






15
Nov
WGAN新方案:通过梯度归一化来实现L约束
By 苏剑林 | 2021-11-15 | 53736位读者 | 引用当前,WGAN主流的实现方式包括参数裁剪(Weight Clipping)、谱归一化(Spectral Normalization)、梯度惩罚(Gradient Penalty),本来则来介绍一种新的实现方案:梯度归一化(Gradient Normalization),该方案出自两篇有意思的论文,分别是《Gradient Normalization for Generative Adversarial Networks》和《GraN-GAN: Piecewise Gradient Normalization for Generative Adversarial Networks》。
有意思在什么地方呢?从标题可以看到,这两篇论文应该是高度重合的,甚至应该是同一作者的。但事实上,这是两篇不同团队的、大致是同一时期的论文,一篇中了ICCV,一篇中了WACV,它们基于同样的假设推出了几乎一样的解决方案,内容重合度之高让我一直以为是同一篇论文。果然是巧合无处不在啊~
17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 64864位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
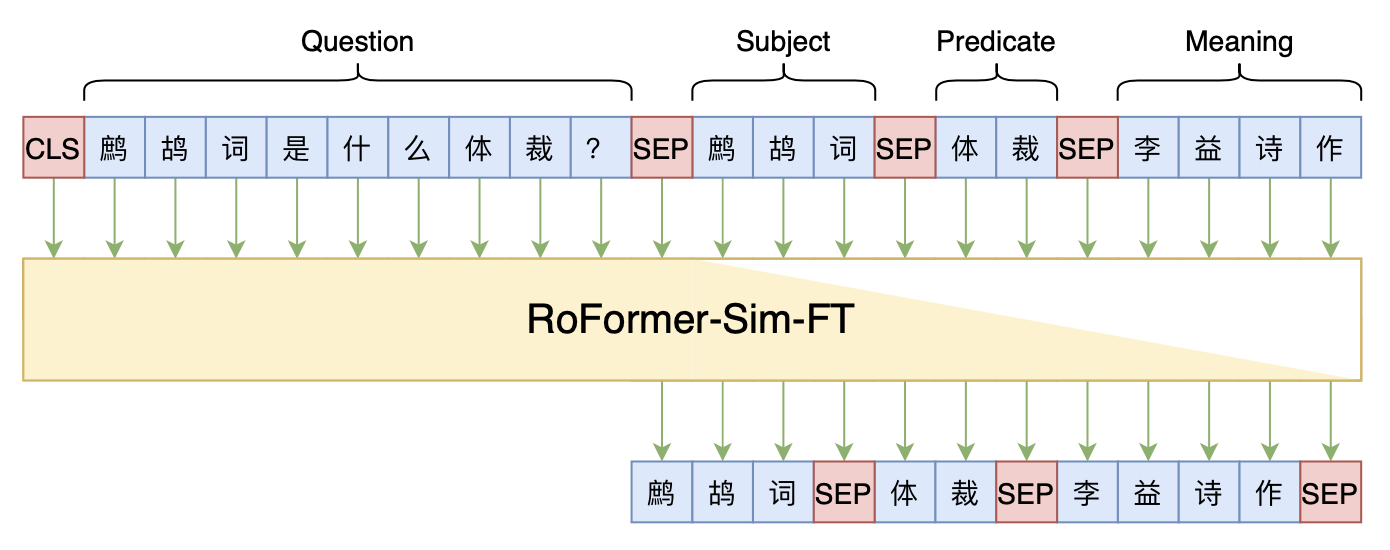
本文baseline模型示意图
15
Jul
不成功的尝试:将多标签交叉熵推广到“n个m分类”上去
By 苏剑林 | 2022-07-15 | 23743位读者 | 引用可能有读者留意到,这次更新相对来说隔得比较久了。事实上,在上周末时就开始准备这篇文章了,然而笔者低估了这个问题的难度,几乎推导了整整一周,仍然还没得到一个完善的结果出来。目前发出来的,仍然只是一个失败的结果,希望有经验的读者可以指点指点。
在文章《将“Softmax+交叉熵”推广到多标签分类问题》中,我们提出了一个多标签分类损失函数,它能自动调节正负类的不平衡问题,后来在《多标签“Softmax+交叉熵”的软标签版本》中我们还进一步得到了它的“软标签”版本。本质上来说,多标签分类就是“$n$个2分类”问题,那么相应的,“$n$个$m$分类”的损失函数又该是怎样的呢?
