






29
Oct
求解微分方程的李对称方法(一)
By 苏剑林 | 2013-10-29 | 27887位读者 | 引用
马里乌斯·索菲斯·李
在这篇日志发表之前,科学空间在整个十月就只是在国庆期间发了一篇小感想,这是比较少见的。一个小原因是这学期社团(广播台)方面的活动有点多,当然这不是主要的,其实这个月我大多数课余时间放到了两件事情上:一是无线电路的入门,二就是本文所要讲的《求解微分方程的李对称方法》。
李对称方法主要是通过发现微分方程的对称性来求解微分方程。我首次接触到这个方法是在一本叫《微分方程与数学物理问题》的书上边,书中写得很清晰易懂,后来我还买了类似的《微分方程的对称与积分方法》,后者相对抽象一些,讨论也深入一些。在我目前发现的中文书籍中,这是唯一的两本以李对称方法求解微分方程为主题的书。这两本书还有一个共同特点,就是它们都是外国教材的翻译版。
26
Nov
求解微分方程的李对称方法(二)
By 苏剑林 | 2013-11-26 | 23908位读者 | 引用由于重装系统时的粗心大意,笔者把《求解微分方程的李对称方法》的Word文档弄丢了,更不幸的是存有该文档的U盘也弄丢了~没办法,只好重新把这篇文章录入了。幸好之前曾把它打印成纸质版,还有旧稿可以参考。现发布《求解微分方程的李对称方法(二)》,希望能够为对李对称方法有兴趣的朋友提供些许资源。
相比(一),(二)将所有内容重新用CTex录入了,果然,$\LaTeX$才是写数学论文软件中的佼佼者,虽然是纯代码编辑,但是这正符合我追求简洁清晰的风格。在内容上,(二)增加了一阶常微分方程组的内容,并对(一)的部分细节做了修改,本文完成后就初步相对完整地叙述了一阶常微分方程组的李对称积分的思路,内容增加到了13页。而在接下来的(三)中,将会提供李代数的内容;如果有(四)的话,就会谈到李对称方法的计算机实现。希望大家会喜欢这系列文章。更期待大家的读后感(包括挑错)^_^
15
Jul
《新理解矩阵6》:为什么只有方阵有行列式?
By 苏剑林 | 2014-07-15 | 69671位读者 | 引用学过线性代数的朋友都知道,方阵和非方阵的一个明显不同是,对于方阵我们可以计算它的行列式,如果不是方阵的话,就没有行列式这个概念了。在追求统一和谐的数学系统中,为什么非方阵却没有行列式?也许对于这个问题最恰当的回答是——因为不够美。对于非方阵,其实也可以类似地定义它的行列式,定义出来的东西,跟方阵的行列式具有同样的性质,比如某行乘上一个常数,行列式值也就乘以一个常数,等等;而且还可以把其几何意义保留下来。但是,非方阵的行列式是不够美的,因为对于一个一般的整数元素的方阵,我们的行列式是一个整数;而对于一个一般的整数元素的非方阵,却导致了一个无理数的行列式值。另外,一个也比较重要的原因是,单单是方阵的行列式也够用了。综合以上两个理由,非方阵的行列式就被舍弃不用了。
非方阵的行列式不够漂亮
$n$阶方阵的行列式是每个向量的线性函数,它代表着向量之间的线性相关性;从几何上来讲,它就是向量组成的平行n维体的(有向)体积。我们当然期望非方阵的行列式也保留这些性质,因为只有这样,方阵行列式的那些运算性质才得以保留,比如上面说的,行列式的一行乘上一个常数,行列式值也乘上一个常数。我们考虑$m\times n$的矩阵,其中$ m < n $,我们将它看成是$m$个$n$维向量的组合。最简单的,我们先考虑$1\times 2$矩阵的行列式,也就是二维向量$(a,b)$的行列式。
24
Nov
力的无穷分解与格林函数法
By 苏剑林 | 2014-11-24 | 36538位读者 | 引用我小时候一直有个疑问:
直升机上的螺旋桨能不能用来挡雨?
一般的螺旋桨是若干个“条状”物通过旋转对称而形成的,也就是说,它并非一个面,按常理来说,它是没办法用来挡雨的。但是,如果在高速旋转的情况下,甚至假设旋转速度可以任意大,那么我们任意时刻都没有办法穿过它了,这种情况下,它似乎与一个实在的面无异?
力的无穷分解
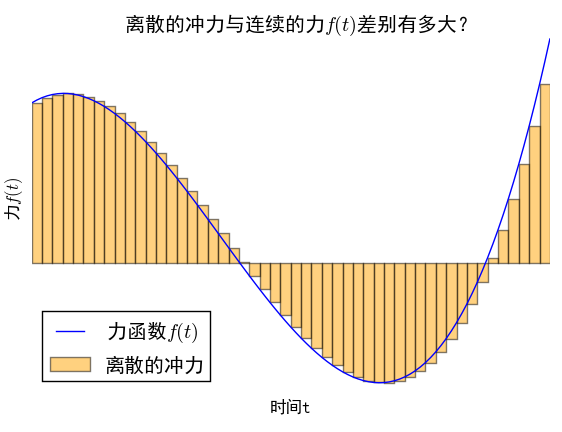
力的离散化
而让人惊喜的是,在通常的物理系统中,将力分段为无数个小区间内的恒力的做法,能够导致正确的答案,而且,这恰好是线性常微分方程的格林函数法。下面我们来分析这一做法。
2
Nov
【理解黎曼几何】8. 处处皆几何 (力学几何化)
By 苏剑林 | 2016-11-02 | 59436位读者 | 引用黎曼几何在广义相对论中的体现和应用,虽然不能说家喻户晓,但想必大部分读者都有所听闻。一谈到黎曼几何在物理学中的应用,估计大家的第一反应就是广义相对论。常见的观点是,广义相对论的发现大大推动了黎曼几何的发展。诚然,这是事实,然而,大多数人不知道的事,哪怕经典的牛顿力学中,也有黎曼几何的身影。
