






21
Jul
思考:两个椭圆片能粘合成一个立体吗?
By 苏剑林 | 2019-07-21 | 58646位读者 | 引用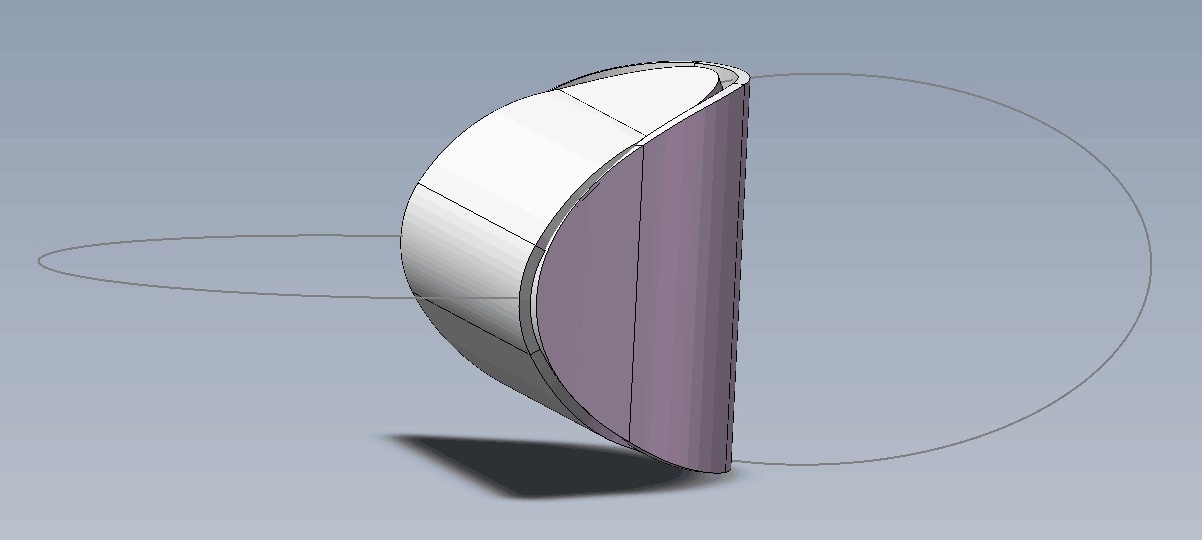
20
Aug
开源一版DGCNN阅读理解问答模型(Keras版)
By 苏剑林 | 2019-08-20 | 71907位读者 | 引用去年写过《基于CNN的阅读理解式问答模型:DGCNN》,介绍了一个纯卷积的简单的问答模型。当时是用Tensorflow实现的,而且没有开源,这几天抽空用Keras复现了一下,决定开源。
模型综述
关于DGCNN的基本介绍,这里不再赘述。本文的模型并不是之前模型的重复实现,而是有所改动,这里只介绍一下被改动的地方。
1、这里放出的模型,线下验证集的分数大概是0.72(之前大约是0.75);
2、本次模型以字为单位,使用笔者之前探索出来的“字词混合Embedding”(之前是以词为单位);
3、本次模型完全去掉了人工特征(之前用了8个人工特征);
4、本次模型去掉了位置Embedding(之前将位置Embedding拼接到输入上);
5、模型架构和训练细节有所微调。
后台提示,本文是科学空间的第1000篇文章。
本想写下一篇文章的,但是看到这个提示,就先瞎写个水文纪念一下。都说人老了就喜欢各种感叹,这话还真不假。看到别人高考来个感想,博客十周年了来个感想,现在第1000篇文章了也来个感想,似乎总想找点理由感叹一下一样。那今天又能扯些啥犊子呢?

