






6
Sep
“闭门造车”之多模态思路浅谈(三):位置编码
By 苏剑林 | 2024-09-06 | 42734位读者 | 引用在前面的文章中,我们曾表达过这样的观点:多模态LLM相比纯文本LLM的主要差异在于,前者甚至还没有形成一个公认为标准的方法论。这里的方法论,不仅包括之前讨论的生成和训练策略,还包括一些基础架构的设计,比如本文要谈的“多模态位置编码”。
对于这个主题,我们之前在《Transformer升级之路:17、多模态位置编码的简单思考》就已经讨论过一遍,并且提出了一个方案(RoPE-Tie)。然而,当时笔者对这个问题的思考仅处于起步阶段,存在细节考虑不周全、认识不够到位等问题,所以站在现在的角度回看,当时所提的方案与完美答案还有明显的距离。
因此,本文我们将自上而下地再次梳理这个问题,并且给出一个自认为更加理想的结果。
多模位置
多模态模型居然连位置编码都没有形成共识,这一点可能会让很多读者意外,但事实上确实如此。对于文本LLM,目前主流的位置编码是RoPE(RoPE就不展开介绍了,假设读者已经熟知),更准确来说是RoPE-1D,因为原始设计只适用于1D序列。后来我们推导了RoPE-2D,这可以用于图像等2D序列,按照RoPE-2D的思路我们可以平行地推广到RoPE-3D,用于视频等3D序列。
1
Sep
Decoder-only的LLM为什么需要位置编码?
By 苏剑林 | 2024-09-01 | 31976位读者 | 引用众所周知,目前主流的LLM,都是基于Causal Attention的Decoder-only模型(对此我们在《为什么现在的LLM都是Decoder-only的架构?》也有过相关讨论),而对于Causal Attention,已经有不少工作表明它不需要额外的位置编码(简称NoPE)就可以取得非平凡的结果。然而,事实是主流的Decoder-only LLM都还是加上了额外的位置编码,比如RoPE、ALIBI等。
那么问题就来了:明明说了不加位置编码也可以,为什么主流的LLM反而都加上了呢?不是说“多一事不如少一事”吗?这篇文章我们从三个角度给出笔者的看法:
1、位置编码对于Attention的作用是什么?
2、NoPE的Causal Attention是怎么实现位置编码的?
3、NoPE实现的位置编码有什么不足?
14
Nov
当Batch Size增大时,学习率该如何随之变化?
By 苏剑林 | 2024-11-14 | 21846位读者 | 引用随着算力的飞速进步,有越多越多的场景希望能够实现“算力换时间”,即通过堆砌算力来缩短模型训练时间。理想情况下,我们希望投入$n$倍的算力,那么达到同样效果的时间则缩短为$1/n$,此时总的算力成本是一致的。这个“希望”看上去很合理和自然,但实际上并不平凡,即便我们不考虑通信之类的瓶颈,当算力超过一定规模或者模型小于一定规模时,增加算力往往只能增大Batch Size。然而,增大Batch Size一定可以缩短训练时间并保持效果不变吗?
这就是接下来我们要讨论的话题:当Batch Size增大时,各种超参数尤其是学习率该如何调整,才能保持原本的训练效果并最大化训练效率?我们也可以称之为Batch Size与学习率之间的Scaling Law。
方差视角
直觉上,当Batch Size增大时,每个Batch的梯度将会更准,所以步子就可以迈大一点,也就是增大学习率,以求更快达到终点,缩短训练时间,这一点大体上都能想到。问题就是,增大多少才是最合适的呢?
