






29
Jul
基于GRU和AM-Softmax的句子相似度模型
By 苏剑林 | 2018-07-29 | 336878位读者 | 引用搞计算机视觉的朋友会知道,AM-Softmax是人脸识别中的成果。所以这篇文章就是借鉴人脸识别的做法来做句子相似度模型,顺便介绍在Keras下各种margin loss的写法。
背景
细想之下会发现,句子相似度与人脸识别有很多的相似之处~
已有的做法
在我搜索到的资料中,深度学习做句子相似度模型,就只有两种做法:一是输入一对句子,然后输出一个0/1标签代表相似程度,也就是视为一个二分类问题,比如《Learning Text Similarity with Siamese Recurrent Networks》中的模型是这样的
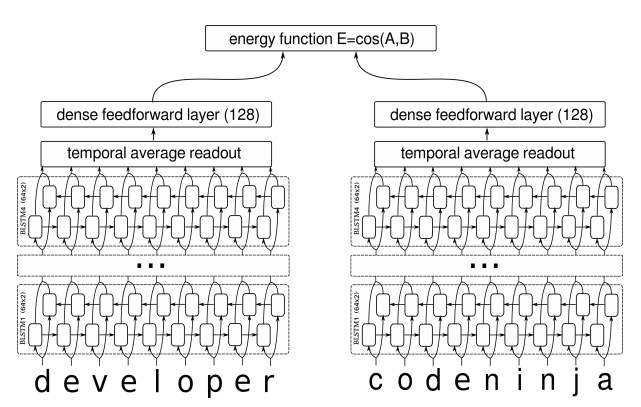
将句子相似度视为二分类模型
包括今年拍拍贷的“魔镜杯”,也是这种格式。另外一种做法是输入一个三元组“(句子A,跟A相似的句子,跟A不相似的句子)”,然后用triplet loss的做法解决,比如文章《Applying Deep Learning To Answer Selection: A Study And An Open Task》中的做法。
这两种做法其实也可以看成是一种,本质上是一样的,只不过loss和训练方法有所差别。但是,这两种方法却都有一个很严重的问题:负样本采样严重不足,导致效果提升非常慢。
29
Nov
Dropout视角下的MLM和MAE:一些新的启发
By 苏剑林 | 2021-11-29 | 75289位读者 | 引用大家都知道,BERT的MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了[MASK]而下游任务微调时没有[MASK],是经常被吐槽的问题,很多工作都认为这是影响BERT微调性能的重要原因,并针对性地提出了很多改进,如XL-NET、ELECTRA、MacBERT等。本文我们将从Dropout的角度来分析MLM的这种不一致性,并且提出一种简单的操作来修正这种不一致性。
同样的分析还可以用于何凯明最近提出的比较热门的MAE(Masked Autoencoder)模型,结果是MAE相比MLM确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。
Dropout
首先,我们重温一下Dropout。从数学上来看,Dropout是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。
22
Oct
RSGAN:对抗模型中的“图灵测试”思想
By 苏剑林 | 2018-10-22 | 129185位读者 | 引用这两天无意间发现一个非常有意义的工作,称为“相对GAN”,简称RSGAN,来自文章《The relativistic discriminator: a key element missing from standard GAN》,据说该文章还得到了GAN创始人Goodfellow的点赞。这篇文章提出了用相对的判别器来取代标准GAN原有的判别器,使得生成器的收敛更为迅速,训练更为稳定。
可惜的是,这篇文章仅仅从训练和实验角度对结果进行了论述,并没有进行更深入的分析,以至于不少人觉得这只是GAN训练的一个trick。但是在笔者来看,RSGAN具有更为深刻的含义,甚至可以看成它已经开创了一个新的GAN流派。所以,笔者决定对RSGAN模型及其背后的内涵做一个基本的介绍。不过需要指出的是,除了结果一样之外,本文的介绍过程跟原论文相比几乎没有重合之处。
“图灵测试”思想
SGAN
SGAN就是标准的GAN(Standard GAN)。就算没有做过GAN研究的读者,相信也从各种渠道了解到GAN的大概原理:“造假者”不断地进行造假,试图愚弄“鉴别者”;“鉴别者”不断提高鉴别技术,以分辨出真品和赝品。两者相互竞争,共同进步,直到“鉴别者”无法分辨出真、赝品了,“造假者”就功成身退了。
在建模时,通过交替训练实现这个过程:固定生成器,训练一个判别器(二分类模型),将真实样本输出1,将伪造样本输出0;然后固定判别器,训练生成器让伪造样本尽可能输出1,后面这一步不需要真实样本参与。
问题所在
然而,这个建模过程似乎对判别器的要求过于苛刻了,因为判别器是孤立运作的:训练生成器时,真实样本没有参与,所以判别器必须把关于真实样本的所有属性记住,这样才能指导生成器生成更真实的样本。
11
Nov
JoSE:球面上的词向量和句向量
By 苏剑林 | 2019-11-11 | 69222位读者 | 引用这篇文章介绍一个发表在NeurIPS 2019的做词向量和句向量的模型JoSE(Joint Spherical Embedding),论文名字是《Spherical Text Embedding》。JoSE模型思想上和方法上传承自Doc2Vec,评测结果更加漂亮,但写作有点故弄玄虚之感。不过笔者决定写这篇文章,是因为觉得里边的某些分析过程有点意思,可能会对一般的优化问题都有些参考价值。
优化目标
在思想上,这篇文章基本上跟Doc2Vec是一致的:为了训练句向量,把句子用一个id表示,然后把它也当作一个词,跟句内所有的词都共现,最后训练一个Skip Gram模型,训练的方式都是基于负采样的。跟Doc2Vec不一样的是,JoSE将全体向量的模长都归一化了(也就是只考虑单位球面上的向量),然后训练目标没有用交叉熵,而是用hinge loss:
