCN的。放到语言任务中看,(一维)卷积其实就是ngram模型,从这个角度来看其实CNN远比RNN来得自然,RNN好像就是为序列任务精心设计的,而CNN则是传统ngram模型的一个延伸。另外不管CNN和RNN都有权值共享,看上去只是为了降低运算量的一个折中选择,但事实上里边大有道理。CNN中的权值共享是平移不变性的必然结果,而不是仅仅是降低运算量的一个选择,试想一下,将一幅图像平移一点点,或者在一个句子前插入一个无意义的空格(导致后面所有字都向后平移了一位),这样应该给出一个相似甚至相同的结果,而这要求卷积必然是权值共享的,即权值不能跟位置有关系。
11
Jan
狄拉克函数:级数逼近
By 苏剑林 | 2017-01-11 | 43075位读者 | 引用魏尔斯特拉斯定理
将狄拉克函数理解为函数的极限,可以衍生出很丰富的内容,而且这些内容离严格的证明并不遥远。比如,定义
$$\delta_n(x)=\left\{\begin{aligned}&\frac{(1-x^2)^n}{I_n},x\in[-1,1]\\
&0,\text{其它情形}\end{aligned}\right.$$
其中$I_n = \int_{-1}^1 (1-x^2)^n dx$,于是不难证明
$$\delta(x)=\lim_{n\to\infty}\delta_n(x)$$
这样,对于$[a,b]$上的连续函数$f(x)$,我们就得到
$$f(x)=\int_{-1}^1 f(y)\delta(x-y)dy = \lim_{n\to\infty}\int_{-1}^1 f(y)\delta_n(x-y) dy$$
这里$-1 < a < b < 1$,并且我们已经“不严谨”地交换了积分号和极限号,但这不是特别重要。重要的是它的结果:可以看到
$$P_n(x)=\int_{-1}^1 f(y)\delta_n(x-y) dy$$
是$x$的一个$2n$次多项式,因此上式表明$f(x)$是一个$2n$次的多项式的极限!这就引出了著名的“魏尔斯特拉斯定理”:
闭区间上的连续函数都可以用多项式一致地逼近。
11
Mar
【中文分词系列】 8. 更好的新词发现算法
By 苏剑林 | 2017-03-11 | 214211位读者 | 引用如果依次阅读该系列文章的读者,就会发现这个系列共提供了两种从0到1的无监督分词方案,第一种就是《【中文分词系列】 2. 基于切分的新词发现》,利用相邻字凝固度(互信息)来做构建词库(有了词库,就可以用词典法分词);另外一种是《【中文分词系列】 5. 基于语言模型的无监督分词》,后者基本上可以说是提供了一种完整的独立于其它文献的无监督分词方法。
但总的来看,总感觉前面一种很快很爽,却又显得粗糙;后面一种很好很强大,却又显得太过复杂(viterbi是瓶颈之一)。有没有可能在两者之间折中一下?这就导致了本文的结果,达到了速度与效果的平衡。至于为什么说“更好”?因为笔者研究词库构建也有一段时间了,以往构建的词库总不能让人(让自己)满意,生成的词库一眼看上去,都能够扫到不少不合理的地方,真的要用得需要经过较多的人工筛选。而这一次,一次性生成的词库,一眼扫过去,不合理的地方少了很多,如果不细看,可能就发现不了了。
分词的目的
12
Apr
【语料】百度的中文问答数据集WebQA
By 苏剑林 | 2017-04-12 | 214235位读者 | 引用信息抽取
众所周知,百度知道上有大量的人提了大量的问题,并且得到大量的回复。然而,百度知道上的回复者貌似懒人居多,他们往往喜欢直接在网上复制粘贴一大片来作为回答内容,而且这些内容可能跟问题相关,也可能跟问题不相关,比如
https://zhidao.baidu.com/question/557785746.html
问:广州白云山海拨多高
答:广州白云山(Guangzhou Baiyun Mountain),是新 “羊城八景”之首、国家4A级景区和国家重点风景名胜区。它位于广州市的东北部,为南粤名山之一,自古就有“羊城第一秀”之称。山体相当宽阔,由30多座山峰组成,为广东最高峰九连山的支脉。面积20.98平方公里,主峰摩星岭高382米(注:最新测绘高度为372.6米——国家测绘局,2008年),峰峦重叠,溪涧纵横,登高可俯览全市,遥望珠江。每当雨后天晴或暮春时节,山间白云缭绕,蔚为奇观,白云山之名由此得来
8
Aug
【备忘】谈谈dropout
By 苏剑林 | 2017-08-08 | 31280位读者 | 引用其实这只是一篇备忘...