29
Nov
从Hessian近似看自适应学习率优化器
By 苏剑林 | 2024-11-29 | 9862位读者 | 引用这几天在重温去年的Meta的一篇论文《A Theory on Adam Instability in Large-Scale Machine Learning》,里边给出了看待Adam等自适应学习率优化器的新视角:它指出梯度平方的滑动平均某种程度上近似于在估计Hessian矩阵的平方,从而Adam、RMSprop等优化器实际上近似于二阶的Newton法。
这个角度颇为新颖,而且表面上跟以往的一些Hessian近似有明显的差异,因此值得我们去学习和思考一番。
牛顿下降
设损失函数为$\mathcal{L}(\boldsymbol{\theta})$,其中待优化参数为$\boldsymbol{\theta}$,我们的优化目标是
\begin{equation}\boldsymbol{\theta}^* = \mathop{\text{argmin}}_{\boldsymbol{\theta}} \mathcal{L}(\boldsymbol{\theta})\label{eq:loss}\end{equation}
假设$\boldsymbol{\theta}$的当前值是$\boldsymbol{\theta}_t$,Newton法通过将损失函数展开到二阶来寻求$\boldsymbol{\theta}_{t+1}$:
\begin{equation}\mathcal{L}(\boldsymbol{\theta})\approx \mathcal{L}(\boldsymbol{\theta}_t) + \boldsymbol{g}_t^{\top}(\boldsymbol{\theta} - \boldsymbol{\theta}_t) + \frac{1}{2}(\boldsymbol{\theta} - \boldsymbol{\theta}_t)^{\top}\boldsymbol{\mathcal{H}}_t(\boldsymbol{\theta} - \boldsymbol{\theta}_t)\end{equation}
6
Nov
VQ的又一技巧:给编码表加一个线性变换
By 苏剑林 | 2024-11-06 | 20734位读者 | 引用在《VQ的旋转技巧:梯度直通估计的一般推广》中,我们介绍了VQ(Vector Quantization)的Rotation Trick,它的思想是通过推广VQ的STE(Straight-Through Estimator)来为VQ设计更好的梯度,从而缓解VQ的编码表坍缩、编码表利用率低等问题。
无独有偶,昨天发布在arXiv上的论文《Addressing Representation Collapse in Vector Quantized Models with One Linear Layer》提出了改善VQ的另一个技巧:给编码表加一个线性变换。这个技巧单纯改变了编码表的参数化方式,不改变VQ背后的理论框架,但实测效果非常优异,称得上是简单有效的经典案例。
