






17
May
正项级数敛散性最有力的判别法?
By 苏剑林 | 2013-05-17 | 97577位读者 | 引用在学习正项级数的时候,我们的数学分析教材提供了各种判别法,比如积分判别法、比较判别法,并由此衍生出了根植法、比值法等,在最后提供了一个比较精细的“Raabe判别法”。这些方法的精度(强度)各不相同,一般认为“Raabe判别法”的应用范围最广的。但是在我看来,基于p级数的比较判别法已经可以用于所有题目了,它才是最强的方法。
p级数就是我们熟悉的
$$\sum_{n=1}^{\infty} \frac{1}{n^p}$$
通过积分判别法可以得到当p>1时该级数收敛,反之发散。虽然我不能证明,但是我觉得以下结论是成立的:
若正项级数$\sum_{n=1}^{\infty} a_n$收敛,则总可以找到一个常数A以及一个大于1的常数p,使每项都有$a_n < \frac{A}{n^p}$。
1
Jul
与首都机场的“难分难舍”
By 苏剑林 | 2013-07-01 | 16713位读者 | 引用
无尽的等待
上个月的最后三天(06.28-06.30),我去国家天文台参加了第三届宇宙驿站的站长联谊会及科普研讨会。会议在河北兴隆天文台举行,我们按照计划是先到北京总部,然后去兴隆,然后回到北京总部解散。具体的故事我会另写文章与大家分享,本文主要想说一下我与北京首都国际机场的“难分难舍”的返程之旅。
按照计划,我是昨晚9点的飞机,今天凌晨应该可以到广州。我七点多到机场,八点左右就办完了登记手续,然而,我们等了两三个钟,最终得到的结果是:由于雷暴雨的影响(北京并没有下雨,估计是途中某个地方的上空天气太糟糕),该航班取消,补到第二天七点......这对我来说可真是个大考验。虽说航空公司会为我们联系宾馆,但是效率之低让不少人在机场抗议,于是乎冰冷的机场一下子就热闹起来的(取消的不知我们一趟航班,还有很多其他航班)。而我虽然来过好几次北京,毕竟还属于“异客”,自然经验不足,但我做出了一个很大胆的决定:在机场过夜!
农村的孩子免不了常做家务,当然我家也没有什么特别沉重的家务,通常都是扫地、做饭、洗菜这些简单的活儿。说到洗菜,洗完菜后总喜欢边放水边搅水,然后就在水面上形成一个颇为有趣的漩涡。现在我们从数学物理的角度来分析一下这个漩涡。
在讲洗手盆的漩涡之前,我们先来看一下一个比较类似的、更古老的问题——牛顿的旋转液面问题。牛顿假设有一个水桶(假设为圆柱形吧,但这不重要),水桶在绕自己的中轴线匀角速度旋转,直到桶内的水也随着匀角速度旋转(即水与水桶相对静止),此时水的液面形状是凹的,我们来看看该液面的形状。
