






29
Sep
f-GAN简介:GAN模型的生产车间
By 苏剑林 | 2018-09-29 | 150984位读者 | 引用今天介绍一篇比较经典的工作,作者命名为f-GAN,他在文章中给出了通过一般的$f$散度来构造一般的GAN的方案。可以毫不夸张地说,这论文就是一个GAN模型的“生产车间”,它一般化的囊括了很多GAN变种,并且可以启发我们快速地构建新的GAN变种(当然有没有价值是另一回事,但理论上是这样)。
局部变分
整篇文章对$f$散度的处理事实上在机器学习中被称为“局部变分方法”,它是一种非常经典且有用的估算技巧。事实上本文将会花大部分篇幅介绍这种估算技巧在$f$散度中的应用结果。至于GAN,只不过是这个结果的基本应用而已。
f散度
首先我们还是对$f$散度进行基本的介绍。所谓$f$散度,是KL散度的一般化:
$$\begin{equation}\mathcal{D}_f(P\Vert Q) = \int q(x) f\left(\frac{p(x)}{q(x)}\right)dx\label{eq:f-div}\end{equation}$$
注意,按照通用的约定写法,括号内是$p/q$而不是$q/p$,大家不要自然而言地根据KL散度的形式以为是$q/p$。
27
Nov
从变分编码、信息瓶颈到正态分布:论遗忘的重要性
By 苏剑林 | 2018-11-27 | 154922位读者 | 引用这是一篇“散文”,我们来谈一下有着千丝万缕联系的三个东西:变分自编码器、信息瓶颈、正态分布。
众所周知,变分自编码器是一个很经典的生成模型,但实际上它有着超越生成模型的含义;而对于信息瓶颈,大家也许相对陌生一些,然而事实上信息瓶颈在去年也热闹了一阵子;至于正态分布,那就不用说了,它几乎跟所有机器学习领域都有或多或少的联系。
那么,当它们三个碰撞在一块时,又有什么样的故事可说呢?它们跟“遗忘”又有什么关系呢?
变分自编码器
在本博客你可以搜索到若干几篇介绍VAE的文章。下面简单回顾一下。
理论形式回顾
简单来说,VAE的优化目标是:
\begin{equation}KL(\tilde{p}(x)p(z|x)\Vert q(z)q(x|z))=\iint \tilde{p}(x)p(z|x)\log \frac{\tilde{p}(x)p(z|x)}{q(x|z)q(z)} dzdx\end{equation}
其中$q(z)$是标准正态分布,$p(z|x),q(x|z)$是条件正态分布,分别对应编码器、解码器。具体细节可以参考《变分自编码器(二):从贝叶斯观点出发》。
12
Jan
Self-Orthogonality Module:一个即插即用的核正交化模块
By 苏剑林 | 2020-01-12 | 52929位读者 | 引用前些天刷Arxiv看到新文章《Self-Orthogonality Module: A Network Architecture Plug-in for Learning Orthogonal Filters》(下面简称“原论文”),看上去似乎有点意思,于是阅读了一番,读完确实有些收获,在此记录分享一下。
给全连接或者卷积模型的核加上带有正交化倾向的正则项,是不少模型的需求,比如大名鼎鼎的BigGAN就加入了类似的正则项。而这篇论文则引入了一个新的正则项,笔者认为整个分析过程颇为有趣,可以一读。
为什么希望正交?
在开始之前,我们先约定:本文所出现的所有一维向量都代表列向量。那么,现在假设有一个$d$维的输入样本$\boldsymbol{x}\in \mathbb{R}^d$,经过全连接或卷积层时,其核心运算就是:
\begin{equation}\boldsymbol{y}^{\top}=\boldsymbol{x}^{\top}\boldsymbol{W},\quad \boldsymbol{W}\triangleq (\boldsymbol{w}_1,\boldsymbol{w}_2,\dots,\boldsymbol{w}_k)\label{eq:k}\end{equation}
其中$\boldsymbol{W}\in \mathbb{R}^{d\times k}$是一个矩阵,它就被称“核”(全连接核/卷积核),而$\boldsymbol{w}_1,\boldsymbol{w}_2,\dots,\boldsymbol{w}_k\in \mathbb{R}^{d}$是该矩阵的各个列向量。
20
May
函数光滑化杂谈:不可导函数的可导逼近
By 苏剑林 | 2019-05-20 | 121832位读者 | 引用一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。
还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到$\text{argmax}$等操作),所以没法直接用。
这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀鸡”的方案;另外一种是试图给正确率找一个光滑可导的近似公式。本文就来探讨一下常见的不可导函数的光滑近似,有时候我们称之为“光滑化”,有时候我们也称之为“软化”。
max
后面谈到的大部分内容,基础点就是$\max$操作的光滑近似,我们有:
\begin{equation}\max(x_1,x_2,\dots,x_n) = \lim_{K\to +\infty}\frac{1}{K}\log\left(\sum_{i=1}^n e^{K x_i}\right)\end{equation}
3
Jun
基于DGCNN和概率图的轻量级信息抽取模型
By 苏剑林 | 2019-06-03 | 401456位读者 | 引用背景:前几个月,百度举办了“2019语言与智能技术竞赛”,其中有三个赛道,而我对其中的“信息抽取”赛道颇感兴趣,于是报名参加。经过两个多月的煎熬,比赛终于结束,并且最终结果已经公布。笔者从最初的对信息抽取的一无所知,经过这次比赛的学习和研究,最终探索出在监督学习下做信息抽取的一些经验,遂在此与大家分享。

