






1
Dec
级联抑制:提升GAN表现的一种简单有效的方法
By 苏剑林 | 2019-12-01 | 34537位读者 | 引用昨天刷arxiv时发现了一篇来自星星韩国的论文,名字很直白,就叫做《A Simple yet Effective Way for Improving the Performance of GANs》。打开一看,发现内容也很简练,就是提出了一种加强GAN的判别器的方法,能让GAN的生成指标有一定的提升。
作者把这个方法叫做Cascading Rejection,我不知道咋翻译,扔到百度翻译里边显示“级联抑制”,想想看好像是有这么点味道,就暂时这样叫着了。介绍这个方法倒不是因为它有多强大,而是觉得它的几何意义很有趣,而且似乎有一定的启发性。
正交分解
GAN的判别器一般是经过多层卷积后,通过flatten或pool得到一个固定长度的向量$\boldsymbol{v}$,然后再与一个权重向量$\boldsymbol{w}$做内积,得到一个标量打分(先不考虑偏置项和激活函数等末节):
\begin{equation}D(\boldsymbol{x})=\langle \boldsymbol{v},\boldsymbol{w}\rangle\end{equation}
也就是说,用$\boldsymbol{v}$作为输入图片的表征,然后通过$\boldsymbol{v}$和$\boldsymbol{w}$的内积大小来判断出这个图片的“真”的程度。
10
May
能量视角下的GAN模型(三):生成模型=能量模型
By 苏剑林 | 2019-05-10 | 55711位读者 | 引用
本文的模型在ImageNet(128x128)上的条件生成效果
今天要介绍的结果还是跟能量模型相关,来自论文《Implicit Generation and Generalization in Energy-Based Models》。当然,它已经跟GAN没有什么关系了,但是跟本系列第二篇所介绍的能量模型关系较大,所以还是把它放到这个系列好了。
我当初留意到这篇论文,是因为机器之心的报导《MIT本科学神重启基于能量的生成模型,新框架堪比GAN》,但是说实在的,这篇文章没什么意思,说句不中听的,就是炒冷饭系列,媒体的标题也算中肯,是“重启”。这篇文章就是指出能量模型实际上就是某个特定的Langevin方程的静态解,然后就用这个Langevin方程来实现采样,有了采样过程也就可以完成能量模型的训练,这些理论都是现成的,所以这个过程我在学习随机微分方程的时候都想过,我相信很多人也都想过。因此,我觉得作者的贡献就是把这个直白的想法通过一系列炼丹技巧实现了。
但不管怎样,能训练出来也是一件很不错的事情,另外对于之前没了解过相关内容的读者来说,这确实也算是一个不错的能量模型案例,所以我论文的整体思路整理一下,让读者能够更全面地理解能量模型。
28
May
ON-LSTM:用有序神经元表达层次结构
By 苏剑林 | 2019-05-28 | 198723位读者 | 引用今天介绍一个有意思的LSTM变种:ON-LSTM,其中“ON”的全称是“Ordered Neurons”,即有序神经元,换句话说这种LSTM内部的神经元是经过特定排序的,从而能够表达更丰富的信息。ON-LSTM来自文章《Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks》,顾名思义,将神经元经过特定排序是为了将层级结构(树结构)整合到LSTM中去,从而允许LSTM能自动学习到层级结构信息。这篇论文还有另一个身份:ICLR 2019的两篇最佳论文之一,这表明在神经网络中融合层级结构(而不是纯粹简单地全向链接)是很多学者共同感兴趣的课题。
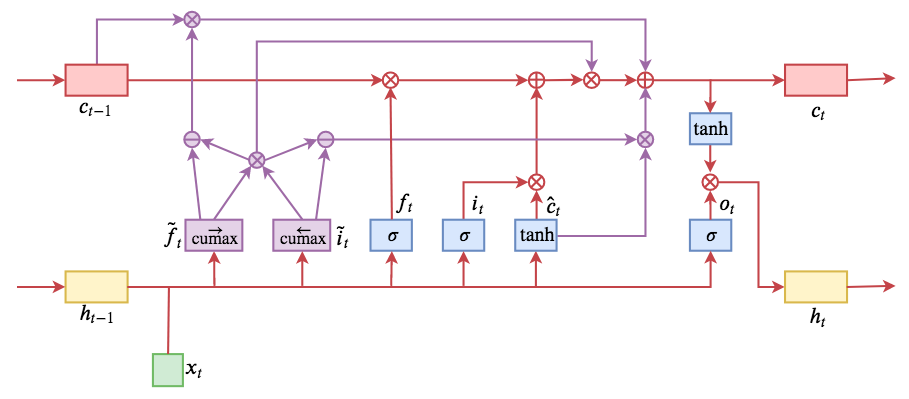
ON-LSTM运算流程示意图。主要是将分段函数用cumax光滑化变成可导。
笔者留意到ON-LSTM是因为机器之心的介绍,里边提到它除了提高了语言模型的效果之外,甚至还可以无监督地学习到句子的句法结构!正是这一点特性深深吸引了我,而它最近获得ICLR 2019最佳论文的认可,更是坚定了我要弄懂它的决心。认真研读、推导了差不多一星期之后,终于有点眉目了,遂写下此文。
在正式介绍ON-LSTM之后,我忍不住要先吐槽一下这篇文章实在是写得太差了,将一个明明很生动形象的设计,讲得异常晦涩难懂,其中的核心是$\tilde{f}_t$和$\tilde{i}_t$的定义,文中几乎没有任何铺垫就贴了出来,也没有多少诠释,开始的读了好几次仍然像天书一样...总之,文章写法实在不敢恭维~
3
Jun
基于DGCNN和概率图的轻量级信息抽取模型
By 苏剑林 | 2019-06-03 | 420291位读者 | 引用背景:前几个月,百度举办了“2019语言与智能技术竞赛”,其中有三个赛道,而我对其中的“信息抽取”赛道颇感兴趣,于是报名参加。经过两个多月的煎熬,比赛终于结束,并且最终结果已经公布。笔者从最初的对信息抽取的一无所知,经过这次比赛的学习和研究,最终探索出在监督学习下做信息抽取的一些经验,遂在此与大家分享。

