






28
Sep
生成扩散模型漫谈(十二):“硬刚”扩散ODE
By 苏剑林 | 2022-09-28 | 67283位读者 | 引用在《生成扩散模型漫谈(五):一般框架之SDE篇》中,我们从SDE的角度理解了生成扩散模型,然后在《生成扩散模型漫谈(六):一般框架之ODE篇》中,我们知道SDE对应的扩散模型中,实际上隐含了一个ODE模型。无独有偶,在《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中我们也知道原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE。
细想上述过程,可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。
微分方程
像GAN这样的生成模型,它本质上是希望找到一个确定性变换,能将从简单分布(如标准正态分布)采样出来的随机变量,变换为特定数据分布的样本。flow模型也是生成模型之一,它的思路是反过来,先找到一个能将数据分布变换简单分布的可逆变换,再求解相应的逆变换来得到一个生成模型。
22
Dec
生成扩散模型漫谈(十五):构建ODE的一般步骤(中)
By 苏剑林 | 2022-12-22 | 28441位读者 | 引用上周笔者写了《生成扩散模型漫谈(十四):构建ODE的一般步骤(上)》(当时还没有“上”这个后缀),本以为已经窥见了构建ODE扩散模型的一般规律,结果不久后评论区大神 @gaohuazuo 就给出了一个构建格林函数更高效、更直观的方案,让笔者自愧不如。再联想起之前大神之前在《生成扩散模型漫谈(十二):“硬刚”扩散ODE》同样也给出了一个关于扩散ODE的精彩描述(间接启发了上一篇博客的结果),大神的洞察力不得不让人叹服。
经过讨论和思考,笔者发现大神的思路本质上就是一阶偏微分方程的特征线法,通过构造特定的向量场保证初值条件,然后通过求解微分方程保证终值条件,同时保证了初值和终值条件,真的非常巧妙!最后,笔者将自己的收获总结成此文,作为上一篇的后续。
前情回顾
简单回顾一下上一篇文章的结果。假设随机变量$\boldsymbol{x}_0\in\mathbb{R}^d$连续地变换成$\boldsymbol{x}_T$,其变化规律服从ODE
\begin{equation}\frac{d\boldsymbol{x}_t}{dt}=\boldsymbol{f}_t(\boldsymbol{x}_t)\label{eq-ode}\end{equation}
30
Nov
用热传导方程来指导自监督学习
By 苏剑林 | 2022-11-30 | 29825位读者 | 引用用理论物理来卷机器学习已经不是什么新鲜事了,比如上个月介绍的《生成扩散模型漫谈(十三):从万有引力到扩散模型》就是经典一例。最近一篇新出的论文《Self-Supervised Learning based on Heat Equation》,顾名思义,用热传导方程来做(图像领域的)自监督学习,引起了笔者的兴趣。这种物理方程如何在机器学习中发挥作用?同样的思路能否迁移到NLP中?让我们一起来读读论文。
