






15
Sep
低秩近似之路(一):伪逆
By 苏剑林 | 2024-09-15 | 17874位读者 | 引用可能很多读者跟笔者一样,对矩阵的低秩近似有种熟悉而又陌生的感觉。熟悉是因为,低秩近似的概念和意义都不难理解,加之目前诸如LoRA等基于低秩近似的微调技术遍地开花,让低秩近似的概念在耳濡目染间就已经深入人心;然而,低秩近似所覆盖的内容非常广,在低秩近似相关的论文中时常能看到一些不熟悉但又让我们叹为观止的新技巧,这就导致了一种似懂非懂的陌生感。
因此,在这个系列文章中,笔者将试图系统梳理一下矩阵低秩近似相关的理论内容,以补全对低秩近似的了解。而在第一篇文章中,我们主要介绍低秩近似系列中相对简单的一个概念——伪逆。
优化视角
伪逆(Pseudo Inverse),也称“广义逆(Generalized Inverse)”,顾名思义就是“广义的逆矩阵”,它实际上是“逆矩阵”的概念对于不可逆矩阵的推广。
12
Aug
“Cool Papers + 站内搜索”的一些新尝试
By 苏剑林 | 2024-08-12 | 15135位读者 | 引用在《Cool Papers更新:简单搭建了一个站内检索系统》这篇文章中,我们介绍了Cool Papers新增的站内搜索系统。搜索系统的目的,自然希望能够帮助用户快速找到他们需要的论文。然而,如何高效地检索到对自己有价值的结果,并不是一件简单的事情,这里边往往需要一些技巧,比如精准提炼关键词。
这时候算法的价值就体现出来了,有些步骤人工来做会比较繁琐,但用算法来却很简单。所以接下来,我们将介绍几点通过算法来提高Cool Papers的搜索和筛选论文效率的新尝试。
相关论文
站内搜索背后的技术是全文检索引擎(Full-text Search Engine),简单来说,这就是一个基于关键词匹配的搜索算法,其相似度指标是BM25。
1
Oct
低秩近似之路(二):SVD
By 苏剑林 | 2024-10-01 | 14276位读者 | 引用上一篇文章中我们介绍了“伪逆”,它关系到给定矩阵$\boldsymbol{M}$和$\boldsymbol{A}$(或$\boldsymbol{B}$)时优化目标$\Vert \boldsymbol{A}\boldsymbol{B} - \boldsymbol{M}\Vert_F^2$的最优解。这篇文章我们来关注$\boldsymbol{A},\boldsymbol{B}$都不给出时的最优解,即
\begin{equation}\mathop{\text{argmin}}_{\boldsymbol{A},\boldsymbol{B}}\Vert \boldsymbol{A}\boldsymbol{B} - \boldsymbol{M}\Vert_F^2\label{eq:loss-ab}\end{equation}
其中$\boldsymbol{A}\in\mathbb{R}^{n\times r}, \boldsymbol{B}\in\mathbb{R}^{r\times m}, \boldsymbol{M}\in\mathbb{R}^{n\times m},r < \min(n,m)$。说白了,这就是要寻找矩阵$\boldsymbol{M}$的“最优$r$秩近似(秩不超过$r$的最优近似)”。而要解决这个问题,就需要请出大名鼎鼎的“SVD(奇异值分解)”了。虽然本系列把伪逆作为开篇,但它的“名声”远不如SVD,听过甚至用过SVD但没听说过伪逆的应该大有人在,包括笔者也是先了解SVD后才看到伪逆。
接下来,我们将围绕着矩阵的最优低秩近似来展开介绍SVD。
结论初探
对于任意矩阵$\boldsymbol{M}\in\mathbb{R}^{n\times m}$,都可以找到如下形式的奇异值分解(SVD,Singular Value Decomposition):
\begin{equation}\boldsymbol{M} = \boldsymbol{U}\boldsymbol{\Sigma} \boldsymbol{V}^{\top}\end{equation}
6
Sep
“闭门造车”之多模态思路浅谈(三):位置编码
By 苏剑林 | 2024-09-06 | 33624位读者 | 引用在前面的文章中,我们曾表达过这样的观点:多模态LLM相比纯文本LLM的主要差异在于,前者甚至还没有形成一个公认为标准的方法论。这里的方法论,不仅包括之前讨论的生成和训练策略,还包括一些基础架构的设计,比如本文要谈的“多模态位置编码”。
