






25
Jul
学会提问的BERT:端到端地从篇章中构建问答对
By 苏剑林 | 2020-07-25 | 116090位读者 | 引用机器阅读理解任务,相比不少读者都有所了解了,简单来说就是从给定篇章中寻找给定问题的答案,即“篇章 + 问题 → 答案”这样的流程,笔者之前也写过一些关于阅读理解的文章,比如《基于CNN的阅读理解式问答模型:DGCNN》等。至于问答对构建,则相当于是阅读理解的反任务,即“篇章 → 答案 + 问题”的流程,学术上一般直接叫“问题生成(Question Generation)”,因为大多数情况下,答案可以通过比较规则的随机选择,所以很多文章都只关心“篇章 + 答案 → 问题”这一步。
本文将带来一次全端到端的“篇章 → 答案 + 问题”实践,包括模型介绍以及基于bert4keras的实现代码,欢迎读者尝试。
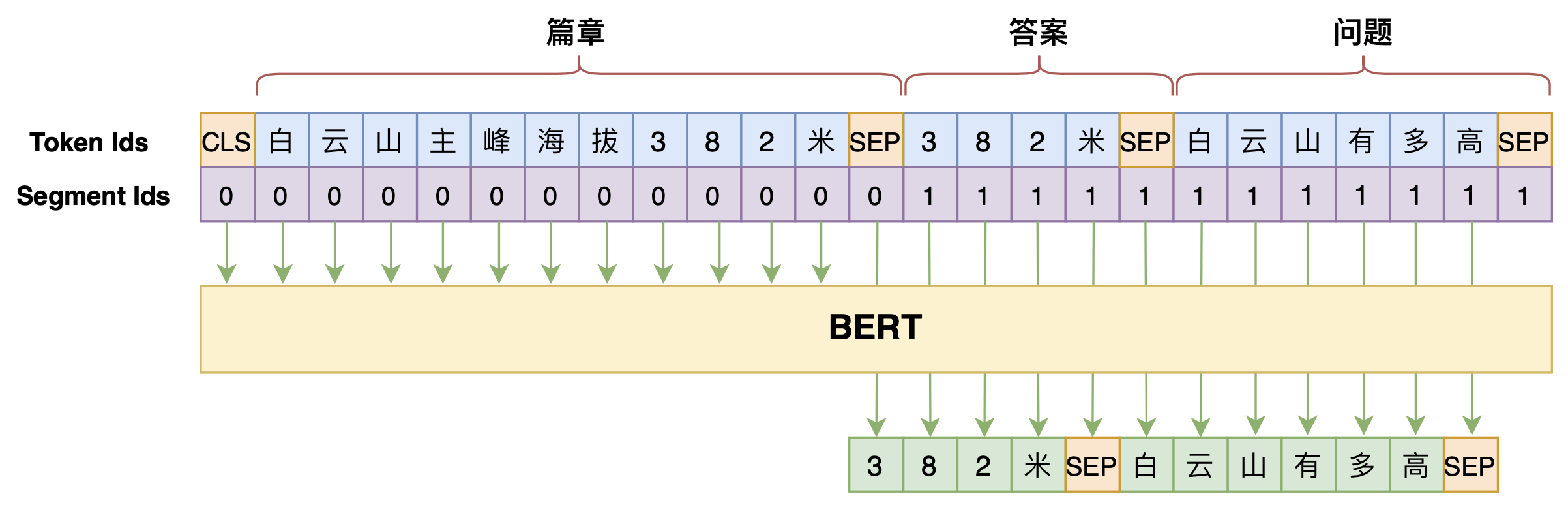
本文的问答生成模型示意图
9
Oct
“十字架”组合计数问题浅试
By 苏剑林 | 2022-10-09 | 20201位读者 | 引用
3
Apr
Bias项的神奇作用:RoPE + Bias = 更好的长度外推性
By 苏剑林 | 2023-04-03 | 42482位读者 | 引用万万没想到,Bias项能跟Transformer的长度外推性联系在一起!
长度外推性是我们希望Transformer具有的一个理想性质,笔者曾在《Transformer升级之路:7、长度外推性与局部注意力》、《Transformer升级之路:8、长度外推性与位置鲁棒性》系统地介绍过这一问题。至于Bias项(偏置项),目前的主流观点是当模型足够大时,Bias项不会有什么特别的作用,所以很多模型选择去掉Bias项,其中代表是Google的T5和PaLM,我们后面做的RoFormerV2和GAU-α也沿用了这个做法。
那么,这两个看上去“风牛马不相及”的东西,究竟是怎么联系起来的呢?Bias项真的可以增强Transformer的长度外推性?且听笔者慢慢道来。
20
Sep
自然数集中 N = ab + c 时 a + b + c 的最小值
By 苏剑林 | 2023-09-20 | 39196位读者 | 引用前天晚上微信群里有群友提出了一个问题:
对于一个任意整数$N > 100$,求一个近似算法,使得$N=a\times b+c$(其中$a,b,c$都是非负整数),并且令$a+b+c$尽量地小。
初看这道题,笔者第一感觉就是“这还需要算法?”,因为看上去自由度太大了,应该能求出个解析解才对,于是简单分析了一下之后就给出了个“答案”,结果很快就有群友给出了反例。这时,笔者才意识到这题并非那么平凡,随后正式推导了一番,总算得到了一个可行的算法。正当笔者以为这个问题已经结束时,另一个数学群的群友精妙地构造了新的参数化,证明了算法的复杂度还可以进一步下降!
整个过程波澜起伏,让笔者获益匪浅,遂将过程记录在此,与大家分享。
15
Aug
让MathJax更好地兼容谷歌翻译和延时加载
By 苏剑林 | 2024-08-15 | 17718位读者 | 引用很早之前,就有读者提出希望把Cool Papers上面的数学公式渲染一下,因为很多偏数学的论文,它们的摘要甚至标题上都带有LaTeX代码写的数学公式,如果不把这些公式渲染出来,那么看上去就像是一堆乱码,确实会比较影响阅读体验。然而,之前的测试显示,负责渲染公式的MathJax跟谷歌翻译和延时加载都不大兼容,所以尽管需求存在已久,但笔者一直没有把它加上去。
不过好消息是,经过反复查阅和调试,这两天笔者总算把兼容性问题解决了,所以现在大家看到的Cool Papers已经能够渲染数学公式了。这篇文章总结一下解决方案,供大家参考。

摘要带有公式的论文

最近评论