






13
Aug
exp(1/2 t^2+xt)级数展开的图解技术
By 苏剑林 | 2015-08-13 | 31832位读者 | 引用本文要研究的是关于$t$的函数
$$\exp\left(\frac{1}{2}t^2+xt\right)$$
在$t=0$处的泰勒展开式。显然,它并不困难,手算或者软件都可以做出来,答案是:
$$1+x t+\frac{1}{2} \left(x^2+1\right) t^2+\frac{1}{6}\left(x^3+3 x\right) t^3 +\frac{1}{24} \left(x^4+6 x^2+3\right) t^4 + \dots$$
不过,本文将会给出笔者构造的该级数的一个图解方法。通过这个图解方法比较比较直观而方便地手算出展开式的前面一些项。后面我们再来谈谈这种图解技术的起源以及进一步的应用。
级数的图解方法:说明
首先,很明显要写出这个级数,关键是写出展开式的每一项,也就是要求出
$$f_k (x) = \left.\frac{d^k}{dt^k}\exp\left(\frac{1}{2}t^2+xt\right)\right|_{t=0}$$
$f_k (x)$是一个关于$x$的$k$次整系数多项式,$k$是展开式的阶,也是求导的阶数。
这里,我们用一个“点”表示一个$x$,用“两点之间的一条直线”表示“相乘”,那么,$x^2$就可以表示成