\begin{equation}\max(0, m - \cos(\boldsymbol{u}, \boldsymbol{v}) - \cos(\boldsymbol{u}, \boldsymbol{d}) + \cos(\boldsymbol{u}', \boldsymbol{v}) + \cos(\boldsymbol{u}', \boldsymbol{d})\label{eq:loss}\end{equation}
3
May
从动力学角度看优化算法(四):GAN的第三个阶段
By 苏剑林 | 2019-05-03 | 97429位读者 | 引用在对GAN的学习和思考过程中,我发现我不仅学习到了一种有效的生成模型,而且它全面地促进了我对各种模型各方面的理解,比如模型的优化和理解视角、正则项的意义、损失函数与概率分布的联系、概率推断等等。GAN不单单是一个“造假的玩具”,而是具有深刻意义的概率模型和推断方法。
作为事后的总结,我觉得对GAN的理解可以粗糙地分为三个阶段:
1、样本阶段:在这个阶段中,我们了解了GAN的“鉴别者-造假者”诠释,懂得从这个原理出发来写出基本的GAN公式(如原始GAN、LSGAN),比如判别器和生成器的loss,并且完成简单GAN的训练;同时,我们知道GAN有能力让图片更“真”,利用这个特性可以把GAN嵌入到一些综合模型中。
2、分布阶段:在这个阶段中,我们会从概率分布及其散度的视角来分析GAN,典型的例子是WGAN和f-GAN,同时能基本理解GAN的训练困难问题,比如梯度消失和mode collapse等,甚至能基本地了解变分推断,懂得自己写出一些概率散度,继而构造一些新的GAN形式。
3、动力学阶段:在这个阶段中,我们开始结合优化器来分析GAN的收敛过程,试图了解GAN是否能真的达到理论的均衡点,进而理解GAN的loss和正则项等因素如何影响的收敛过程,由此可以针对性地提出一些训练策略,引导GAN模型到达理论均衡点,从而提高GAN的效果。
16
Jun
如何应对Seq2Seq中的“根本停不下来”问题?
By 苏剑林 | 2020-06-16 | 64716位读者 | 引用在Seq2Seq的解码过程中,我们是逐个token地递归生成的,直到出现<eos>标记为止,这就是所谓的“自回归”生成模型。然而,研究过Seq2Seq的读者应该都能发现,这种自回归的解码偶尔会出现“根本停不下来”的现象,主要是某个片段反复出现,比如“今天天气不错不错不错不错不错...”、“你觉得我说得对不对不对不对不对不对...”等等,但就是死活不出现<eos>标记。ICML 2020的文章《Consistency of a Recurrent Language Model With Respect to Incomplete Decoding》比较系统地讨论了这个现象,并提出了一些对策,本文来简单介绍一下论文的主要内容。
解码算法
对于自回归模型来说,我们建立的是如下的条件语言模型
\begin{equation}p(y_t|y_{\lt t}, x)\label{eq:p}\end{equation}
那么解码算法就是在已知上述模型时,给定$x$来输出对应的$y=(y_1,y_2,\dots,y_T)$来。解码算法大致可以分为两类:确定性解码算法和随机性解码算法,原论文分别针对这两类解码讨论来讨论了“根本停不下来”问题,所以我们需要来了解一下这两类解码算法。
9
Feb
一个二值化词向量模型,是怎么跟果蝇搭上关系的?
By 苏剑林 | 2021-02-09 | 27121位读者 | 引用
果蝇(图片来自Google搜索)
可能有些读者最近会留意到ICLR 2021的论文《Can a Fruit Fly Learn Word Embeddings?》,文中写到它是基于仿生思想(仿果蝇的嗅觉回路)做出来的一个二值化词向量模型。其实论文的算法部分并不算难读,可能整篇论文读下来大家的最主要疑惑就是“这东西跟果蝇有什么关系?”、“作者真是从果蝇里边受到启发的?”等等。本文就让我们来追寻一下该算法的来龙去脉,试图回答一下这个词向量模型是怎么跟果蝇搭上关系的。
BioWord
原论文并没有给该词向量模型起个名字,为了称呼上的方便,这里笔者就自作主张将其称为“BioWord”了。总的来说,论文内容大体上有三部分:
1、给每个n-gram构建了一个词袋表示向量;
2、对这些n-gram向量执行BioHash算法,得到所谓的(二值化的)静态/动态词向量;
3、“拼命”讲了一个故事。
26
Jan
Seq2Seq重复解码现象的理论分析尝试
By 苏剑林 | 2021-01-26 | 32671位读者 | 引用去年笔者写过博文《如何应对Seq2Seq中的“根本停不下来”问题?》,里边介绍了一篇论文中对Seq2Seq解码不停止现象的处理,并指出那篇论文只是提了一些应对该问题的策略,并没有提供原理上的理解。近日,笔者在Arixv读到了AAAI 2021的一篇名为《A Theoretical Analysis of the Repetition Problem in Text Generation》的论文,里边从理论上分析了Seq2Seq重复解码现象。从本质上来看,重复解码和解码不停止其实都是同理的,所以这篇新论文算是填补了前面那篇论文的空白。
经过学习,笔者发现该论文确实有不少可圈可点之处,值得一读。笔者对原论文中的分析过程做了一些精简、修正和推广,将结果记录成此文,供大家参考。此外,抛开问题背景不讲,读者也可以将本文当成一节矩阵分析习题课,供大家复习线性代数哈~

最近评论