信息抽取赛道:“科学空间队”在最终的测试结果上排名第七
笔者在最终的测试集上排名第七,指标F1为0.8807(Precision是0.8939,Recall是0.8679),跟第一名相差0.01左右。从比赛角度这个成绩不算突出,但自认为模型有若干创新之处,比如自行设计的抽取结构、CNN+Attention(所以足够快速)、没有用Bert等预训练模型,私以为这对于信息抽取的学术研究和工程应用都有一定的参考价值。
基本分析
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础,一直受到业界的广泛关注。... 本次竞赛将提供业界规模最大的基于schema的中文信息抽取数据集(Schema based Knowledge Extraction, SKE),旨在为研究者提供学术交流平台,进一步提升中文信息抽取技术的研究水平,推动相关人工智能应用的发展。------ 比赛官方网站介绍
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 137839位读者 | 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$三个向量序列的交互和融合,其中$\boldsymbol{Q},\boldsymbol{K}$的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把$\boldsymbol{V}$按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}
19
Oct
最小熵原理(五):“层层递进”之社区发现与聚类
By 苏剑林 | 2019-10-19 | 157222位读者 | 引用让我们不厌其烦地回顾一下:最小熵原理是一个无监督学习的原理,“熵”就是学习成本,而降低学习成本是我们的不懈追求,所以通过“最小化学习成本”就能够无监督地学习出很多符合我们认知的结果,这就是最小熵原理的基本理念。
这篇文章里,我们会介绍一种相当漂亮的聚类算法,它同样也体现了最小熵原理,或者说它可以通过最小熵原理导出来,名为InfoMap,或者MapEquation。事实上InfoMap已经是2007年的成果了,最早的论文是《Maps of random walks on complex networks reveal community structure》,虽然看起来很旧,但我认为它仍是当前最漂亮的聚类算法,因为它不仅告诉了我们“怎么聚类”,更重要的是给了我们一个“为什么要聚类”的优雅的信息论解释,并从这个解释中直接导出了整个聚类过程。
一个复杂有向图网络示意图。图片来自InfoMap最早的论文《Maps of random walks on complex networks reveal community structure》
当然,它的定位并不仅仅局限在聚类上,更准确地说,它是一种图网络上的“社区发现”算法。所谓社区发现(Community Detection),大概意思是给定一个有向/无向图网络,然后找出这个网络上的“抱团”情况,至于详细含义,大家可以自行搜索一下。简单来说,它跟聚类相似,但是比聚类的含义更丰富。(还可以参考《什么是社区发现?》)
29
Sep
“让Keras更酷一些!”:层与模型的重用技巧
By 苏剑林 | 2019-09-29 | 113594位读者 | 引用今天我们继续来深挖Keras,再次体验Keras那无与伦比的优雅设计。这一次我们的焦点是“重用”,主要是层与模型的重复使用。
所谓重用,一般就是奔着两个目标去:一是为了共享权重,也就是说要两个层不仅作用一样,还要共享权重,同步更新;二是避免重写代码,比如我们已经搭建好了一个模型,然后我们想拆解这个模型,构建一些子模型等。
基础
事实上,Keras已经为我们考虑好了很多,所以很多情况下,掌握好基本用法,就已经能满足我们很多需求了。
层的重用
层的重用是最简单的,将层初始化好,存起来,然后反复调用即可:
x_in = Input(shape=(784,))
x = x_in
layer = Dense(784, activation='relu') # 初始化一个层,并存起来
x = layer(x) # 第一次调用
x = layer(x) # 再次调用
x = layer(x) # 再次调用
25
Nov
6个派生优化器的简单介绍及其实现
By 苏剑林 | 2019-11-25 | 53393位读者 | 引用优化器可能是深度学习最“玄学”的一个模块之一了:有时候换一个优化器就能带来明显的提升,有时候别人说提升很多的优化器用到自己的任务上却一丁点用都没有,理论性质好的优化器不一定工作得很好,纯粹拍脑袋而来的优化器也未必就差了。但不管怎样,优化器终究也为热爱“深度炼丹”的同学提供了多一个选择。
近几年来,关于优化器的工作似乎也在慢慢增多,很多论文都提出了对常用优化器(尤其是Adam)的大大小小的改进。本文就汇总一些优化器工作或技巧,并统一给出了代码实现,供读者有需调用。
基本形式
所谓“派生”,就是指相关的技巧都是建立在已有的优化器上的,任意一个已有的优化器都可以用上这些技巧,从而变成一个新的优化器。
已有的优化器的基本形式为:
\begin{equation}\begin{aligned}\boldsymbol{g}_t =&\, \nabla_{\boldsymbol{\theta}} L\\
\boldsymbol{h}_t =&\, f(\boldsymbol{g}_{\leq t})\\
\boldsymbol{\theta}_{t+1} =&\, \boldsymbol{\theta}_t - \gamma \boldsymbol{h}_t
\end{aligned}\end{equation}
其中$\boldsymbol{g}_t$即梯度,而$\boldsymbol{g}_{\leq t}$指的是截止到当前步的所有梯度信息,它们经过某种运算$f$(比如累积动量、累积二阶矩校正学习率等)后得到$\boldsymbol{h}_t$,然后由$\boldsymbol{h}_t$来更新参数,这里的$\gamma$就是指学习率。

最近评论