






25
Apr
傅里叶变换:只需要异想天开?
By 苏剑林 | 2014-04-25 | 42563位读者 | 引用在对数学或物理进行事后分析,往往会发现一些奇怪的现象,也有可能得到一些更为深刻有趣的结果。比如本文所要谈及的傅里叶变换,可以由一种“异想天开”的思路得来。
洛朗展式
我们知道,在原点处形态良好的函数,可以展开为泰勒级数
$$f(x)=\sum_{n=0}^{\infty}a_n x^n$$
我们发现,上面的幂都是正的,为什么不能包含$x$的负数次幂呢?比如$\frac{\sin z}{z^2}$展开为
$$\frac{1}{z}-\frac{z}{6}+\frac{z^3}{120}\dots$$
显然也是一件合理的事情。于是,结合复变函数,我们得到解析函数的洛朗展式
$$f(z)=\sum_{n=-\infty}^{+\infty}a_n z^n$$
这是函数的双边展开。其中
8
Dec
伽马函数的傅里叶变换之路
By 苏剑林 | 2014-12-08 | 67207位读者 | 引用伽马函数
$$\Gamma(x)=\int_0^{+\infty}t^{x-1}e^{-t}dt$$
作为阶乘的推广,会让很多初学者感到困惑,对于笔者来说也不例外。一个最自然的问题就是:这般复杂的推广公式是如何得到的?
在cos.name的文章《神奇的伽马函数》中,有比较详细地对伽马函数的历史介绍,笔者细读之后也获益匪浅。但美中不足的是,笔者还是没能从中找到引出伽马函数的一种“自然”的办法。所谓“自然”,并不是说最简单的,而是根据一些基本的性质和定义,直接把伽马函数的表达式反解出来。它的过程和运算也许并不简单,但是思想应当是直接而简洁的。当然,我们不能苛求历史上伽马函数以这种方式诞生,但是作为事后探索是有益的,有助于我们了解伽马函数的特性。于是笔者尝试了以下途径,得到了一些结果,可是也得到了一些困惑。
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 80854位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
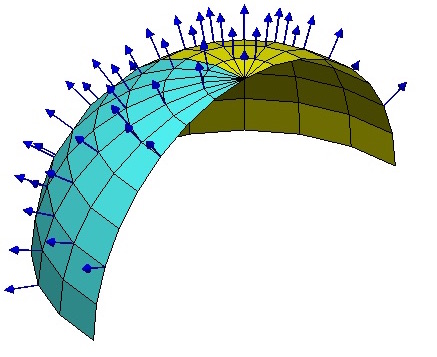
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。
14
Dec
Mitchell近似:乘法变为加法,误差不超过1/9
By 苏剑林 | 2020-12-14 | 38751位读者 | 引用今天给大家介绍一篇1962年的论文《Computer Multiplication and Division Using Binary Logarithms》,作者是John N. Mitchell,他在里边提出了一个相当有意思的算法:在二进制下,可以完全通过加法来近似完成两个数的相乘,最大误差不超过1/9。整个算法相当巧妙,更有意思的是它还有着非常简洁的编程实现,让人拍案叫绝。然而,笔者发现网上居然找不到介绍这个算法的网页,所以在此介绍一番。
你以为这只是过时的玩意?那你就错了,前不久才有人利用它发了一篇NeurIPS 2020呢!所以,确定不来了解一下吗?
11
Jan
你可能不需要BERT-flow:一个线性变换媲美BERT-flow
By 苏剑林 | 2021-01-11 | 202075位读者 | 引用BERT-flow来自论文《On the Sentence Embeddings from Pre-trained Language Models》,中了EMNLP 2020,主要是用flow模型校正了BERT出来的句向量的分布,从而使得计算出来的cos相似度更为合理一些。由于笔者定时刷Arixv的习惯,早在它放到Arxiv时笔者就看到了它,但并没有什么兴趣,想不到前段时间小火了一把,短时间内公众号、知乎等地出现了不少的解读,相信读者们多多少少都被它刷屏了一下。
从实验结果来看,BERT-flow确实是达到了一个新SOTA,但对于这一结果,笔者的第一感觉是:不大对劲!当然,不是说结果有问题,而是根据笔者的理解,flow模型不大可能发挥关键作用。带着这个直觉,笔者做了一些分析,果不其然,笔者发现尽管BERT-flow的思路没有问题,但只要一个线性变换就可以达到相近的效果,flow模型并不是十分关键。
余弦相似度的假设
一般来说,我们语义相似度比较或检索,都是给每个句子算出一个句向量来,然后算它们的夹角余弦来比较或者排序。那么,我们有没有思考过这样的一个问题:余弦相似度对所输入的向量提出了什么假设呢?或者说,满足什么条件的向量用余弦相似度做比较效果会更好呢?
14
Nov
当Batch Size增大时,学习率该如何随之变化?
By 苏剑林 | 2024-11-14 | 7008位读者 | 引用随着算力的飞速进步,有越多越多的场景希望能够实现“算力换时间”,即通过堆砌算力来缩短模型训练时间。理想情况下,我们希望投入$n$倍的算力,那么达到同样效果的时间则缩短为$1/n$,此时总的算力成本是一致的。这个“希望”看上去很合理和自然,但实际上并不平凡,即便我们不考虑通信之类的瓶颈,当算力超过一定规模或者模型小于一定规模时,增加算力往往只能增大Batch Size。然而,增大Batch Size一定可以缩短训练时间并保持效果不变吗?
这就是接下来我们要讨论的话题:当Batch Size增大时,各种超参数尤其是学习率该如何调整,才能保持原本的训练效果并最大化训练效率?我们也可以称之为Batch Size与学习率之间的Scaling Law。
方差视角
直觉上,当Batch Size增大时,每个Batch的梯度将会更准,所以步子就可以迈大一点,也就是增大学习率,以求更快达到终点,缩短训练时间,这一点大体上都能想到。问题就是,增大多少才是最合适的呢?
27
Aug
自己实现了一个bert4keras
By 苏剑林 | 2019-08-27 | 174722位读者 | 引用分享个人实现的bert4keras:
21
Mar
RoFormerV2:自然语言理解的极限探索
By 苏剑林 | 2022-03-21 | 57531位读者 | 引用大概在1年前,我们提出了旋转位置编码(RoPE),并发布了对应的预训练模型RoFormer。随着时间的推移,RoFormer非常幸运地得到了越来越多的关注和认可,比如EleutherAI新发布的60亿和200亿参数的GPT模型中就用上了RoPE位置编码,Google新提出的FLASH模型论文中则明确指出了RoPE对Transformer效果有明显的提升作用。
与此同时,我们也一直在尝试继续加强RoFormer模型,试图让RoFormer的性能“更上一层楼”。经过近半年的努力,我们自认为取得了还不错的成果,因此将其作为“RoFormerV2”正式发布:
关于站长
智能搜索
支持整句搜索!网站自动使用结巴分词进行分词,并结合ngrams排序算法给出合理的搜索结果。

最近评论