






11
Mar
【中文分词系列】 8. 更好的新词发现算法
By 苏剑林 | 2017-03-11 | 224222位读者 | 引用如果依次阅读该系列文章的读者,就会发现这个系列共提供了两种从0到1的无监督分词方案,第一种就是《【中文分词系列】 2. 基于切分的新词发现》,利用相邻字凝固度(互信息)来做构建词库(有了词库,就可以用词典法分词);另外一种是《【中文分词系列】 5. 基于语言模型的无监督分词》,后者基本上可以说是提供了一种完整的独立于其它文献的无监督分词方法。
但总的来看,总感觉前面一种很快很爽,却又显得粗糙;后面一种很好很强大,却又显得太过复杂(viterbi是瓶颈之一)。有没有可能在两者之间折中一下?这就导致了本文的结果,达到了速度与效果的平衡。至于为什么说“更好”?因为笔者研究词库构建也有一段时间了,以往构建的词库总不能让人(让自己)满意,生成的词库一眼看上去,都能够扫到不少不合理的地方,真的要用得需要经过较多的人工筛选。而这一次,一次性生成的词库,一眼扫过去,不合理的地方少了很多,如果不细看,可能就发现不了了。
分词的目的
14
Mar
泰迪杯赛前培训之数据挖掘与建模“慢谈”
By 苏剑林 | 2017-03-14 | 31786位读者 | 引用
泰迪杯赛前培训
应广州泰迪科技公司之邀,给泰迪杯数据挖掘竞赛录制了赛前培训视频,内容基本上是各种常见的数学模型及入门用法,以一种比较独特的思路,将朴素贝叶斯、HMM、逻辑回归、组合模型、神经网络、深度学习等等串了起来。视频讲解难度为入门级,当然,真的要融合贯通所有内容,恐怕要骨灰级。
不管怎么样,简单分享一下,欢迎大家留言讨论、建议甚至批评。
PPT下载:泰迪杯赛前培训ppt.zip
23
Mar
梯度下降和EM算法:系出同源,一脉相承
By 苏剑林 | 2017-03-23 | 206840位读者 | 引用PS:本文就是梳理了梯度下降与EM算法的关系,通过同一种思路,推导了普通的梯度下降法、pLSA中的EM算法、K-Means中的EM算法,以此表明它们基本都是同一个东西的不同方面,所谓“横看成岭侧成峰,远近高低各不同”罢了。
在机器学习中,通常都会将我们所要求解的问题表示为一个带有未知参数的损失函数(Loss),如平均平方误差(MSE),然后想办法求解这个函数的最小值,来得到最佳的参数值,从而完成建模。因将函数乘以-1后,最大值也就变成了最小值,因此一律归为最小值来说。如何求函数的最小值,在机器学习领域里,一般会流传两个大的方向:1、梯度下降;2、EM算法,也就是最大期望算法,一般用于复杂的最大似然问题的求解。
在通常的教程中,会将这两个方法描述得迥然不同,就像两大体系在分庭抗礼那样,而EM算法更是被描述得玄乎其玄的感觉。但事实上,这两个方法,都是同一个思路的不同例子而已,所谓“本是同根生”,它们就是一脉相承的东西。
让我们,先从远古的牛顿法谈起。
牛顿迭代法
给定一个复杂的非线性函数$f(x)$,希望求它的最小值,我们一般可以这样做,假定它足够光滑,那么它的最小值也就是它的极小值点,满足$f'(x_0)=0$,然后可以转化为求方程$f'(x)=0$的根了。非线性方程的根我们有个牛顿法,所以
\begin{equation}x_{n+1} = x_{n} - \frac{f'(x_n)}{f''(x_n)}\end{equation}
7
Apr
【不可思议的Word2Vec】 3.提取关键词
By 苏剑林 | 2017-04-07 | 196310位读者 | 引用本文主要是给出了关键词的一种新的定义,并且基于Word2Vec给出了一个实现方案。这种关键词的定义是自然的、合理的,Word2Vec只是一个简化版的实现方案,可以基于同样的定义,换用其他的模型来实现。
说到提取关键词,一般会想到TF-IDF和TextRank,大家是否想过,Word2Vec还可以用来提取关键词?而且,用Word2Vec提取关键词,已经初步含有了语义上的理解,而不仅仅是简单的统计了,而且还是无监督的!
什么是关键词?
诚然,TF-IDF和TextRank是两种提取关键词的很经典的算法,它们都有一定的合理性,但问题是,如果从来没看过这两个算法的读者,会感觉简直是异想天开的结果,估计很难能够从零把它们构造出来。也就是说,这两种算法虽然看上去简单,但并不容易想到。试想一下,没有学过信息相关理论的同学,估计怎么也难以理解为什么IDF要取一个对数?为什么不是其他函数?又有多少读者会破天荒地想到,用PageRank的思路,去判断一个词的重要性?
说到底,问题就在于:提取关键词和文本摘要,看上去都是一个很自然的任务,有谁真正思考过,关键词的定义是什么?这里不是要你去查汉语词典,获得一大堆文字的定义,而是问你数学上的定义。关键词在数学上的合理定义应该是什么?或者说,我们获取关键词的目的是什么?
