






16
Jul
“让Keras更酷一些!”:层中层与mask
By 苏剑林 | 2019-07-16 | 138717位读者 | 引用这一篇“让Keras更酷一些!”将和读者分享两部分内容:第一部分是“层中层”,顾名思义,是在Keras中自定义层的时候,重用已有的层,这将大大减少自定义层的代码量;另外一部分就是应读者所求,介绍一下序列模型中的mask原理和方法。
层中层
在《“让Keras更酷一些!”:精巧的层与花式的回调》一文中我们已经介绍过Keras自定义层的基本方法,其核心步骤是定义build和call两个函数,其中build负责创建可训练的权重,而call则定义具体的运算。
拒绝重复劳动
经常用到自定义层的读者可能会感觉到,在自定义层的时候我们经常在重复劳动,比如我们想要增加一个线性变换,那就要在build中增加一个kernel和bias变量(还要自定义变量的初始化、正则化等),然后在call里边用K.dot来执行,有时候还需要考虑维度对齐的问题,步骤比较繁琐。但事实上,一个线性变换其实就是一个不加激活函数的Dense层罢了,如果在自定义层时能重用已有的层,那显然就可以大大节省代码量了。
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 78386位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
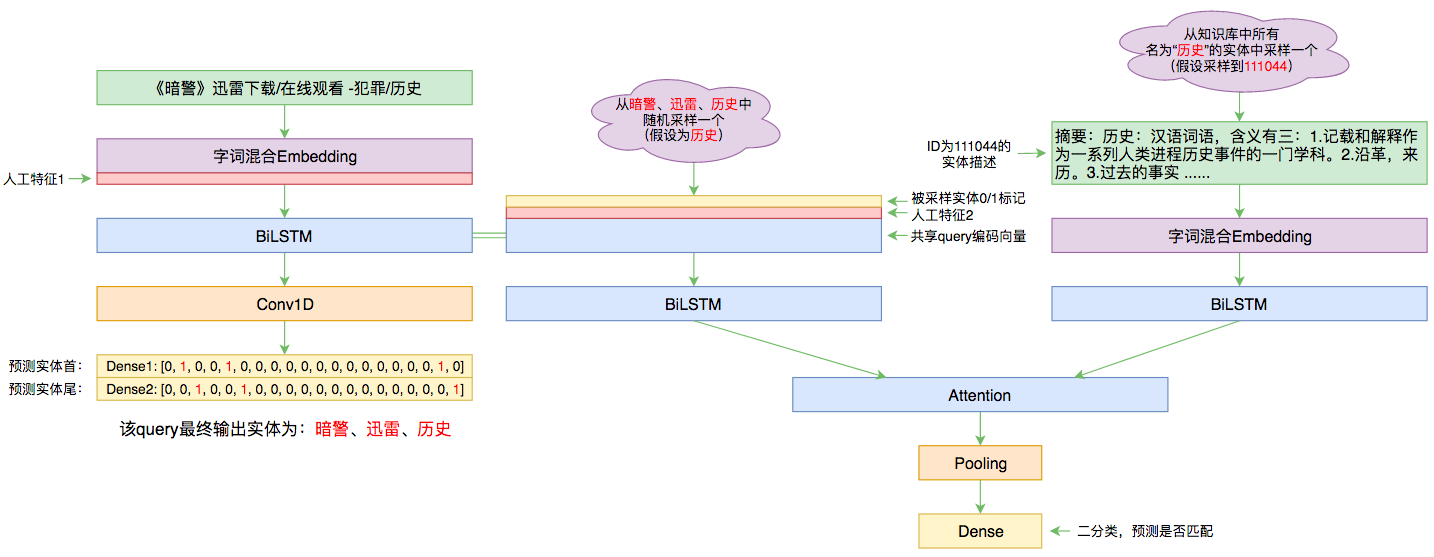
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
9
Sep
重新写了之前的新词发现算法:更快更好的新词发现
By 苏剑林 | 2019-09-09 | 91222位读者 | 引用新词发现是NLP的基础任务之一,主要是希望通过无监督发掘一些语言特征(主要是统计特征),来判断一批语料中哪些字符片段可能是一个新词。本站也多次围绕“新词发现”这个话题写过文章,比如:
在这些文章之中,笔者觉得理论最漂亮的是《基于语言模型的无监督分词》,而作为新词发现算法来说综合性能比较好的应该是《更好的新词发现算法》,本文就是复现这篇文章的新词发现算法。
24
Feb
CRF用过了,不妨再了解下更快的MEMM?
