






14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 106290位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
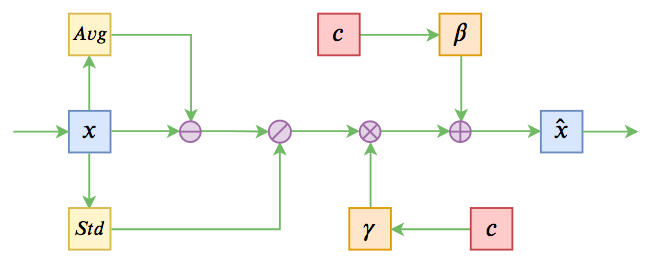
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。
10
Jul
强大的NVAE:以后再也不能说VAE生成的图像模糊了
By 苏剑林 | 2020-07-10 | 98953位读者 | 引用昨天早上,笔者在日常刷arixv的时候,然后被一篇新出来的论文震惊了!论文名字叫做《NVAE: A Deep Hierarchical Variational Autoencoder》,顾名思义是做VAE的改进工作的,提出了一个叫NVAE的新模型。说实话,笔者点进去的时候是不抱什么希望的,因为笔者也算是对VAE有一定的了解,觉得VAE在生成模型方面的能力终究是有限的。结果,论文打开了,呈现出来的画风是这样的:

NVAE的人脸生成效果
然后笔者的第一感觉是这样的:
W!T!F! 这真的是VAE生成的效果?这还是我认识的VAE么?看来我对VAE的认识还是太肤浅了啊,以后再也不能说VAE生成的图像模糊了...
1
Jan
SPACES:“抽取-生成”式长文本摘要(法研杯总结)
By 苏剑林 | 2021-01-01 | 215932位读者 | 引用“法研杯”算是近年来比较知名的NLP赛事之一,今年是第三届,包含四个赛道,其中有一个“司法摘要”赛道引起了我们的兴趣。经过了解,这是面向法律领域裁判文书的长文本摘要生成,这应该是国内第一个公开的长文本生成任务和数据集。过去一年多以来,我们在文本生成方面都有持续的投入和探索,所以决定选择该赛道作为检验我们研究成果的“试金石”。很幸运,我们最终以微弱的优势获得了该赛道的第一名。在此,我们对我们的比赛模型做一个总结和分享。