这就是本文所要探讨的问题。
6
Jul
生成扩散模型漫谈(二):DDPM = 自回归式VAE
By 苏剑林 | 2022-07-06 | 123097位读者 | 引用在文章《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中,我们为生成扩散模型DDPM构建了“拆楼-建楼”的通俗类比,并且借助该类比完整地推导了生成扩散模型DDPM的理论形式。在该文章中,我们还指出DDPM本质上已经不是传统的扩散模型了,它更多的是一个变分自编码器VAE,实际上DDPM的原论文中也是将它按照VAE的思路进行推导的。
所以,本文就从VAE的角度来重新介绍一版DDPM,同时分享一下自己的Keras实现代码和实践经验。
Github地址:https://github.com/bojone/Keras-DDPM
多步突破
在传统的VAE中,编码过程和生成过程都是一步到位的:
\begin{equation}\text{编码:}\,\,x\to z\,,\quad \text{生成:}\,\,z\to x\end{equation}
30
Aug
生成扩散模型漫谈(九):条件控制生成结果
By 苏剑林 | 2022-08-30 | 133499位读者 | 引用前面的几篇文章都是比较偏理论的结果,这篇文章我们来讨论一个比较有实用价值的主题——条件控制生成。
作为生成模型,扩散模型跟VAE、GAN、flow等模型的发展史很相似,都是先出来了无条件生成,然后有条件生成就紧接而来。无条件生成往往是为了探索效果上限,而有条件生成则更多是应用层面的内容,因为它可以实现根据我们的意愿来控制输出结果。从DDPM至今,已经出来了很多条件扩散模型的工作,甚至可以说真正带火了扩散模型的就是条件扩散模型,比如脍炙人口的文生图模型DALL·E 2、Imagen。
在这篇文章中,我们对条件扩散模型的理论基础做个简单的学习和总结。
技术分析
从方法上来看,条件控制生成的方式分两种:事后修改(Classifier-Guidance)和事前训练(Classifier-Free)。
30
Nov
用热传导方程来指导自监督学习
By 苏剑林 | 2022-11-30 | 29177位读者 | 引用用理论物理来卷机器学习已经不是什么新鲜事了,比如上个月介绍的《生成扩散模型漫谈(十三):从万有引力到扩散模型》就是经典一例。最近一篇新出的论文《Self-Supervised Learning based on Heat Equation》,顾名思义,用热传导方程来做(图像领域的)自监督学习,引起了笔者的兴趣。这种物理方程如何在机器学习中发挥作用?同样的思路能否迁移到NLP中?让我们一起来读读论文。