18
Nov
Adam的epsilon如何影响学习率的Scaling Law?
By 苏剑林 | 2024-11-18 | 13601位读者 | 引用上一篇文章《当Batch Size增大时,学习率该如何随之变化?》我们从多个角度讨论了学习率与Batch Size之间的缩放规律,其中对于Adam优化器我们采用了SignSGD近似,这是分析Adam优化器常用的手段。那么一个很自然的问题就是:用SignSGD来近似Adam究竟有多科学呢?
我们知道,Adam优化器的更新量分母会带有一个$\epsilon$,初衷是预防除零错误,所以其值通常很接近于零,以至于我们做理论分析的时候通常选择忽略掉它。然而,当前LLM的训练尤其是低精度训练,我们往往会选择偏大的$\epsilon$,这导致在训练的中、后期$\epsilon$往往已经超过梯度平方大小,所以$\epsilon$的存在事实上已经不可忽略。
因此,这篇文章我们试图探索$\epsilon$如何影响Adam的学习率与Batch Size的Scaling Law,为相关问题提供一个参考的计算方案。
10
Dec
Muon优化器赏析:从向量到矩阵的本质跨越
By 苏剑林 | 2024-12-10 | 8418位读者 | 引用随着LLM时代的到来,学术界对于优化器的研究热情似乎有所减退。这主要是因为目前主流的AdamW已经能够满足大多数需求,而如果对优化器“大动干戈”,那么需要巨大的验证成本。因此,当前优化器的变化,多数都只是工业界根据自己的训练经验来对AdamW打的一些小补丁。
不过,最近推特上一个名为“Muon”的优化器颇为热闹,它声称比AdamW更为高效,且并不只是在Adam基础上的“小打小闹”,而是体现了关于向量与矩阵差异的一些值得深思的原理。本文让我们一起赏析一番。
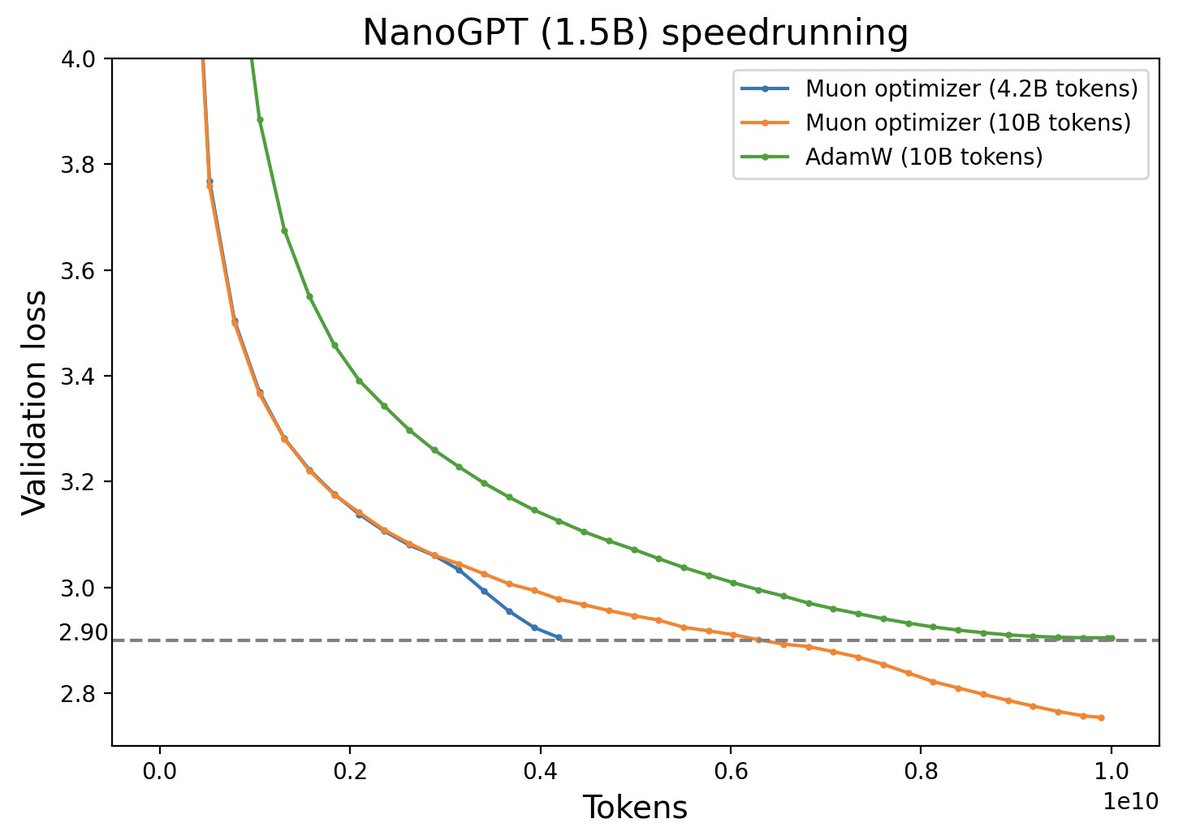
Muon与AdamW效果对比(来源:推特@Yuchenj_UW)
25
Dec
从谱范数梯度到新式权重衰减的思考
By 苏剑林 | 2024-12-25 | 1494位读者 | 引用在文章《Muon优化器赏析:从向量到矩阵的本质跨越》中,我们介绍了一个名为“Muon”的新优化器,其中一个理解视角是作为谱范数正则下的最速梯度下降,这似乎揭示了矩阵参数的更本质的优化方向。众所周知,对于矩阵参数我们经常也会加权重衰减(Weight Decay),它可以理解为$F$范数平方的梯度,那么从Muon的视角看,通过谱范数平方的梯度来构建新的权重衰减,会不会能起到更好的效果呢?
那么问题来了,谱范数的梯度或者说导数长啥样呢?用它来设计的新权重衰减又是什么样的?接下来我们围绕这些问题展开。
基础回顾
谱范数(Spectral Norm),又称“$2$范数”,是最常用的矩阵范数之一,相比更简单的$F$范数(Frobenius Norm),它往往能揭示一些与矩阵乘法相关的更本质的信号,这是因为它定义上就跟矩阵乘法相关:对于矩阵参数$\boldsymbol{W}\in\mathbb{R}^{n\times m}$,它的谱范数定义为

最近评论