






2
Feb
更便捷的Cool Papers打开方式:Chrome重定向扩展
By 苏剑林 | 2024-02-02 | 47569位读者 | 引用一些铺垫
自Cool Papers上线以来,很多用户就建议笔者加入搜索功能,后面也确实在前端用JS简单做了个页面内搜索,解决了部分用户的需求,但仍有读者希望引入更完整的全局搜索。诚然,笔者理解这个需求确实是存在,但Cool Papers的数据是逐天累积的,目前才上线一个月,论文数并不多,建立一个大而全的搜索引擎意义不大,其次做搜索也不是笔者的强项,以及并没有很好的利用LLM优化搜索的思路,等等。总而言之,暂时没有条件实现一个全面而又有特色的搜索,所以不如不做(也欢迎大家在评论区集思广益)。
后来,经过和同事讨论,想出了一个“借花献佛”的思路——写一个Chrome的重定向扩展,可以从任意页面重定向到Cool Papers。这样我们可以用任意方式(如Google搜索或者直接Arxiv官方搜索)找到Arxiv上的论文,然后右击一下就转到Cool Papers了。前两周这个扩展已经在Chrome应用商店上线,上周服务器配合做了一些调整,如今大家可以尝试使用了。
7
May
Cool Papers更新:简单搭建了一个站内检索系统
By 苏剑林 | 2024-05-07 | 43031位读者 | 引用自从《更便捷的Cool Papers打开方式:Chrome重定向扩展》之后,Cool Papers有两次比较大的变化,一次是引入了venue分支,逐步收录了一些会议历年的论文集,如ICLR、ICML等,这部分是动态人工扩充的,欢迎有心仪的会议的读者提更多需求;另一次就是本文的主题,前天新增加的站内检索功能。
本文将简单介绍一下新增功能,并对搭建站内检索系统的过程做个基本总结。
简介
在Cool Papers的首页,我们看到搜索入口:

Cool Papers(2024.05.07)
17
Jul
【生活杂记】用电饭锅来煮米汤
By 苏剑林 | 2024-07-17 | 15268位读者 | 引用
6
Aug
通向最优分布之路:概率空间的最小化
By 苏剑林 | 2024-08-06 | 19651位读者 | 引用当要求函数的最小值时,我们通常会先求导函数然后寻找其零点,比较幸运的情况下,这些零点之一正好是原函数的最小值点。如果是向量函数,则将导数改为梯度并求其零点。当梯度零点不易求得时,我们可以使用梯度下降来逐渐逼近最小值点。
以上这些都是无约束优化的基础结果,相信不少读者都有所了解。然而,本文的主题是概率空间中的优化,即目标函数的输入是一个概率分布,这类目标的优化更为复杂,因为它的搜索空间不再是无约束的,如果我们依旧去求解梯度零点或者执行梯度下降,所得结果未必能保证是一个概率分布。因此,我们需要寻找一种新的分析和计算方法,以确保优化结果能够符合概率分布的特性。
对此,笔者一直以来也感到颇为头疼,所以近来决定”痛定思痛“,针对概率分布的优化问题系统学习了一番,最后将学习所得整理在此,供大家参考。
26
Sep
利用“熄火保护 + 通断器”实现燃气灶智能关火
By 苏剑林 | 2024-09-26 | 15598位读者 | 引用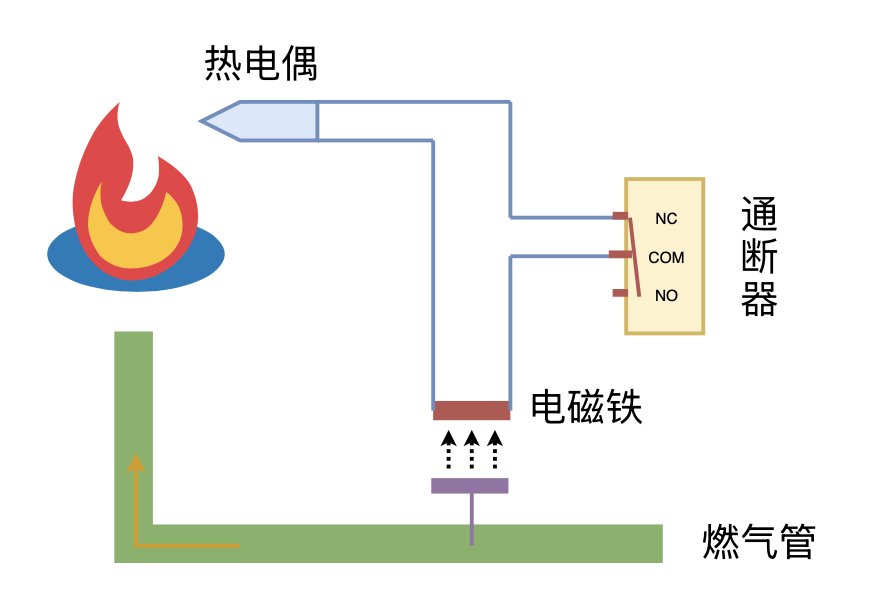
22
Nov
生成扩散模型漫谈(二十六):基于恒等式的蒸馏(下)
By 苏剑林 | 2024-11-22 | 15077位读者 | 引用继续回到我们的扩散系列。在《生成扩散模型漫谈(二十五):基于恒等式的蒸馏(上)》中,我们介绍了SiD(Score identity Distillation),这是一种不需要真实数据、也不需要从教师模型采样的扩散模型蒸馏方案,其形式类似GAN,但有着比GAN更好的训练稳定性。
SiD的核心是通过恒等变换来为学生模型构建更好的损失函数,这一点是开创性的,同时也遗留了一些问题。比如,SiD对损失函数的恒等变换是不完全的,如果完全变换会如何?如何从理论上解释SiD引入的$\lambda$的必要性?上个月放出的《Flow Generator Matching》(简称FGM)成功从更本质的梯度角度解释了$\lambda=0.5$的选择,而受到FGM启发,笔者则进一步发现了$\lambda = 1$的一种解释。
接下来我们将详细介绍SiD的上述理论进展。
18
Dec
生成扩散模型漫谈(二十八):分步理解一致性模型
By 苏剑林 | 2024-12-18 | 4881位读者 | 引用书接上文,在《生成扩散模型漫谈(二十七):将步长作为条件输入》中,我们介绍了加速采样的Shortcut模型,其对比的模型之一就是“一致性模型(Consistency Models)”。事实上,早在《生成扩散模型漫谈(十七):构建ODE的一般步骤(下)》介绍ReFlow时,就有读者提到了一致性模型,但笔者总感觉它更像是实践上的Trick,理论方面略显单薄,所以兴趣寥寥。
不过,既然我们开始关注扩散模型加速采样方面的进展,那么一致性模型就是一个绕不开的工作。因此,趁着这个机会,笔者在这里分享一下自己对一致性模型的理解。
熟悉配方
还是熟悉的配方,我们的出发点依旧是ReFlow,因为它大概是ODE式扩散最简单的理解方式。设$\boldsymbol{x}_0\sim p_0(\boldsymbol{x}_0)$是目标分布的真实样本,$\boldsymbol{x}_1\sim p_1(\boldsymbol{x}_1)$是先验分布的随机噪声,$\boldsymbol{x}_t = (1-t)\boldsymbol{x}_0 + t\boldsymbol{x}_1$是加噪样本,那么ReFlow的训练目标是:
14
Nov

最近评论