






19
Feb
Python的多进程编程技巧
By 苏剑林 | 2017-02-19 | 38679位读者 | 引用过程
在Python中,如果要多进程运算,一般是通过multiprocessing来实现的,常用的是multiprocessing中的进程池,比如:
from multiprocessing import Pool
import time
def f(x):
time.sleep(1)
print x+1
return x+1
a = range(10)
pool = Pool(4)
b = pool.map(f, a)
pool.close()
pool.join()
print b
这样写简明清晰,确实方便,有趣的是,只需要将multiprocessing换成multiprocessing.dummy,就可以将程序从多进程改为多线程了。
11
Mar
【中文分词系列】 8. 更好的新词发现算法
By 苏剑林 | 2017-03-11 | 231492位读者 | 引用如果依次阅读该系列文章的读者,就会发现这个系列共提供了两种从0到1的无监督分词方案,第一种就是《【中文分词系列】 2. 基于切分的新词发现》,利用相邻字凝固度(互信息)来做构建词库(有了词库,就可以用词典法分词);另外一种是《【中文分词系列】 5. 基于语言模型的无监督分词》,后者基本上可以说是提供了一种完整的独立于其它文献的无监督分词方法。
但总的来看,总感觉前面一种很快很爽,却又显得粗糙;后面一种很好很强大,却又显得太过复杂(viterbi是瓶颈之一)。有没有可能在两者之间折中一下?这就导致了本文的结果,达到了速度与效果的平衡。至于为什么说“更好”?因为笔者研究词库构建也有一段时间了,以往构建的词库总不能让人(让自己)满意,生成的词库一眼看上去,都能够扫到不少不合理的地方,真的要用得需要经过较多的人工筛选。而这一次,一次性生成的词库,一眼扫过去,不合理的地方少了很多,如果不细看,可能就发现不了了。
分词的目的
2
Apr
【不可思议的Word2Vec】 1.数学原理
By 苏剑林 | 2017-04-02 | 57545位读者 | 引用对于了解深度学习、自然语言处理NLP的读者来说,Word2Vec可以说是家喻户晓的工具,尽管不是每一个人都用到了它,但应该大家都会听说过它——Google出品的高效率的获取词向量的工具。
Word2Vec不可思议?
大多数人都是将Word2Vec作为词向量的等价名词,也就是说,纯粹作为一个用来获取词向量的工具,关心模型本身的读者并不多。可能是因为模型过于简化了,所以大家觉得这样简化的模型肯定很不准确,所以没法用,但它的副产品词向量的质量反而还不错。没错,如果是作为语言模型来说,Word2Vec实在是太粗糙了。
但是,为什么要将它作为语言模型来看呢?抛开语言模型的思维约束,只看模型本身,我们就会发现,Word2Vec的两个模型 —— CBOW和Skip-Gram —— 实际上大有用途,它们从不同角度来描述了周围词与当前词的关系,而很多基本的NLP任务,都是建立在这个关系之上,如关键词抽取、逻辑推理等。这几篇文章就是希望能够抛砖引玉,通过介绍Word2Vec模型本身,以及几个看上去“不可思议”的用法,来提供一些研究此类问题的新思路。
7
Apr
【不可思议的Word2Vec】 3.提取关键词
By 苏剑林 | 2017-04-07 | 201350位读者 | 引用本文主要是给出了关键词的一种新的定义,并且基于Word2Vec给出了一个实现方案。这种关键词的定义是自然的、合理的,Word2Vec只是一个简化版的实现方案,可以基于同样的定义,换用其他的模型来实现。
说到提取关键词,一般会想到TF-IDF和TextRank,大家是否想过,Word2Vec还可以用来提取关键词?而且,用Word2Vec提取关键词,已经初步含有了语义上的理解,而不仅仅是简单的统计了,而且还是无监督的!
什么是关键词?