dropout是深度学习中防止过拟合的一项有效措施,当然,就其思想而言,dropout其实也不仅仅可以用在深度学习中,还可以用在传统的机器学习方法中,只不过在深度学习的神经网络框架下,dropout显得更为自然罢了。
做了什么
dropout是怎么操作的?一般来做,对于输入的张量$x$,dropout就是将部分元素置零,然后将置零后的结果做一个尺度变换。具体来说,以Keras的Dropout(0.6)(x)为例,实际上等价于numpy做的这件事情
import numpy as np
x = np.random.random((10,100)) #模拟一个batch_size=10、维度为100的输入
def Dropout(x, drop_proba):
return x*np.random.choice(
[0,1],
x.shape,
p=[drop_proba,1-drop_proba]
)/(1.-drop_proba)
print Dropout(x, 0.6)
22
Jul
Keras中自定义复杂的loss函数
By 苏剑林 | 2017-07-22 | 411810位读者 | 引用Keras是一个搭积木式的深度学习框架,用它可以很方便且直观地搭建一些常见的深度学习模型。在tensorflow出来之前,Keras就已经几乎是当时最火的深度学习框架,以theano为后端,而如今Keras已经同时支持四种后端:theano、tensorflow、cntk、mxnet(前三种官方支持,mxnet还没整合到官方中),由此可见Keras的魅力。
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
输入-输出设计
Keras的模型是函数式的,即有输入,也有输出,而loss即为预测值与真实值的某种误差函数。Keras本身也自带了很多loss函数,如mse、交叉熵等,直接调用即可。而要自定义loss,最自然的方法就是仿照Keras自带的loss进行改写。
24
Mar
基于CNN和VAE的作诗机器人:随机成诗
By 苏剑林 | 2018-03-24 | 117894位读者 | 引用前几日写了一篇VAE的通俗解读,也得到了一些读者的认可。然而,你是否厌倦了每次介绍都只有一个MNIST级别的demo?不要急,这就给大家带来一个更经典的VAE玩具:机器人作诗。
为什么说“更经典”呢?前一篇文章我们说过用VAE生成的图像相比GAN生成的图像会偏模糊,也就是在图像这一“仗”上,VAE是劣势。然而,在文本生成这一块上,VAE却漂亮地胜出了。这是因为GAN希望把判别器(度量)也直接训练出来,然而对于文本来说,这个度量很可能是离散的、不可导的,因此纯GAN就很难训练了。而VAE中没有这个步骤,它是通过重构输入来完成的,这个重构过程对于图像还是文本都可以进行。所以,文本生成这件事情,对于VAE来说它就跟图像生成一样,都是一个基本的、直接的应用;对于(目前的)GAN来说,却是艰难的象征,是它挥之不去的“心病”。