基本方程
如下图,左边是物理中热传导方程的解,右端则是CAM、积分梯度等显著性方法得到的归因热力图,可以看到两者有一定的相似之处,于是作者认为热传导方程可以作为好的视觉特征的一个重要先验。
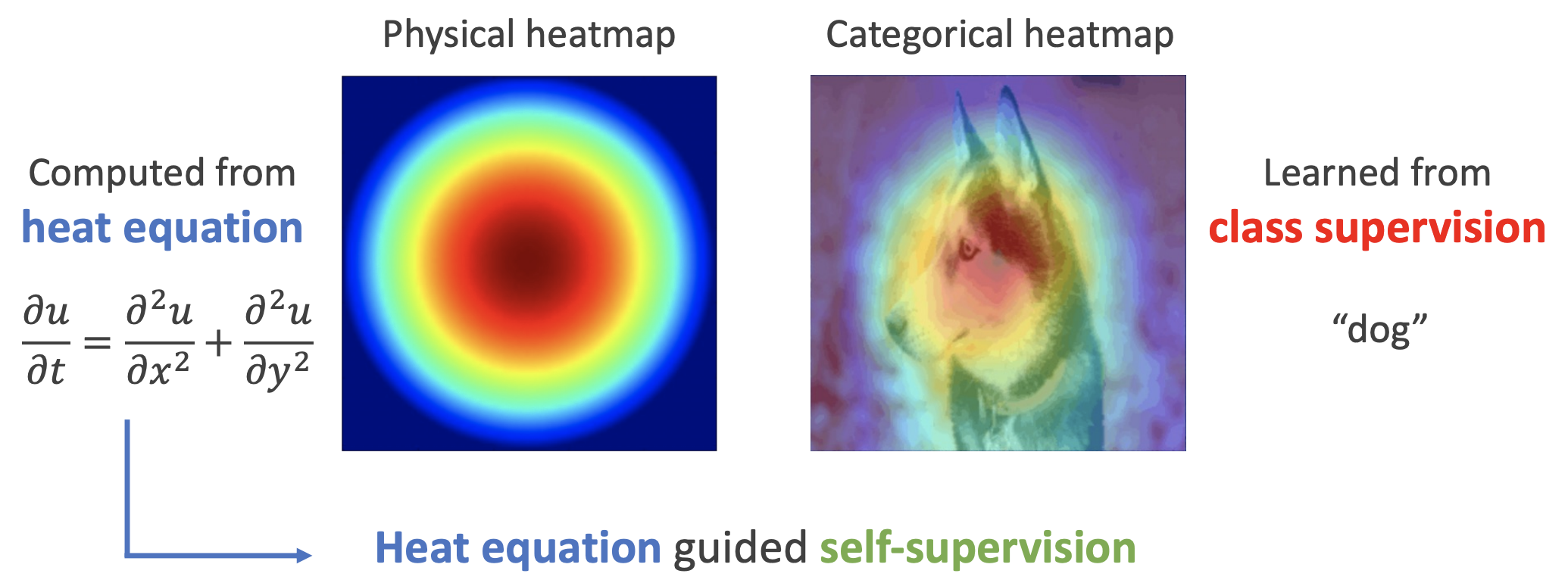
热方程的热力图(左)和视觉模型的热力图(右)
25
Dec
写了个刷论文的辅助网站:Cool Papers
By 苏剑林 | 2023-12-25 | 88801位读者 | 引用写在开头
一直以来,笔者都有日刷Arxiv的习惯,以求尽可能跟上领域内最新成果,并告诫自己“不进则退”。之前也有不少读者问我是怎么刷Arxiv的、有什么辅助工具等,但事实上,在很长的时间里,笔者都是直接刷Arxiv官网,并且没有用任何算法过滤,都是自己一篇篇过的。这个过程很枯燥,但并非不能接受,之所以不用算法初筛,主要还是担心算法漏召,毕竟“刷”就是为了追新,一旦算法漏召就“错失先机”了。
自从Kimi Chat发布后,笔者就一直计划着写一个辅助网站结合Kimi来加速刷论文的过程。最近几个星期稍微闲了一点,于是在GPT4、Kimi的帮助下,初步写成了这个网站,并且经过几天的测试和优化后,已经逐步趋于稳定,于是正式邀请读者试用。
Cool Papers:https://papers.cool
14
Jan
旁门左道之如何让Python的重试代码更加优雅
By 苏剑林 | 2024-01-14 | 37836位读者 | 引用这篇文章我们讨论一个编程题:如何更优雅地在Python中实现重试。
在文章《新年快乐!记录一下 Cool Papers 的开发体验》中,笔者分享了开发Cool Papers的一些经验,其中就提到了Cool Papers所需要的一些网络通信步骤。但凡涉及到网络通信,就有失败的风险(谁也无法保证网络不会间歇性抽风),所以重试是网络通信的基本操作。此外,当涉及到多进程、数据库、硬件交互等操作时,通常也需要引入重试机制。
在Python中,实现重试并不难,但如何更加简单而又不失可读性地实现重试,还是有一定技巧的。接下来笔者分享一下自己的尝试。
循环重试
完整的重试流程大致上包含循环重试、异常处理、延时等待、后续操作等部分,其标准写法就是用for循环,用“try ... except ...”来捕捉异常,一个参考代码是:

最近评论