By 苏剑林 | 2020-02-24 | 45193位读者 | 引用HMM、MEMM、CRF被称为是三大经典概率图模型,在深度学习之前的机器学习时代,它们被广泛用于各种序列标注相关的任务中。一个有趣的现象是,到了深度学习时代,HMM和MEMM似乎都“没落”了,舞台上就只留下CRF。相信做NLP的读者朋友们就算没亲自做过也会听说过BiLSTM+CRF做中文分词、命名实体识别等任务,却几乎没有听说过BiLSTM+HMM、BiLSTM+MEMM的,这是为什么呢?
今天就让我们来学习一番MEMM,并且通过与CRF的对比,来让我们更深刻地理解概率图模型的思想与设计。
模型推导
MEMM全称Maximum Entropy Markov Model,中文名可译为“最大熵马尔可夫模型”。不得不说,这个名字可能会吓退80%的初学者:最大熵还没搞懂,马尔可夫也不认识,这两个合起来怕不是天书?而事实上,不管是MEMM还是CRF,它们的模型都远比它们的名字来得简单,它们的概念和设计都非常朴素自然,并不难理解。
25
May
Google新作Synthesizer:我们还不够了解自注意力
By 苏剑林 | 2020-05-25 | 81103位读者 | 引用深度学习这个箱子,远比我们想象的要黑。
写在开头
据说物理学家费曼说过一句话[来源]:“谁要是说他懂得量子力学,那他就是真的不懂量子力学。”我现在越来越觉得,这句话中的“量子力学”也可以替换为“深度学习”。尽管深度学习已经在越来越多的领域证明了其有效性,但我们对它的解释性依然相当无力。当然,这几年来已经有不少工作致力于打开深度学习这个黑箱,但是很无奈,这些工作基本都是“马后炮”式的,也就是在已有的实验结果基础上提出一些勉强能说服自己的解释,无法做到自上而下的构建和理解模型的原理,更不用说提出一些前瞻性的预测。
本文关注的是自注意力机制。直观上来看,自注意力机制算是解释性比较强的模型之一了,它通过自己与自己的Attention来自动捕捉了token与token之间的关联,事实上在《Attention is All You Need》那篇论文中,就给出了如下的看上去挺合理的可视化效果:
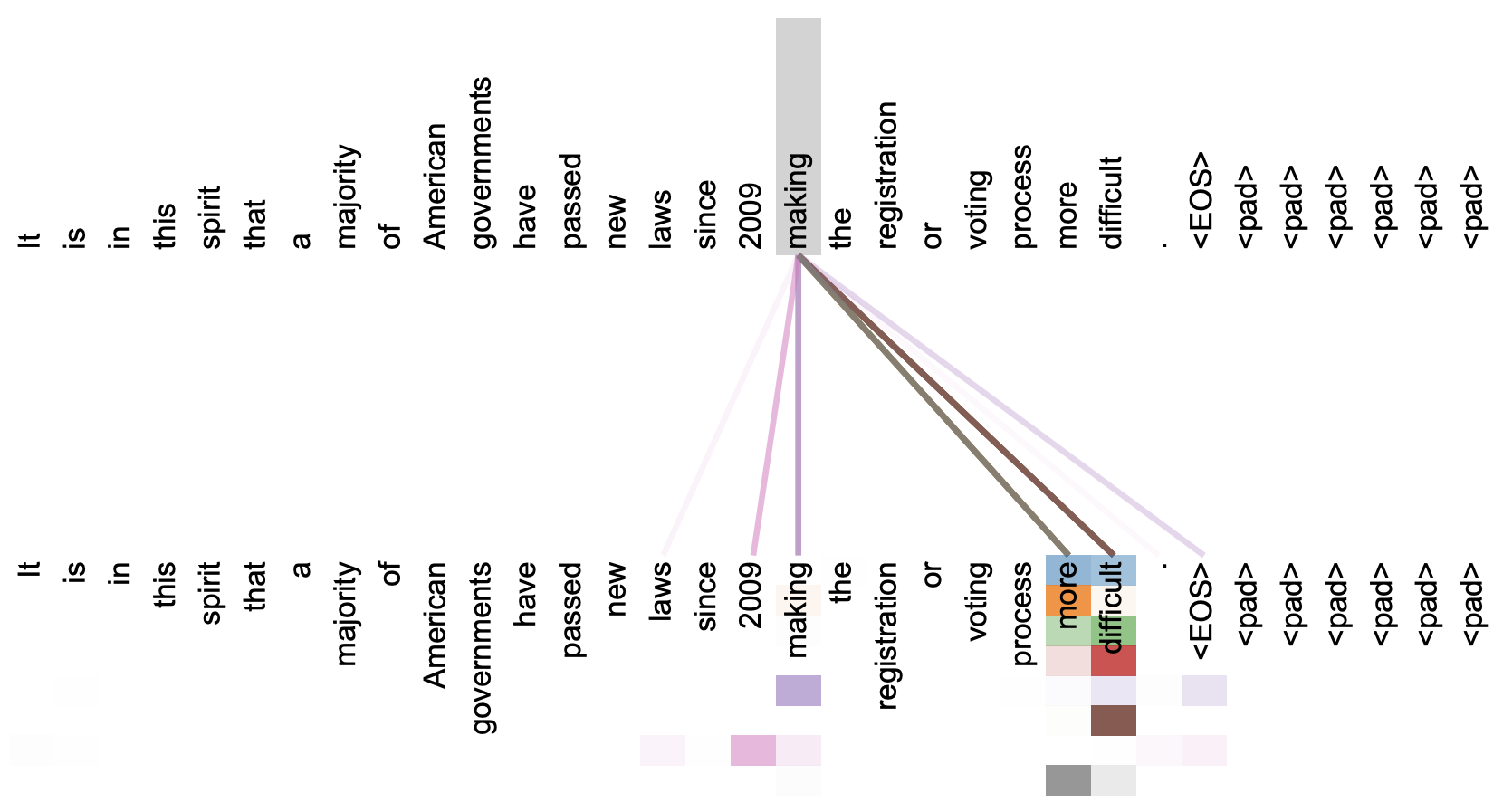
《Attention is All You Need》一文中对Attention的可视化例子
但自注意力机制真的是这样生效的吗?这种“token对token”的注意力是必须的吗?前不久Google的新论文《Synthesizer: Rethinking Self-Attention in Transformer Models》对自注意力机制做了一些“异想天开”的探索,里边的结果也许会颠覆我们对自注意力的认知。
23
Jun
从采样看优化:可导优化与不可导优化的统一视角
By 苏剑林 | 2020-06-23 | 50852位读者 | 引用不少读者都应该知道,损失函数与评测指标的不一致性是机器学习的典型现象之一,比如分类问题中损失函数用交叉熵,评测指标则是准确率或者F1,又比如文本生成中损失函数是teacher-forcing形式的交叉熵,评测指标则是BLEU、ROUGE等。理想情况下,当然是评测什么指标,我们就去优化这个指标,然而评测指标通常都是不可导的,而我们多数都是使用基于梯度的优化器,这就要求最小化的目标必须是可导的,这是不一致性的来源。
前些天在arxiv刷到了一篇名为《MLE-guided parameter search for task loss minimization in neural sequence modeling》的论文,顾名思义,它是研究如何直接优化文本生成的评测指标的。经过阅读,笔者发现这篇论文很有价值,事实上它提供了一种优化评测指标的新思路,适用范围并不局限于文本生成中。不仅如此,它甚至还包含了一种理解可导优化与不可导优化的统一视角。