嗯,古有曹植七步作诗,今有VAE随机成诗,让我们开始吧~
模型
对于很多人来说,诗是一个很美妙的玩意,美妙之处在于大多数人都不真正懂得诗,但大家对诗的模样又有一知半解的认识。因此,只要生成的“诗”稍微像模像样一点,我们通常都会认为机器人可以作诗了。因此,所谓作诗机器人,是一个纯粹的玩具了,能作几句诗,也不意味着普通语言的生成能力有多好,也不意味着我们对NLP的理解有多深。
CNN + VAE
就本文的玩具而言,其实是一个比较简单的模型,主要是把一维CNN和VAE结合了起来。因为生成的诗长度是固定的,所以不管是encoder还是decoder,我都只是用了纯CNN来做。模型的结构图大概是:
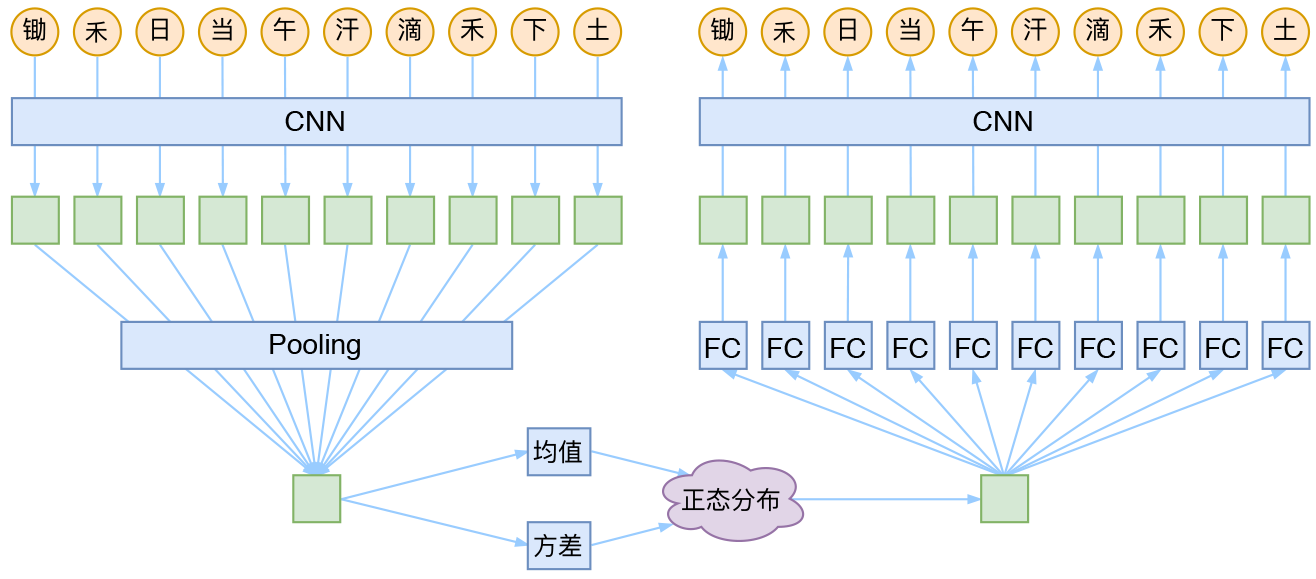
cnn + vae 诗歌生成模型
15
Apr
基于CNN的阅读理解式问答模型:DGCNN
By 苏剑林 | 2018-04-15 | 416848位读者 | 引用2019.08.20更新:开源了一个Keras版(https://kexue.fm/archives/6906)
早在年初的《Attention is All You Need》的介绍文章中就已经承诺过会分享CNN在NLP中的使用心得,然而一直不得其便。这几天终于下定决心来整理一下相关的内容了。
背景
事不宜迟,先来介绍一下模型的基本情况。
模型特点
本模型——我称之为DGCNN——是基于CNN和简单的Attention的模型,由于没有用到RNN结构,因此速度相当快,而且是专门为这种WebQA式的任务定制的,因此也相当轻量级。SQUAD排行榜前面的模型,如AoA、R-Net等,都用到了RNN,并且还伴有比较复杂的注意力交互机制,而这些东西在DGCNN中基本都没有出现。
这是一个在GTX1060上都可以几个小时训练完成的模型!

截止到2018.04.14的排行榜
DGCNN,全名为Dilate Gated Convolutional Neural Network,即“膨胀门卷积神经网络”,顾名思义,融合了两个比较新的卷积用法:膨胀卷积、门卷积,并增加了一些人工特征和trick,最终使得模型在轻、快的基础上达到最佳的效果。在本文撰写之时,本文要介绍的模型还位于榜首,得分(得分是准确率与F1的平均)为0.7583,而且是到目前为止唯一一个一直没有跌出前三名、并且获得周冠军次数最多的模型。

最近评论