基本方程
如下图,左边是物理中热传导方程的解,右端则是CAM、积分梯度等显著性方法得到的归因热力图,可以看到两者有一定的相似之处,于是作者认为热传导方程可以作为好的视觉特征的一个重要先验。
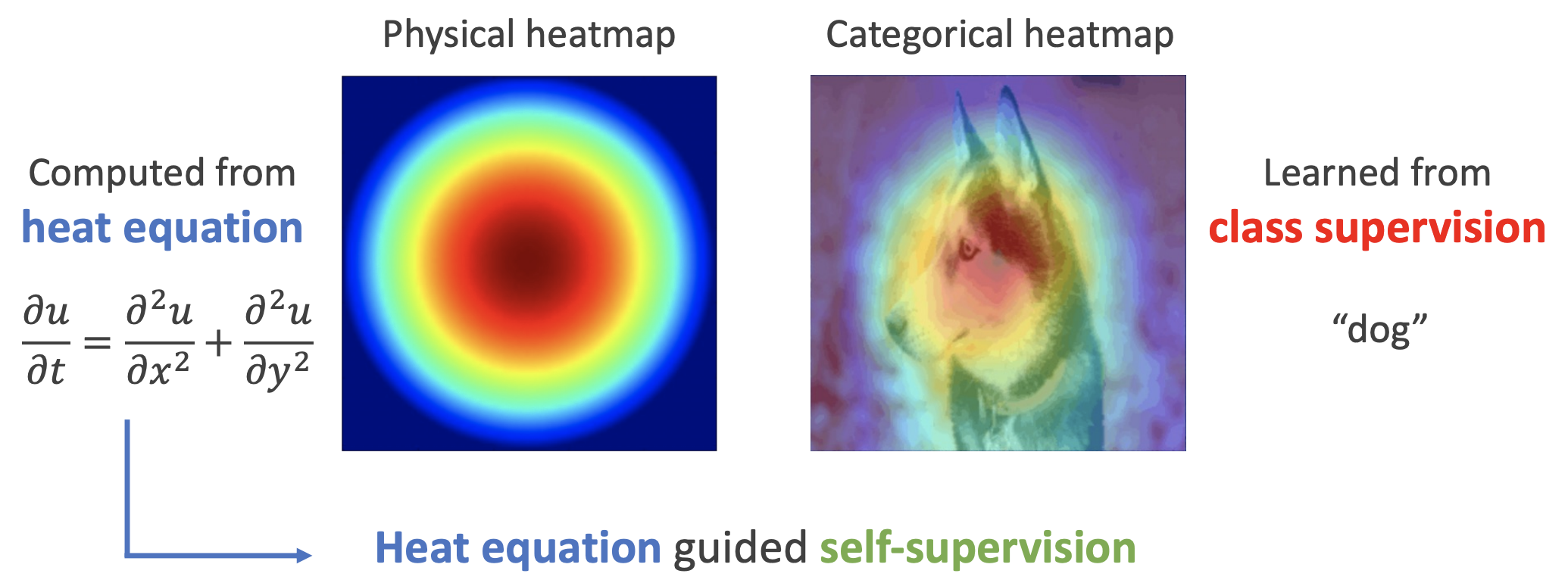
热方程的热力图(左)和视觉模型的热力图(右)
15
Dec
生成扩散模型漫谈(十四):构建ODE的一般步骤(上)
By 苏剑林 | 2022-12-15 | 54796位读者 | 引用书接上文,在《生成扩散模型漫谈(十三):从万有引力到扩散模型》中,我们介绍了一个由万有引力启发的、几何意义非常清晰的ODE式生成扩散模型。有的读者看了之后就疑问:似乎“万有引力”并不是唯一的选择,其他形式的力是否可以由同样的物理绘景构建扩散模型?另一方面,该模型在物理上确实很直观,但还欠缺从数学上证明最后确实能学习到数据分布。
本文就尝试从数学角度比较精确地回答“什么样的力场适合构建ODE式生成扩散模型”这个问题。
基础结论
要回答这个问题,需要用到在《生成扩散模型漫谈(十二):“硬刚”扩散ODE》中我们推导过的一个关于常微分方程对应的分布变化的结论。
考虑$\boldsymbol{x}_t\in\mathbb{R}^d, t\in[0,T]$的一阶(常)微分方程(组)
\begin{equation}\frac{d\boldsymbol{x}_t}{dt}=\boldsymbol{f}_t(\boldsymbol{x}_t)\label{eq:ode}\end{equation}
14
Feb
生成扩散模型漫谈(十六):W距离 ≤ 得分匹配
By 苏剑林 | 2023-02-14 | 23359位读者 | 引用Wasserstein距离(下面简称“W距离”),是基于最优传输思想来度量两个概率分布差异程度的距离函数,笔者之前在《从Wasserstein距离、对偶理论到WGAN》等博文中也做过介绍。对于很多读者来说,第一次听说W距离,是因为2017年出世的WGAN,它开创了从最优传输视角来理解GAN的新分支,也提高了最优传输理论在机器学习中的地位。很长一段时间以来,GAN都是生成模型领域的“主力军”,直到最近这两年扩散模型异军突起,GAN的风头才有所下降,但其本身仍不失为一个强大的生成模型。
从形式上来看,扩散模型和GAN差异很明显,所以其研究一直都相对独立。不过,去年底的一篇论文《Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance》打破了这个隔阂:它证明了扩散模型的得分匹配损失可以写成W距离的上界形式。这意味着在某种程度上,最小化扩散模型的损失函数,实则跟WGAN一样,都是在最小化两个分布的W距离。
8
Jun
Naive Bayes is all you need ?