采样视角
首先,我们可以通过采样的视角来重新看待优化问题:设模型当前参数为$\theta$,优化目标为$l(\theta)$,我们希望决定下一步的更新量$\Delta\theta$,为此,我们先构建分布
\begin{equation}p(\Delta\theta|\theta)=\frac{e^{-[l(\theta + \Delta\theta) - l(\theta)]/\alpha}}{Z(\theta)},\quad Z(\theta) = \int e^{-[l(\theta + \Delta\theta) - l(\theta)]/\alpha} d(\Delta\theta)\end{equation}
4
Jul
线性Attention的探索:Attention必须有个Softmax吗?
By 苏剑林 | 2020-07-04 | 197354位读者 | 引用众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是$\mathcal{O}(n^2)$级别的,$n$是序列长度,所以当$n$比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到$\mathcal{O}(n\log n)$甚至$\mathcal{O}(n)$。
前几天笔者读到了论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》,了解到了线性化Attention(Linear Attention)这个探索点,继而阅读了一些相关文献,有一些不错的收获,最后将自己对线性化Attention的理解汇总在此文中。
Attention
当前最流行的Attention机制当属Scaled-Dot Attention,形式为
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\label{eq:std-att}\end{equation}
这里的$\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}$,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设$\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}$,一般场景下都有$n > d$甚至$n\gg d$(BERT base里边$d=64$)。
16
Apr
搜狐文本匹配:基于条件LayerNorm的多任务baseline
By 苏剑林 | 2021-04-16 | 80159位读者 | 引用前段时间看到了“2021搜狐校园文本匹配算法大赛”,觉得赛题颇有意思,便尝试了一下,不过由于比赛本身只是面向在校学生,所以笔者是不能作为正式参赛人员参赛的,因此把自己的做法开源出来,作为比赛baseline供大家参考。
赛题介绍
顾名思义,比赛的任务是文本匹配,即判断两个文本是否相似,本来是比较常规的任务,但有意思的是它分了多个子任务。具体来说,它分A、B两大类,A类匹配标准宽松一些,B类匹配标准严格一些,然后每个大类下又分为“短短匹配”、“短长匹配”、“长长匹配”3个小类,因此,虽然任务类型相同,但严格来看它是六个不同的子任务。

最近评论