牛顿的水桶
要分析形状,我们还要回顾之前提到过的流体静力学平衡:
http://kexue.fm/archives/1964/
26
Dec
【学习清单】最近比较重要的GAN进展论文
By 苏剑林 | 2018-12-26 | 66232位读者 | 引用这篇文章简单列举一下我认为最近这段时间中比较重要的GAN进展论文,这基本也是我在学习GAN的过程中主要去研究的论文清单。
生成模型之味
GAN是一个大坑,尤其像我这样的业余玩家,一头扎进去很久也很难有什么产出,尤其是各个大公司拼算力搞出来一个个大模型,个人几乎都没法玩了。但我总觉得,真的去碰了生成模型,才觉得自己碰到了真正的机器学习。这一点,不管在图像中还是文本中都是如此。所以,我还是愿意去关注生成模型。
当然,GAN不是生成模型的唯一选择,却是一个非常有趣的选择。在图像中至少有GAN、flow、pixelrnn/pixelcnn这几种选择,但要说潜力,我还是觉得GAN才是最具前景的,不单是因为效果,主要是因为它那对抗的思想。而在文本中,事实上seq2seq机制就是一个概率生成模型了,而pixelrnn这类模型,实际上就是模仿着seq2seq来做的,当然也有用GAN做文本生成的研究(不过基本上都涉及到了强化学习)。也就是说,其实在NLP中,生成模型也有很多成果,哪怕你主要是研究NLP的,也终将碰到生成模型。
好了,话不多说,还是赶紧把清单列一列,供大家参考,也作为自己的备忘。
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 426813位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
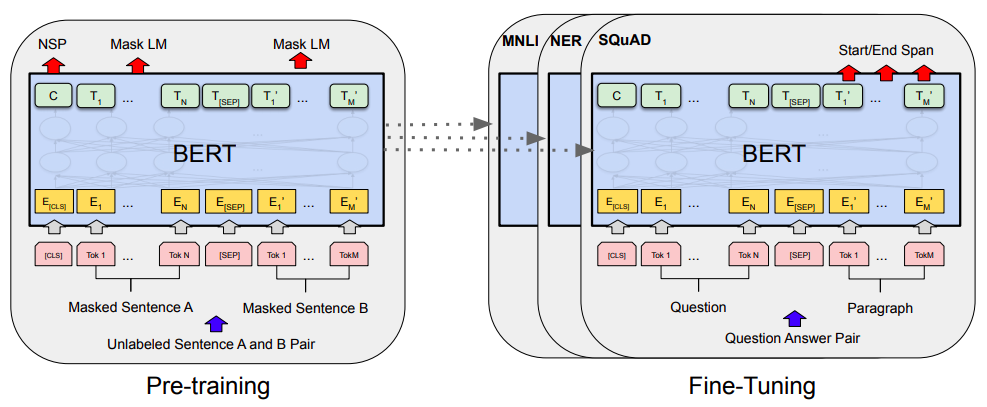
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
7
Sep
动手做个DialoGPT:基于LM的生成式多轮对话模型
By 苏剑林 | 2020-09-07 | 104541位读者 | 引用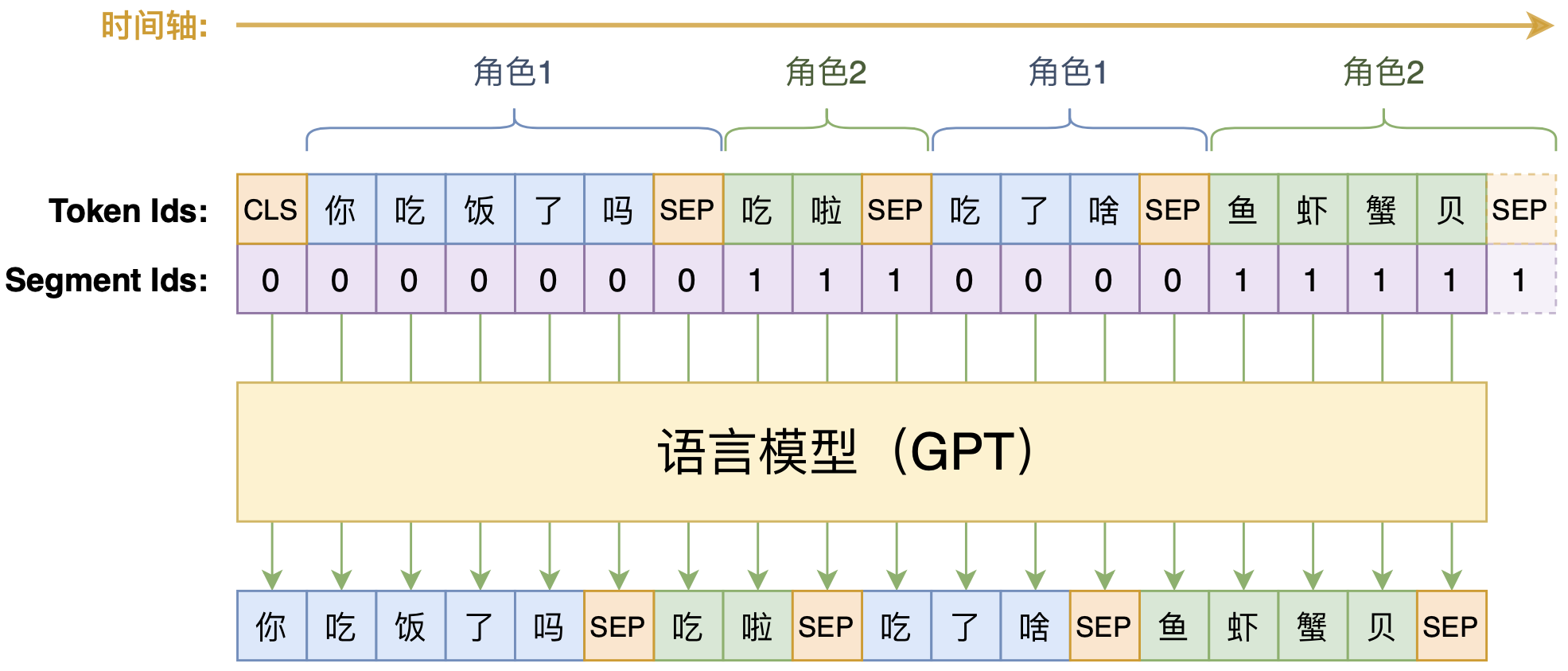
7
Dec
【龟鱼记】全陶粒的同程底滤生态缸
By 苏剑林 | 2020-12-07 | 58124位读者 | 引用
22
Apr
GAU-α:尝鲜体验快好省的下一代Attention