1000
首先,自恋一下。1000篇文章,如果要印刷下来,就算每篇文章印一页,那也能印个1000页了,相信不少人都没捧起过1000页的书吧(我还真读过,有文章为证:《哈哈,我的“〈圣经〉”到了》),我居然能写个1000篇,也是挺佩服自己的。当然,早期的文章有部分是转载的,不是全部都自己写的,不过还是坚持了不少原创内容,而且就算是转载的也是经过自己编辑整理的,不算纯Copy,所以也勉强能说的过去吧。
然后,庆幸一下。博客开始的主题是天文和科普,后来慢慢偏向了理论物理和数学,现在则偏向了机器学习,但不管怎样,总算很庆幸地在科学这条路坚持了下来。虽然没有像幼时设想的那样成为一名真正的自然科学家/数学家,但终究有点相关,闲时依然可以做做科学计算,勉强也对得起当初的梦想。
7
Dec
【龟鱼记】全陶粒的同程底滤生态缸
By 苏剑林 | 2020-12-07 | 55717位读者 | 引用
8
Sep
有限内存下全局打乱几百G文件(Python)
By 苏剑林 | 2021-09-08 | 69816位读者 | 引用这篇文章我们来做一道编程题:
如何在有限内存下全局随机打乱(Shuffle)几百G的文本文件?
题目背景其实很明朗,现在预训练模型动辄就几十甚至几百G语料了,为了让模型能更好地进行预训练,对训练语料进行一次全局的随机打乱是很有必要的。但对于很多人来说,几百G的语料往往比内存还要大,所以如何能在有限内存下做到全局的随机打乱,便是一个很值得研究的问题了。
已有工具
假设我们的文件是按行存储的,也就是一行代表一个样本,我们要做的就是按行随机打乱文件。假设我们只有一个文件,并且这个文件大小明显小于内存,那么我们可以用linux自带的shuf命令:
shuf input.txt -o output.txt
10
Sep
曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果
By 苏剑林 | 2021-09-10 | 54258位读者 | 引用在五花八门的预训练任务设计中,NSP通常认为是比较糟糕的一种,因为它难度较低,加入到预训练中并没有使下游任务微调时有明显受益,甚至RoBERTa的论文显示它会带来负面效果。所以,后续的预训练工作一般有两种选择:一是像RoBERTa一样干脆去掉NSP任务,二是像ALBERT一样想办法提高NSP的难度。也就是说,一直以来NSP都是比较“让人嫌弃”的。
不过,反转来了,NSP可能要“翻身”了。最近的一篇论文《NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task--Next Sentence Prediction》(下面简称NSP-BERT)显示NSP居然也可以做到非常不错的Zero Shot效果!这又是一个基于模版(Prompt)的Few/Zero Shot的经典案例,只不过这一次的主角是NSP。
背景回顾
曾经我们认为预训练纯粹就是预训练,它只是为下游任务的训练提供更好的初始化,像BERT的预训练任务有MLM(Masked Language Model和NSP(Next Sentence Prediction),在相当长的一段时间内,大家都不关心这两个预训练任务本身,而只是专注于如何通过微调来使得下游任务获得更好的性能。哪怕是T5将模型参数训练到了110亿,走的依然是“预训练+微调”这一路线。
21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 75875位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
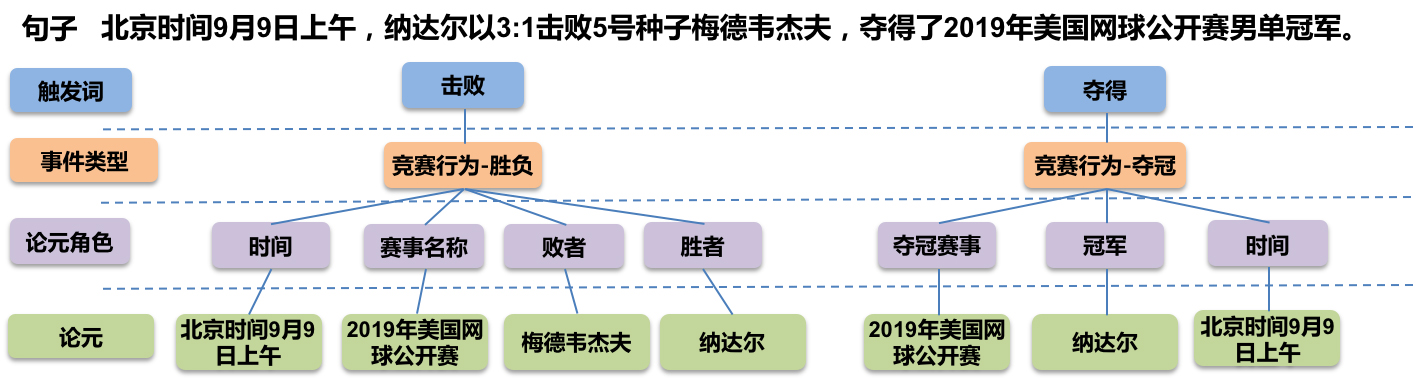
标准的事件抽取样本(图片来自百度DuEE的GitHub)

最近评论