诚然,TF-IDF和TextRank是两种提取关键词的很经典的算法,它们都有一定的合理性,但问题是,如果从来没看过这两个算法的读者,会感觉简直是异想天开的结果,估计很难能够从零把它们构造出来。也就是说,这两种算法虽然看上去简单,但并不容易想到。试想一下,没有学过信息相关理论的同学,估计怎么也难以理解为什么IDF要取一个对数?为什么不是其他函数?又有多少读者会破天荒地想到,用PageRank的思路,去判断一个词的重要性?
说到底,问题就在于:提取关键词和文本摘要,看上去都是一个很自然的任务,有谁真正思考过,关键词的定义是什么?这里不是要你去查汉语词典,获得一大堆文字的定义,而是问你数学上的定义。关键词在数学上的合理定义应该是什么?或者说,我们获取关键词的目的是什么?
3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 205579位读者 | 引用前言
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
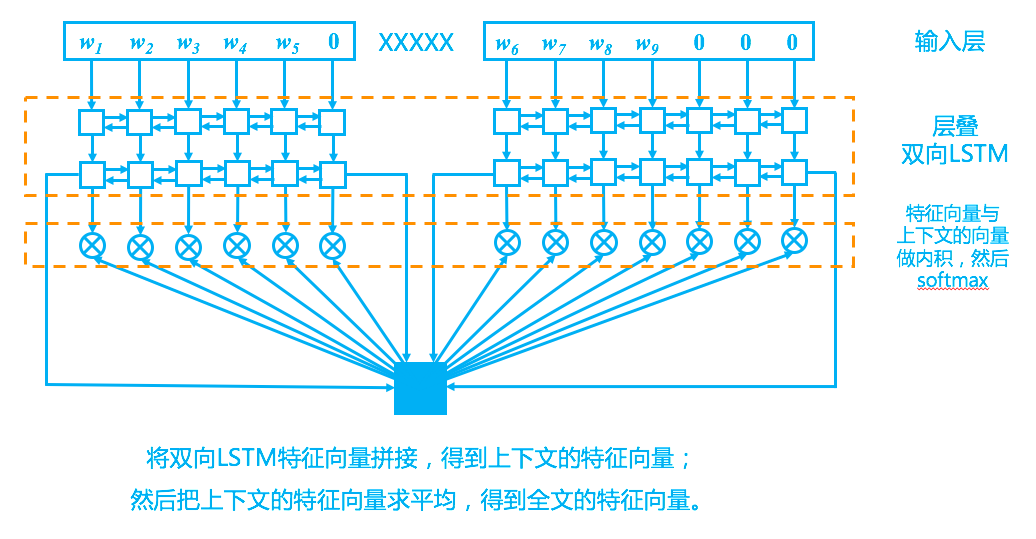
完形填空模型
16
Jul
Linux下的误删大坑与简单的恢复技巧
By 苏剑林 | 2017-07-16 | 29051位读者 | 引用
16
Oct
如何划分一个跟测试集更接近的验证集?
By 苏剑林 | 2020-10-16 | 58906位读者 | 引用不管是打比赛、做实验还是搞工程,我们经常会遇到训练集与测试集分布不一致的情况。一般来说我们会从训练集中划分出来一个验证集,通过这个验证集来调整一些超参数(参考《训练集、验证集和测试集的意义》),比如控制模型的训练轮数以防止过拟合。然而,如果验证集本身跟测试集差别比较大,那么验证集上很好的模型也不代表在测试集上很好,因此如何让划分出来验证集跟测试集的分布差异更小一些,是一个值得研究的题目。
两种情况
首先,明确一下,本文所考虑的,是能给拿到测试集数据本身、但不知道测试集标签的场景。如果是那种提交模型封闭评测的场景,我们完全看不到测试集的,那就没什么办法了。为什么会出现测试集跟训练集分布不一致的现象呢?主要有两种情况。
14
Oct

最近评论