






18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 56895位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
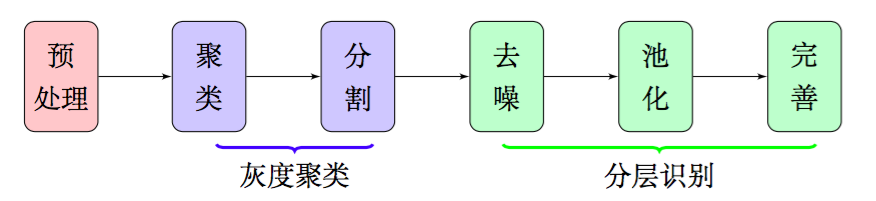
图2:特征提取大概流程
26
Jun
OCR技术浅探:8. 综合评估
By 苏剑林 | 2016-06-26 | 29775位读者 | 引用数据验证
尽管在测试环境下模型工作良好,但是实践是检验真理的唯一标准. 在本节中,我们通过自己的模型,与京东的测试数据进行比较验证.
衡量OCR系统的好坏有两部分内容:(1)是否成功地圈出了文字;(2)对于圈出来的文字,有没有成功识别. 我们采用评分的方法,对每一张图片的识别效果进行评分. 评分规则如下:
如果圈出的文字区域能够跟京东提供的检测样本的box文件中匹配,那么加1分,如果正确识别出文字来,另外加1分,最后每张图片的分数是前面总分除以文字总数.
按照这个规则,每张图片的评分最多是2分,最少是0分. 如果评分超过1,说明识别效果比较好了. 经过京东的测试数据比较,我们的模型平均评分大约是0.84,效果差强人意。
后台提示,本文是科学空间的第1000篇文章。
本想写下一篇文章的,但是看到这个提示,就先瞎写个水文纪念一下。都说人老了就喜欢各种感叹,这话还真不假。看到别人高考来个感想,博客十周年了来个感想,现在第1000篇文章了也来个感想,似乎总想找点理由感叹一下一样。那今天又能扯些啥犊子呢?

1000
首先,自恋一下。1000篇文章,如果要印刷下来,就算每篇文章印一页,那也能印个1000页了,相信不少人都没捧起过1000页的书吧(我还真读过,有文章为证:《哈哈,我的“〈圣经〉”到了》),我居然能写个1000篇,也是挺佩服自己的。当然,早期的文章有部分是转载的,不是全部都自己写的,不过还是坚持了不少原创内容,而且就算是转载的也是经过自己编辑整理的,不算纯Copy,所以也勉强能说的过去吧。
然后,庆幸一下。博客开始的主题是天文和科普,后来慢慢偏向了理论物理和数学,现在则偏向了机器学习,但不管怎样,总算很庆幸地在科学这条路坚持了下来。虽然没有像幼时设想的那样成为一名真正的自然科学家/数学家,但终究有点相关,闲时依然可以做做科学计算,勉强也对得起当初的梦想。
3
Mar
T5 PEGASUS:开源一个中文生成式预训练模型
By 苏剑林 | 2021-03-03 | 190482位读者 | 引用去年在文章《那个屠榜的T5模型,现在可以在中文上玩玩了》中我们介绍了Google的多国语言版T5模型(mT5),并给出了用mT5进行中文文本生成任务的例子。诚然,mT5做中文生成任务也是一个可用的方案,但缺乏完全由中文语料训练出来模型总感觉有点别扭,于是决心要搞一个出来。
经过反复斟酌测试,我们决定以mT5为基础架构和初始权重,先结合中文的特点完善Tokenizer,然后模仿PEGASUS来构建预训练任务,从而训练一版新的T5模型,这就是本文所开源的T5 PEGASUS。

T5 PEGASUS的训练数据示例

最近评论