信息抽取赛道:“科学空间队”在最终的测试结果上排名第七
笔者在最终的测试集上排名第七,指标F1为0.8807(Precision是0.8939,Recall是0.8679),跟第一名相差0.01左右。从比赛角度这个成绩不算突出,但自认为模型有若干创新之处,比如自行设计的抽取结构、CNN+Attention(所以足够快速)、没有用Bert等预训练模型,私以为这对于信息抽取的学术研究和工程应用都有一定的参考价值。
基本分析
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础,一直受到业界的广泛关注。... 本次竞赛将提供业界规模最大的基于schema的中文信息抽取数据集(Schema based Knowledge Extraction, SKE),旨在为研究者提供学术交流平台,进一步提升中文信息抽取技术的研究水平,推动相关人工智能应用的发展。------ 比赛官方网站介绍
10
Jun
漫谈重参数:从正态分布到Gumbel Softmax
By 苏剑林 | 2019-06-10 | 222660位读者 | 引用最近在用VAE处理一些文本问题的时候遇到了对离散形式的后验分布求期望的问题,于是沿着“离散分布 + 重参数”这个思路一直搜索下去,最后搜到了Gumbel Softmax,从对Gumbel Softmax的学习过程中,把重参数的相关内容都捋了一遍,还学到一些梯度估计的新知识,遂记录在此。
文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。
基本概念
重参数(Reparameterization)实际上是处理如下期望形式的目标函数的一种技巧:
\begin{equation}L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\label{eq:base}\end{equation}
这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现($f(z)$对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于$z$的连续性,它对应不同的形式:
\begin{equation}\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\end{equation}
当然,离散情况下我们更喜欢将记号$z$换成$y$或者$c$。
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 414672位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
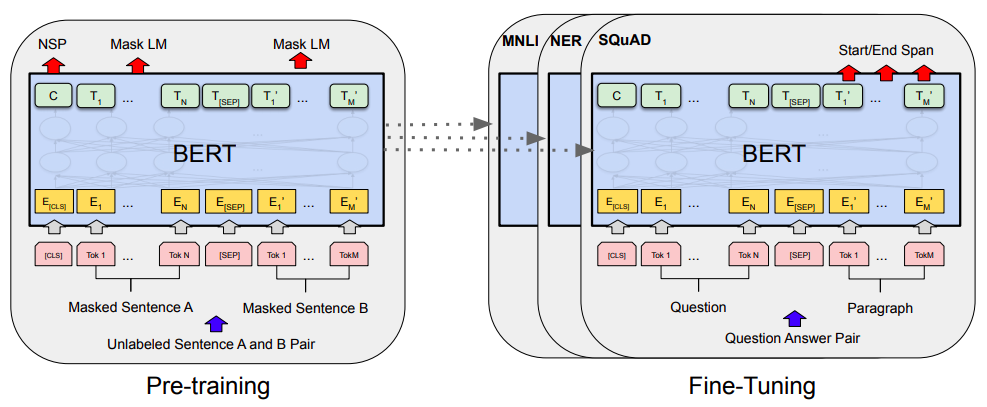
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
24
Jun
VQ-VAE的简明介绍:量子化自编码器
By 苏剑林 | 2019-06-24 | 310610位读者 | 引用印象中很早之前就看到过VQ-VAE,当时对它并没有什么兴趣,而最近有两件事情重新引起了我对它的兴趣。一是VQ-VAE-2实现了能够匹配BigGAN的生成效果(来自机器之心的报道);二是我最近看一篇NLP论文《Unsupervised Paraphrasing without Translation》时发现里边也用到了VQ-VAE。这两件事情表明VQ-VAE应该是一个颇为通用和有意思的模型,所以我决定好好读读它。

个人复现的VQ-VAE在CelebA上的重构效果。可以留意到细节保留得还不错,但稍微放大后能留意到仍有一些模糊感。

最近评论