比赛榜单截图
在该比赛中,我们跳出了纯粹炼丹的过程,通过新型的Copy机制、Sparse Softmax等颇具通用性的新方法提升了模型的性能。整体而言,我们的模型比较简洁有效,而且可以做到端到端运行。窃以为我们的结果对工程和研究都有一定的参考价值。
31
Jan
幂等生成网络IGN:试图将判别和生成合二为一的GAN
By 苏剑林 | 2024-01-31 | 34078位读者 | 引用前段时间,一个名为“幂等生成网络(Idempotent Generative Network,IGN)”的生成模型引起了一定的关注。它自称是一种独立于已有的VAE、GAN、flow、Diffusion之外的新型生成模型,并且具有单步采样的特点。也许是大家苦于当前主流的扩散模型的多步采样生成过程久矣,因此任何声称可以实现单步采样的“风吹草动”都很容易吸引人们的关注。此外,IGN名称中的“幂等”一词也增加了它的神秘感,进一步扩大了人们的期待,也成功引起了笔者的兴趣,只不过之前一直有别的事情要忙,所以没来得及认真阅读模型细节。
最近闲了一点,想起来还有个IGN没读,于是重新把论文翻了出来,但阅读之后却颇感困惑:这哪里是个新模型,不就是个GAN的变种吗?跟常规GAN不同的是,它将生成器和判别器合二为一了。那这个“合二为一”是不是有什么特别的好处,比如训练更稳定?个人又感觉没有。下面将分享笔者从GAN角度理解IGN的过程和疑问。
生成对抗
关于GAN(Generative Adversarial Network,生成对抗网络),笔者前几年系统地学习过一段时间(查看GAN标签可以查看到相关文章),但近几年没有持续地关注了,因此这里先对GAN做个简单的回顾,也方便后续章节中我们对比GAN与IGN之间的异同。
15
Dec
两生物种群竞争模型:LaTeX+Python
By 苏剑林 | 2014-12-15 | 56569位读者 | 引用写在前面:本文是笔者数学建模课的作业,探讨了两生物种群竞争的常微分方程组模型的解的性质,展示了微分方程定性理论的基本思想。当然,本文最重要的目的,是展示LaTeX与Python的完美结合。(本文的图均由Python的Matplotlib模块生成;而文档则采用LaTeX编辑。)
问题提出
研究在同一个自然环境中生存的两个种群之间的竞争关系。假设两个种群独自在这个自然环境中生存时数量演变都服从Logistic规律,又假设当它们相互竞争时都会减慢对方数量的增长,增长速度的减小都与它们数量的乘积成正比。按照这样的假设建立的常微分方程模型为
$$\begin{equation}\label{eq:jingzhengfangcheng}\left\{\begin{aligned}\frac{dx_1}{dt}=r_1 x_1\left(1-\frac{x_1}{N_1}\right)-a_1 x_1 x_2 \\
\frac{dx_2}{dt}=r_2 x_2\left(1-\frac{x_2}{N_2}\right)-a_2 x_1 x_2\end{aligned}\right.\end{equation}$$
本文分别通过定量和定性两个角度来分析该方程的性质。
26
Jun
OCR技术浅探:7. 语言模型
By 苏剑林 | 2016-06-26 | 47463位读者 | 引用由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方法之一.
转移概率
在我们分析实验结果的过程中,有出现这一案例.由于图像不清晰等可能的原因,导致“电视”一词被识别为“电柳”,仅用图像模型是不能很好地解决这个问题的,因为从图像模型来看,识别为“电柳”是最优的选择.但是语言模型却可以很巧妙地解决这个问题.原因很简单,基于大量的文本数据我们可以统计“电视”一词和“电柳”一词的概率,可以发现“电视”一词的概率远远大于“电柳”,因此我们会认为这个词是“电视”而不是“电柳”.
从概率的角度来看,就是对于第一个字的区域的识别结果$s_1$,我们前面的卷积神经网络给出了“电”、“宙”两个候选字(仅仅选了前两个,后面的概率太小),每个候选字的概率$W(s_1)$分别为0.99996、0.00004;第二个字的区域的识别结果$s_2$,我们前面的卷积神经网络给出了“柳”、“视”、“规”(仅仅选了前三个,后面的概率太小),每个候选字的概率$W(s_2)$分别为0.87838、0.12148、0.00012,因此,它们事实上有六种组合:“电柳”、“电视”、“电规”、“宙柳”、“宙视”、“宙规”.
12
Sep
【中文分词系列】 5. 基于语言模型的无监督分词
By 苏剑林 | 2016-09-12 | 142157位读者 | 引用迄今为止,前四篇文章已经介绍了分词的若干思路,其中有基于最大概率的查词典方法、基于HMM或LSTM的字标注方法等。这些都是已有的研究方法了,笔者所做的就只是总结工作而已。查词典方法和字标注各有各的好处,我一直在想,能不能给出一种只需要大规模语料来训练的无监督分词模型呢?也就是说,怎么切分,应该是由语料来决定的,跟语言本身没关系。说白了,只要足够多语料,就可以告诉我们怎么分词。
看上去很完美,可是怎么做到呢?《2.基于切分的新词发现》中提供了一种思路,但是不够彻底。那里居于切分的新词发现方法确实可以看成一种无监督分词思路,它就是用一个简单的凝固度来判断某处该不该切分。但从分词的角度来看,这样的分词系统未免太过粗糙了。因此,我一直想着怎么提高这个精度,前期得到了一些有意义的结果,但都没有得到一个完整的理论。而最近正好把这个思路补全了。因为没有查找到类似的工作,所以这算是笔者在分词方面的一点原创工作了。
语言模型
首先简单谈一下语言模型。
19
Nov
更别致的词向量模型(四):模型的求解
By 苏剑林 | 2017-11-19 | 49015位读者 | 引用损失函数
现在,我们来定义loss,以便把各个词向量求解出来。用$\tilde{P}$表示$P$的频率估计值,那么我们可以直接以下式为loss
\[\sum_{w_i,w_j}\left(\langle \boldsymbol{v}_i, \boldsymbol{v}_j\rangle-\log\frac{\tilde{P}(w_i,w_j)}{\tilde{P}(w_i)\tilde{P}(w_j)}\right)^2\tag{16}\]
相比之下,无论在参数量还是模型形式上,这个做法都比glove要简单,因此称之为simpler glove。glove模型是
\[\sum_{w_i,w_j}\left(\langle \boldsymbol{v}_i, \boldsymbol{\hat{v}}_j\rangle+b_i+\hat{b}_j-\log X_{ij}\right)^2\tag{17}\]
在glove模型中,对中心词向量和上下文向量做了区分,然后最后模型建议输出的是两套词向量的求和,据说这效果会更好,这是一个比较勉强的trick,但也不是什么毛病。
\[\begin{aligned}&\sum_{w_i,w_j}\left(\langle \boldsymbol{v}_i, \boldsymbol{\hat{v}}_j\rangle+b_i+\hat{b}_j-\log \tilde{P}(w_i,w_j)\right)^2\\
=&\sum_{w_i,w_j}\left[\langle \boldsymbol{v}_i+\boldsymbol{c}, \boldsymbol{\hat{v}}_j+\boldsymbol{c}\rangle+\Big(b_i-\langle \boldsymbol{v}_i, \boldsymbol{c}\rangle - \frac{|\boldsymbol{c}|^2}{2}\Big)\right.\\
&\qquad\qquad\qquad\qquad\left.+\Big(\hat{b}_j-\langle \boldsymbol{\hat{v}}_j, \boldsymbol{c}\rangle - \frac{|\boldsymbol{c}|^2}{2}\Big)-\log X_{ij}\right]^2\end{aligned}\tag{18}\]
这就是说,如果你有了一组解,那么你将所有词向量加上任意一个常数向量后,它还是一组解!这个问题就严重了,我们无法预估得到的是哪组解,一旦加上的是一个非常大的常向量,那么各种度量都没意义了(比如任意两个词的cos值都接近1)。事实上,对glove生成的词向量进行验算就可以发现,glove生成的词向量,停用词的模长远大于一般词的模长,也就是说一堆词放在一起时,停用词的作用还明显些,这显然是不利用后续模型的优化的。(虽然从目前的关于glove的实验结果来看,是我强迫症了一些。)

最近评论