x^2项
18
Jun
OCR技术浅探:3. 特征提取(2)
By 苏剑林 | 2016-06-18 | 40045位读者 | 引用
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 57630位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
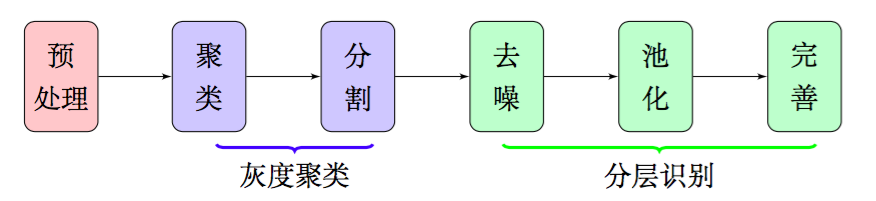
图2:特征提取大概流程
26
Jun
OCR技术浅探:7. 语言模型
By 苏剑林 | 2016-06-26 | 52251位读者 | 引用由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方法之一.
转移概率
在我们分析实验结果的过程中,有出现这一案例.由于图像不清晰等可能的原因,导致“电视”一词被识别为“电柳”,仅用图像模型是不能很好地解决这个问题的,因为从图像模型来看,识别为“电柳”是最优的选择.但是语言模型却可以很巧妙地解决这个问题.原因很简单,基于大量的文本数据我们可以统计“电视”一词和“电柳”一词的概率,可以发现“电视”一词的概率远远大于“电柳”,因此我们会认为这个词是“电视”而不是“电柳”.
从概率的角度来看,就是对于第一个字的区域的识别结果$s_1$,我们前面的卷积神经网络给出了“电”、“宙”两个候选字(仅仅选了前两个,后面的概率太小),每个候选字的概率$W(s_1)$分别为0.99996、0.00004;第二个字的区域的识别结果$s_2$,我们前面的卷积神经网络给出了“柳”、“视”、“规”(仅仅选了前三个,后面的概率太小),每个候选字的概率$W(s_2)$分别为0.87838、0.12148、0.00012,因此,它们事实上有六种组合:“电柳”、“电视”、“电规”、“宙柳”、“宙视”、“宙规”.
12
Sep
【中文分词系列】 5. 基于语言模型的无监督分词
By 苏剑林 | 2016-09-12 | 154148位读者 | 引用迄今为止,前四篇文章已经介绍了分词的若干思路,其中有基于最大概率的查词典方法、基于HMM或LSTM的字标注方法等。这些都是已有的研究方法了,笔者所做的就只是总结工作而已。查词典方法和字标注各有各的好处,我一直在想,能不能给出一种只需要大规模语料来训练的无监督分词模型呢?也就是说,怎么切分,应该是由语料来决定的,跟语言本身没关系。说白了,只要足够多语料,就可以告诉我们怎么分词。
看上去很完美,可是怎么做到呢?《2.基于切分的新词发现》中提供了一种思路,但是不够彻底。那里居于切分的新词发现方法确实可以看成一种无监督分词思路,它就是用一个简单的凝固度来判断某处该不该切分。但从分词的角度来看,这样的分词系统未免太过粗糙了。因此,我一直想着怎么提高这个精度,前期得到了一些有意义的结果,但都没有得到一个完整的理论。而最近正好把这个思路补全了。因为没有查找到类似的工作,所以这算是笔者在分词方面的一点原创工作了。
语言模型
首先简单谈一下语言模型。
6
Jun
通用爬虫探索(二):落实到论坛爬取上
By 苏剑林 | 2017-06-06 | 25699位读者 | 引用前述的方案,如果爬取的页面仅仅有单一的有效区域,如博客页、新闻页等,那么基本上来说已经足够了。但是,诸如像论坛这样的具有比较明显的层次划分的网站,我们需要进一步细分。因为经过上述步骤,我们虽然能够把有效文本提取出来,但结果是把所有文本放在一块了。
深度优先
而为了给内容进一步“分块”,我们还需要利用DOM树的位置信息。如上一篇的DOM树图,我们需要给每个节点和叶子都编号,即我们需要一个遍历DOM树的方式。这里我们采用“深度优先”的方案。
深度优先搜索算法(英语:Depth-First-Search,简称DFS)是一种用于遍历或搜索树或图的算法。沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
23
Jan
揭开迷雾,来一顿美味的Capsule盛宴
By 苏剑林 | 2018-01-23 | 447176位读者 | 引用
Geoffrey Hinton在谷歌多伦多办公室
由深度学习先驱Hinton开源的Capsule论文《Dynamic Routing Between Capsules》,无疑是去年深度学习界最热点的消息之一。得益于各种媒体的各种吹捧,Capsule被冠以了各种神秘的色彩,诸如“抛弃了梯度下降”、“推倒深度学习重来”等字眼层出不穷,但也有人觉得Capsule不外乎是一个新的炒作概念。
本文试图揭开让人迷惘的云雾,领悟Capsule背后的原理和魅力,品尝这一顿Capsule盛宴。同时,笔者补做了一个自己设计的实验,这个实验能比原论文的实验更有力说明Capsule的确产生效果了。
菜谱一览:
1、Capsule是什么?
2、Capsule为什么要这样做?
3、Capsule真的好吗?
4、我觉得Capsule怎样?
5、若干小菜。
31
Jul
我们真的需要把训练集的损失降低到零吗?
By 苏剑林 | 2020-07-31 | 68525位读者 | 引用在训练模型的时候,我们需要损失函数一直训练到0吗?显然不用。一般来说,我们是用训练集来训练模型,但希望的是验证集的损失越小越好,而正常来说训练集的损失降低到一定值后,验证集的损失就会开始上升,因此没必要把训练集的损失降低到0。
既然如此,在已经达到了某个阈值之后,我们可不可以做点别的事情来提升模型性能呢?ICML 2020的论文《Do We Need Zero Training Loss After Achieving Zero Training Error?》回答了这个问题。不过论文的回答也仅局限在“是什么”这个层面上,并没很好地描述“为什么”,另外看了知乎上kid丶大佬的解读,也没找到自己想要的答案。因此自己分析了一下,记录在此。
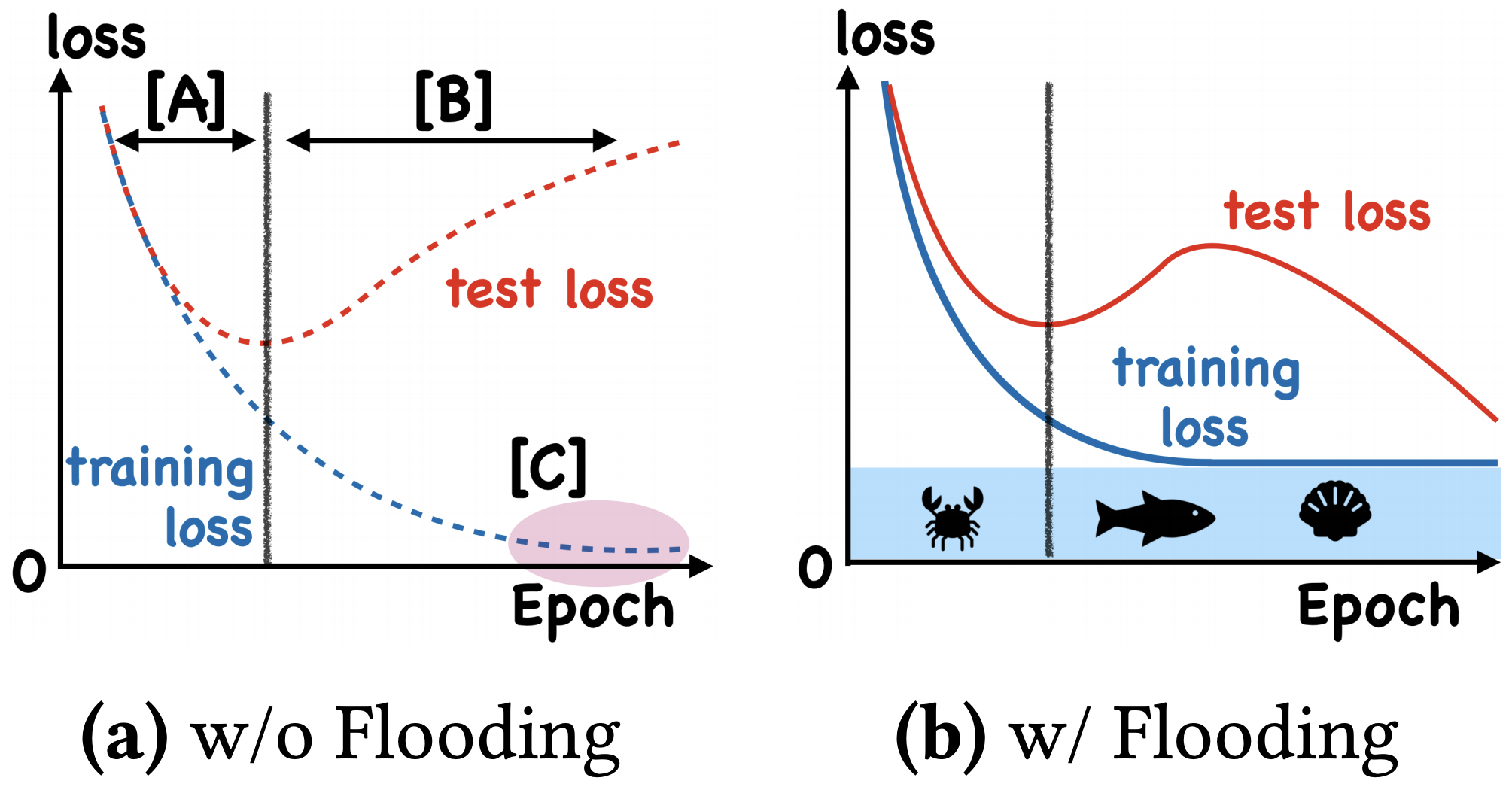
左图:不加Flooding的训练示意图;右图:加了Flooding的训练示意图

最近评论