By 苏剑林 | 2023-06-08 | 45007位读者 | 引用很抱歉,起了这么个具有标题党特征的题目。在写完《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度》之后,笔者就觉得朴素贝叶斯(Naive Bayes)跟Attention机制有很多相同的特征,后来再推导了一下发现,Attention机制其实可以看成是一种广义的、参数化的朴素贝叶斯。既然如此,“Attention is All You Need”不也就意味着“Naive Bayes is all you need”了?这就是本文标题的缘由。
接下来笔者将介绍自己的思考过程,分析如何从朴素贝叶斯角度来理解Attention机制。
朴素贝叶斯
本文主要考虑语言模型,它要建模的是$p(x_t|x_1,\cdots,x_{t-1})$。根据贝叶斯公式,我们有
\begin{equation}p(x_t|x_1,\cdots,x_{t-1}) = \frac{p(x_1,\cdots,x_{t-1}|x_t)p(x_t)}{p(x_1,\cdots,x_{t-1})}\propto p(x_1,\cdots,x_{t-1}|x_t)p(x_t)\end{equation}
16
Jun
梯度流:探索通向最小值之路
By 苏剑林 | 2023-06-16 | 31350位读者 | 引用在这篇文章中,我们将探讨一个被称为“梯度流(Gradient Flow)”的概念。简单来说,梯度流是将我们在用梯度下降法中寻找最小值的过程中的各个点连接起来,形成一条随(虚拟的)时间变化的轨迹,这条轨迹便被称作“梯度流”。在文章的后半部分,我们将重点讨论如何将梯度流的概念扩展到概率空间,从而形成“Wasserstein梯度流”,为我们理解连续性方程、Fokker-Planck方程等内容提供一个新的视角。
梯度下降
假设我们想搜索光滑函数$f(\boldsymbol{x})$的最小值,常见的方案是梯度下降(Gradient Descent),即按照如下格式进行迭代:
\begin{equation}\boldsymbol{x}_{t+1} = \boldsymbol{x}_t -\alpha \nabla_{\boldsymbol{x}_t}f(\boldsymbol{x}_t)\label{eq:gd-d}\end{equation}
如果$f(\boldsymbol{x})$关于$\boldsymbol{x}$是凸的,那么梯度下降通常能够找到最小值点;相反,则通常只能收敛到一个“驻点”——即梯度为0的点,比较理想的情况下能收敛到一个极小值(局部最小值)点。这里没有对极小值和最小值做严格区分,因为在深度学习中,即便是收敛到一个极小值点也是很难得的了。
23
Feb
生成扩散模型漫谈(十七):构建ODE的一般步骤(下)
By 苏剑林 | 2023-02-23 | 76774位读者 | 引用历史总是惊人地相似。当初笔者在写《生成扩散模型漫谈(十四):构建ODE的一般步骤(上)》(当时还没有“上”这个后缀)时,以为自己已经搞清楚了构建ODE式扩散的一般步骤,结果读者 @gaohuazuo 就给出了一个新的直观有效的方案,这直接导致了后续《生成扩散模型漫谈(十四):构建ODE的一般步骤(中)》(当时后缀是“下”)。而当笔者以为事情已经终结时,却发现ICLR2023的论文《Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow》又给出了一个构建ODE式扩散模型的新方案,其简洁、直观的程度简直前所未有,令人拍案叫绝。所以笔者只好默默将前一篇的后缀改为“中”,然后写了这个“下”篇来分享这一新的结果。
直观结果
我们知道,扩散模型是一个$\boldsymbol{x}_T\to \boldsymbol{x}_0$的演化过程,而ODE式扩散模型则指定演化过程按照如下ODE进行:
\begin{equation}\frac{d\boldsymbol{x}_t}{dt}=\boldsymbol{f}_t(\boldsymbol{x}_t)\label{eq:ode}\end{equation}
而所谓构建ODE式扩散模型,就是要设计一个函数$\boldsymbol{f}_t(\boldsymbol{x}_t)$,使其对应的演化轨迹构成给定分布$p_T(\boldsymbol{x}_T)$、$p_0(\boldsymbol{x}_0)$之间的一个变换。说白了,我们希望从$p_T(\boldsymbol{x}_T)$中随机采样一个$\boldsymbol{x}_T$,然后按照上述ODE向后演化得到的$\boldsymbol{x}_0$是$\sim p_0(\boldsymbol{x}_0)$的。

最近评论