By 苏剑林 | 2022-04-22 | 48745位读者 | 引用在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了GAU(Gated Attention Unit,门控线性单元),在这里笔者愿意称之为“目前最有潜力的下一代Attention设计”,因为它真正达到了“更快(速度)、更好(效果)、更省(显存)”的特点。
然而,有些读者在自己的测试中得到了相反的结果,比如收敛更慢、效果更差等,这与笔者的测试结果大相径庭。本文就来分享一下笔者自己的训练经验,并且放出一个尝鲜版“GAU-α”供大家测试。
GAU-α
首先介绍一下开源出来的“GAU-α”在CLUE任务上的成绩单:
$$\small{\begin{array}{c|ccccccccccc}
\hline
& \text{iflytek} & \text{tnews} & \text{afqmc} & \text{cmnli} & \text{ocnli} & \text{wsc} & \text{csl} & \text{cmrc2018} & \text{c3} & \text{chid} & \text{cluener}\\
\hline
\text{BERT} & 60.06 & 56.80 & 72.41 & 79.56 & 73.93 & 78.62 & 83.93 & 56.17 & 60.54 & 85.69 & 79.45 \\
\text{RoBERTa} & 60.64 & \textbf{58.06} & 74.05 & 81.24 & 76.00 & \textbf{87.50} & 84.50 & 56.54 & 67.66 & 86.71 & 79.47\\
\text{RoFormer} & 60.91 & 57.54 & 73.52 & 80.92 & \textbf{76.07} & 86.84 & 84.63 & 56.26 & 67.24 & 86.57 & 79.72\\
\text{RoFormerV2}^* & 60.87 & 56.54 & 72.75 & 80.34 & 75.36 & 80.92 & 84.67 & 57.91 & 64.62 & 85.09 & \textbf{81.08}\\
\hline
\text{GAU-}\alpha & \textbf{61.41} & 57.76 & \textbf{74.17} & \textbf{81.82} & 75.86 & 79.93 & \textbf{85.67} & \textbf{58.09} & \textbf{68.24} & \textbf{87.91} & 80.01\\
\hline
\end{array}}$$

最近评论