对于这个主题,我们之前在《Transformer升级之路:17、多模态位置编码的简单思考》就已经讨论过一遍,并且提出了一个方案(RoPE-Tie)。然而,当时笔者对这个问题的思考仅处于起步阶段,存在细节考虑不周全、认识不够到位等问题,所以站在现在的角度回看,当时所提的方案与完美答案还有明显的距离。
因此,本文我们将自上而下地再次梳理这个问题,并且给出一个自认为更加理想的结果。
多模位置
多模态模型居然连位置编码都没有形成共识,这一点可能会让很多读者意外,但事实上确实如此。对于文本LLM,目前主流的位置编码是RoPE(RoPE就不展开介绍了,假设读者已经熟知),更准确来说是RoPE-1D,因为原始设计只适用于1D序列。后来我们推导了RoPE-2D,这可以用于图像等2D序列,按照RoPE-2D的思路我们可以平行地推广到RoPE-3D,用于视频等3D序列。
26
Sep
利用“熄火保护 + 通断器”实现燃气灶智能关火
By 苏剑林 | 2024-09-26 | 13785位读者 | 引用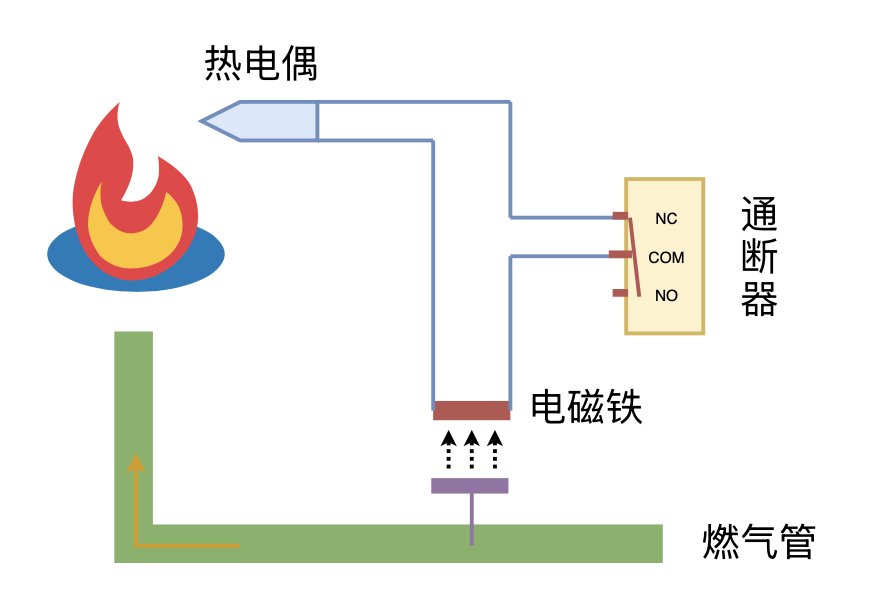
11
Oct
低秩近似之路(三):CR
By 苏剑林 | 2024-10-11 | 11657位读者 | 引用在《低秩近似之路(二):SVD》中,我们证明了SVD可以给出任意矩阵的最优低秩近似。那里的最优近似是无约束的,也就是说SVD给出的结果只管误差上的最小,不在乎矩阵的具体结构,而在很多应用场景中,出于可解释性或者非线性处理等需求,我们往往希望得到具有某些特殊结构的近似分解。
因此,从这篇文章开始,我们将探究一些具有特定结构的低秩近似,而本文将聚焦于其中的CR近似(Column-Row Approximation),它提供了加速矩阵乘法运算的一种简单方案。
问题背景
矩阵的最优$r$秩近似的一般提法是
\begin{equation}\mathop{\text{argmin}}_{\text{rank}(\tilde{\boldsymbol{M}})\leq r}\Vert \tilde{\boldsymbol{M}} - \boldsymbol{M}\Vert_F^2\label{eq:loss-m2}\end{equation}
30
Oct
低秩近似之路(四):ID
By 苏剑林 | 2024-10-30 | 7309位读者 | 引用这篇文章的主角是ID(Interpolative Decomposition),中文可以称之为“插值分解”,它同样可以理解为是一种具有特定结构的低秩分解,其中的一侧是该矩阵的若干列(当然如果你偏好于行,那么选择行也没什么问题),换句话说,ID试图从一个矩阵中找出若干关键列作为“骨架”(通常也称作“草图”)来逼近原始矩阵。
可能很多读者都未曾听说过ID,即便维基百科也只有几句语焉不详的介绍(链接),但事实上,ID跟SVD一样早已内置在SciPy之中(参考scipy.linalg.interpolative),这侧面印证了ID的实用价值。
基本定义
前三篇文章我们分别介绍了伪逆、SVD、CR近似,它们都可以视为寻找特定结构的低秩近似:
\begin{equation}\mathop{\text{argmin}}_{\text{rank}(\tilde{\boldsymbol{M}})\leq r}\Vert \tilde{\boldsymbol{M}} - \boldsymbol{M}\Vert_F^2\end{equation}
24
Oct
VQ的旋转技巧:梯度直通估计的一般推广
By 苏剑林 | 2024-10-24 | 11795位读者 | 引用随着多模态LLM的方兴未艾,VQ(Vector Quantization)的地位也“水涨船高”,它可以作为视觉乃至任意模态的Tokenizer,将多模态数据统一到自回归生成框架中。遗憾的是,自VQ-VAE首次提出VQ以来,其理论并没有显著进步,像编码表的坍缩或利用率低等问题至今仍亟待解决,取而代之的是FSQ等替代方案被提出,成为了VQ有力的“竞争对手”。
然而,FSQ并不能在任何场景下都替代VQ,所以VQ本身的改进依然是有价值的。近日笔者读到了《Restructuring Vector Quantization with the Rotation Trick》,它提出了一种旋转技巧,声称能改善VQ的一系列问题,本文就让我们一起来品鉴一下。
回顾
早在五年前的博文《VQ-VAE的简明介绍:量子化自编码器》中我们就介绍过了VQ-VAE,后来在《简单得令人尴尬的FSQ:“四舍五入”超越了VQ-VAE》介绍FSQ的时候,也再次仔细地温习了VQ-VAE,还不了解的读者可以先阅读这两篇文章。

最近评论