本文要谈及的内容,就是如何将力学几何化,从而使用黎曼几何的概念来描述它们。整个过程事实上是提供了一种框架,它可以将不少其他领域的理论纳入到黎曼几何体系中。
黎曼几何的出发点就是黎曼度量,通过黎曼度量可以通过变分得到测地线。从这个意义上来看,黎曼度量提供了一个变分原理。那反过来,一个变分原理,能不能提供一个黎曼度量呢?众所周知,不少学科的基础原理都可以归结为一个极值原理,而有了极值原理就不难导出变分原理(泛函极值),如物理中就有最小作用量原理、最小势能原理,概率论中有最大熵原理,等等。如果有一个将变分原理导出黎曼度量的方法,那么就可以用几何的方式来描述它。幸运的是,对于二次型的变分原理,是可以做到的。
26
Jan
SVD分解(二):为什么SVD意味着聚类?
By 苏剑林 | 2017-01-26 | 77391位读者 | 引用提前祝各位读者新年快乐,2017行好运~
这篇文章主要想回答两个“为什么”的问题:1、为啥我就对SVD感兴趣了?;2、为啥我说SVD是一个聚类过程?回答的内容纯粹个人思辨结果,暂无参考文献。
为什么要研究SVD?
从2015年接触深度学习到现在,已经研究了快两年的深度学习了,现在深度学习、数据科学等概念也遍地开花。为什么在深度学习火起来的时候,我反而要回去研究“古老”的SVD分解呢?我觉得,SVD作为一个矩阵分解算法,它的价值不仅仅体现在它广泛的应用,它背后还有更加深刻的内涵,即它的可解释性。在深度学习流行的今天,不少人还是觉得深度学习(神经网络)就是一个有效的“黑箱”模型。但是,仅用“黑箱”二字来解释深度学习的有效性显然不能让人满意。前面已经说过,SVD分解本质上与不带激活函数的三层自编码机等价,理解SVD分解,能够为神经网络模型寻求一个合理的概率解释。
15
Mar
从最大似然到EM算法:一致的理解方式
By 苏剑林 | 2018-03-15 | 148210位读者 | 引用最近在思考NLP的无监督学习和概率图相关的一些内容,于是重新把一些参数估计方法理了一遍。在深度学习中,参数估计是最基本的步骤之一了,也就是我们所说的模型训练过程。为了训练模型就得有个损失函数,而如果没有系统学习过概率论的读者,能想到的最自然的损失函数估计是平均平方误差,它也就是对应于我们所说的欧式距离。而理论上来讲,概率模型的最佳搭配应该是“交叉熵”函数,它来源于概率论中的最大似然函数。
最大似然
合理的存在
何为最大似然?哲学上有句话叫做“存在就是合理的”,最大似然的意思是“存在就是最合理的”。具体来说,如果事件$X$的概率分布为$p(X)$,如果一次观测中具体观测到的值分别为$X_1,X_2,\dots,X_n$,并假设它们是相互独立,那么
$$\mathcal{P} = \prod_{i=1}^n p(X_i)\tag{1}$$
是最大的。如果$p(X)$是一个带有参数$\theta$的概率分布式$p_{\theta}(X)$,那么我们应当想办法选择$\theta$,使得$\mathcal{L}$最大化,即
$$\theta = \mathop{\text{argmax}}_{\theta} \mathcal{P}(\theta) = \mathop{\text{argmax}}_{\theta}\prod_{i=1}^n p_{\theta}(X_i)\tag{2}$$
15
Apr
基于CNN的阅读理解式问答模型:DGCNN
By 苏剑林 | 2018-04-15 | 437839位读者 | 引用2019.08.20更新:开源了一个Keras版(https://kexue.fm/archives/6906)
早在年初的《Attention is All You Need》的介绍文章中就已经承诺过会分享CNN在NLP中的使用心得,然而一直不得其便。这几天终于下定决心来整理一下相关的内容了。
背景
事不宜迟,先来介绍一下模型的基本情况。
模型特点
本模型——我称之为DGCNN——是基于CNN和简单的Attention的模型,由于没有用到RNN结构,因此速度相当快,而且是专门为这种WebQA式的任务定制的,因此也相当轻量级。SQUAD排行榜前面的模型,如AoA、R-Net等,都用到了RNN,并且还伴有比较复杂的注意力交互机制,而这些东西在DGCNN中基本都没有出现。
这是一个在GTX1060上都可以几个小时训练完成的模型!

截止到2018.04.14的排行榜
DGCNN,全名为Dilate Gated Convolutional Neural Network,即“膨胀门卷积神经网络”,顾名思义,融合了两个比较新的卷积用法:膨胀卷积、门卷积,并增加了一些人工特征和trick,最终使得模型在轻、快的基础上达到最佳的效果。在本文撰写之时,本文要介绍的模型还位于榜首,得分(得分是准确率与F1的平均)为0.7583,而且是到目前为止唯一一个一直没有跌出前三名、并且获得周冠军次数最多的模型。

最近评论