






24
Apr
最小熵原理(二):“当机立断”之词库构建
By 苏剑林 | 2018-04-24 | 85531位读者 | 引用在本文,我们介绍“套路宝典”第一式——“当机立断”:1、导出平均字信息熵的概念,然后基于最小熵原理推导出互信息公式;2、并且完成词库的无监督构建、给出一元分词模型的信息熵诠释,从而展示有关生成套路、识别套路的基本方法和技巧。
这既是最小熵原理的第一个使用案例,也是整个“套路宝典”的总纲。
你练或者不练,套路就在那里,不增不减。
为什么需要词语
从上一篇文章可以看到,假设我们根本不懂中文,那么我们一开始会将中文看成是一系列“字”随机组合的字符串,但是慢慢地我们会发现上下文是有联系的,它并不是“字”的随机组合,它应该是“套路”的随机组合。于是为了减轻我们的记忆成本,我们会去挖掘一些语言的“套路”。第一个“套路”,是相邻的字之间的组合定式,这些组合定式,也就是我们理解的“词”。
平均字信息熵
假如有一批语料,我们将它分好词,以词作为中文的单位,那么每个词的信息量是$-\log p_w$,因此我们就可以计算记忆这批语料所要花费的时间为
$$-\sum_{w\in \text{语料}}\log p_w\tag{2.1}$$
这里$w\in \text{语料}$是对语料逐词求和,不用去重。如果不分词,按照字来理解,那么需要的时间为
$$-\sum_{c\in \text{语料}}\log p_c\tag{2.2}$$
10
May
用Numpy实现高效的Apriori算法
By 苏剑林 | 2018-05-10 | 96716位读者 | 引用
11
May
【致敬】费曼诞辰100年
By 苏剑林 | 2018-05-11 | 31377位读者 | 引用
18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 336596位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
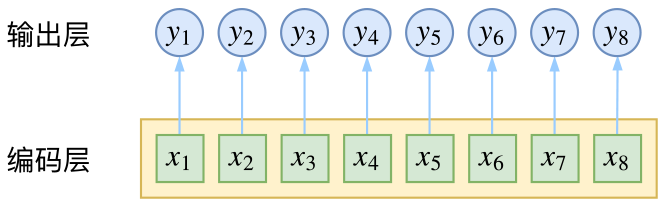
逐帧softmax并没有直接考虑输出的上下文关联
21
May
厨房,菜市场,其实都是武林
By 苏剑林 | 2018-05-21 | 40930位读者 | 引用

30
May
最小熵原理(三):“飞象过河”之句模版和语言结构
By 苏剑林 | 2018-05-30 | 60694位读者 | 引用在前一文《最小熵原理(二):“当机立断”之词库构建》中,我们以最小熵原理为出发点进行了一系列的数学推导,最终得到$(2.15)$和$(2.17)$式,它告诉我们两个互信息比较大的元素我们应该将它们合并起来,这有利于降低“学习难度”。于是利用这一原理,我们通过邻字互信息来实现了词库的无监督生成。
由字到词、由词到词组,考察的是相邻的元素能不能合并成一个好“套路”。可是套路为什么非得要相邻的呢?当然不一定相邻,我们学习语言的时候,不仅仅会学习到词语、词组,还要学习到“固定搭配”,也就是说词语怎么运用才是合理的,这是语法的体现,是本文所要探究的,希望最终能达到一定的无监督句法分析的效果。
由于这次我们考虑的是跨邻词的语言关联,因此我给它起个名字为“飞象过河”,正是
“套路宝典”第二式——“飞象过河”
语言结构
对于大多数人来说,并不会真正知道什么是语法,他们脑海里就只有一些“固定搭配”、“定式”,或者更正式一点可以叫“模版”。大多数情况下,我们是根据模版来说出合理的话来。而不同的人的说话模版可能有所不同,这就是个人的说话风格,甚至是“口头禅”。
7
Jun
python简单实现gillespie模拟
By 苏剑林 | 2018-06-07 | 73385位读者 | 引用
23
Jun
貌离神合的RNN与ODE:花式RNN简介
By 苏剑林 | 2018-06-23 | 105914位读者 | 引用本来笔者已经决心不玩RNN了,但是在上个星期思考时忽然意识到RNN实际上对应了ODE(常微分方程)的数值解法,这为我一直以来想做的事情——用深度学习来解决一些纯数学问题——提供了思路。事实上这是一个颇为有趣和有用的结果,遂介绍一翻。顺便地,本文也涉及到了自己动手编写RNN的内容,所以本文也可以作为编写自定义的RNN层的一个简单教程。
注:本文并非前段时间的热点“神经ODE”的介绍(但有一定的联系)。
RNN基本
什么是RNN?
众所周知,RNN是“循环神经网络(Recurrent Neural Network)”,跟CNN不同,RNN可以说是一类模型的总称,而并非单个模型。简单来讲,只要是输入向量序列$(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_T)$,输出另外一个向量序列$(\boldsymbol{y}_1,\boldsymbol{y}_2,\dots,\boldsymbol{y}_T)$,并且满足如下递归关系
$$\boldsymbol{y}_t=f(\boldsymbol{y}_{t-1}, \boldsymbol{x}_t, t)\tag{1}$$
的模型,都可以称为RNN。也正因为如此,原始的朴素RNN,还有改进的如GRU、LSTM、SRU等模型,我们都称为RNN,因为它们都可以作为上式的一个特例。还有一些看上去与RNN没关的内容,比如前不久介绍的CRF的分母的计算,实际上也是一个简单的RNN。
说白了,RNN其实就是递归计算。

最近评论