4
May
记录一次半监督的情感分析
By 苏剑林 | 2017-05-04 | 51698位读者 | 引用本文是一次不怎么成功的半监督学习的尝试:在IMDB的数据集上,用随机抽取的1000个标注样本训练一个文本情感分类模型,并且在余下的49000个测试样本中,测试准确率为73.48%。
思路
本文的思路来源于OpenAI的这篇文章:
《OpenAI新研究发现无监督情感神经元:可直接调控生成文本的情感》
文章里边介绍了一种无监督(实际上是半监督)做情感分类的模型的方法,并且实验效果很好。然而文章里边的实验很庞大,对于个人来说几乎不可能重现(在4块Pascal GPU花了1个月时间训练)。不过,文章里边的思想是很简单的,根据里边的思想,我们可以做个“山寨版”的。思路如下:
我们一般用深度学习做情感分类,比较常规的思路就是Embedding层+LSTM层+Dense层(Sigmoid激活),我们常说的词向量,相当于预训练了Embedding层(这一层的参数量最大,最容易过拟合),而OpenAI的思想就是,为啥不连LSTM层一并预训练了呢?预训练的方法也是用语言模型来训练。当然,为了使得预训练的结果不至于丢失情感信息,LSTM的隐藏层节点要大一些。
8
Aug
【备忘】谈谈dropout
By 苏剑林 | 2017-08-08 | 32860位读者 | 引用其实这只是一篇备忘...
dropout是深度学习中防止过拟合的一项有效措施,当然,就其思想而言,dropout其实也不仅仅可以用在深度学习中,还可以用在传统的机器学习方法中,只不过在深度学习的神经网络框架下,dropout显得更为自然罢了。
做了什么
dropout是怎么操作的?一般来做,对于输入的张量$x$,dropout就是将部分元素置零,然后将置零后的结果做一个尺度变换。具体来说,以Keras的Dropout(0.6)(x)为例,实际上等价于numpy做的这件事情
import numpy as np
x = np.random.random((10,100)) #模拟一个batch_size=10、维度为100的输入
def Dropout(x, drop_proba):
return x*np.random.choice(
[0,1],
x.shape,
p=[drop_proba,1-drop_proba]
)/(1.-drop_proba)
print Dropout(x, 0.6)
23
Jan
揭开迷雾,来一顿美味的Capsule盛宴
By 苏剑林 | 2018-01-23 | 437152位读者 | 引用
Geoffrey Hinton在谷歌多伦多办公室
由深度学习先驱Hinton开源的Capsule论文《Dynamic Routing Between Capsules》,无疑是去年深度学习界最热点的消息之一。得益于各种媒体的各种吹捧,Capsule被冠以了各种神秘的色彩,诸如“抛弃了梯度下降”、“推倒深度学习重来”等字眼层出不穷,但也有人觉得Capsule不外乎是一个新的炒作概念。
本文试图揭开让人迷惘的云雾,领悟Capsule背后的原理和魅力,品尝这一顿Capsule盛宴。同时,笔者补做了一个自己设计的实验,这个实验能比原论文的实验更有力说明Capsule的确产生效果了。
菜谱一览:
1、Capsule是什么?
2、Capsule为什么要这样做?
3、Capsule真的好吗?
4、我觉得Capsule怎样?
5、若干小菜。
18
Mar
变分自编码器(一):原来是这么一回事
By 苏剑林 | 2018-03-18 | 947059位读者 | 引用过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西。于是趁着最近看概率图模型的三分钟热度,我决定也争取把VAE搞懂。于是乎照样翻了网上很多资料,无一例外发现都很含糊,主要的感觉是公式写了一大通,还是迷迷糊糊的,最后好不容易觉得看懂了,再去看看实现的代码,又感觉实现代码跟理论完全不是一回事啊。
终于,东拼西凑再加上我这段时间对概率模型的一些积累,并反复对比原论文《Auto-Encoding Variational Bayes》,最后我觉得我应该是想明白了。其实真正的VAE,跟很多教程说的的还真不大一样,很多教程写了一大通,都没有把模型的要点写出来~于是写了这篇东西,希望通过下面的文字,能把VAE初步讲清楚。
分布变换
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量$Z$生成目标数据$X$的模型,但是实现上有所不同。更准确地讲,它们是假设了$Z$服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型$X=g(Z)$,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
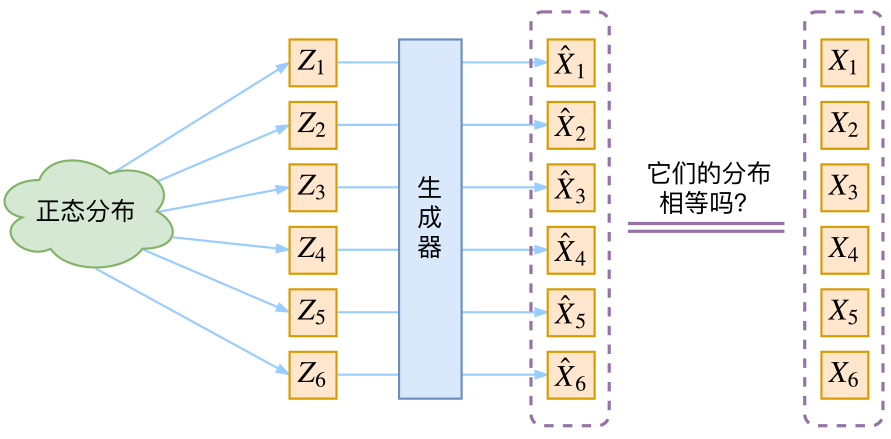
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式

最近评论