






6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 49000位读者 | 引用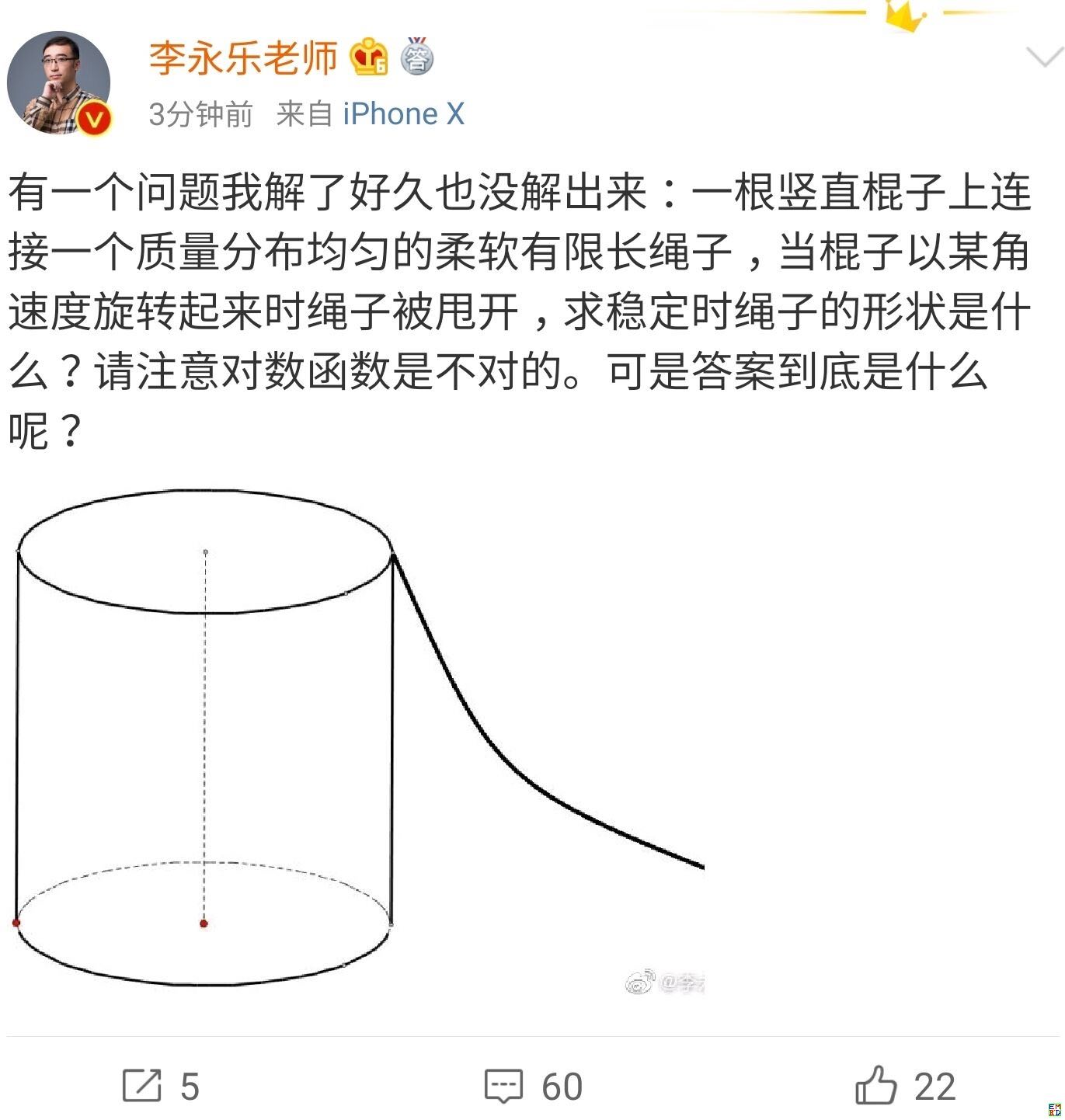
16
Jun
梯度流:探索通向最小值之路
By 苏剑林 | 2023-06-16 | 30576位读者 | 引用在这篇文章中,我们将探讨一个被称为“梯度流(Gradient Flow)”的概念。简单来说,梯度流是将我们在用梯度下降法中寻找最小值的过程中的各个点连接起来,形成一条随(虚拟的)时间变化的轨迹,这条轨迹便被称作“梯度流”。在文章的后半部分,我们将重点讨论如何将梯度流的概念扩展到概率空间,从而形成“Wasserstein梯度流”,为我们理解连续性方程、Fokker-Planck方程等内容提供一个新的视角。
梯度下降
假设我们想搜索光滑函数$f(\boldsymbol{x})$的最小值,常见的方案是梯度下降(Gradient Descent),即按照如下格式进行迭代:
\begin{equation}\boldsymbol{x}_{t+1} = \boldsymbol{x}_t -\alpha \nabla_{\boldsymbol{x}_t}f(\boldsymbol{x}_t)\label{eq:gd-d}\end{equation}
如果$f(\boldsymbol{x})$关于$\boldsymbol{x}$是凸的,那么梯度下降通常能够找到最小值点;相反,则通常只能收敛到一个“驻点”——即梯度为0的点,比较理想的情况下能收敛到一个极小值(局部最小值)点。这里没有对极小值和最小值做严格区分,因为在深度学习中,即便是收敛到一个极小值点也是很难得的了。
22
Jul
Keras中自定义复杂的loss函数
By 苏剑林 | 2017-07-22 | 430591位读者 | 引用Keras是一个搭积木式的深度学习框架,用它可以很方便且直观地搭建一些常见的深度学习模型。在tensorflow出来之前,Keras就已经几乎是当时最火的深度学习框架,以theano为后端,而如今Keras已经同时支持四种后端:theano、tensorflow、cntk、mxnet(前三种官方支持,mxnet还没整合到官方中),由此可见Keras的魅力。
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
输入-输出设计
Keras的模型是函数式的,即有输入,也有输出,而loss即为预测值与真实值的某种误差函数。Keras本身也自带了很多loss函数,如mse、交叉熵等,直接调用即可。而要自定义loss,最自然的方法就是仿照Keras自带的loss进行改写。
1
Sep
玩转Keras之seq2seq自动生成标题
By 苏剑林 | 2018-09-01 | 361802位读者 | 引用话说自称搞了这么久的NLP,我都还没有真正跑过NLP与深度学习结合的经典之作——seq2seq。这两天兴致来了,决定学习并实践一番seq2seq,当然最后少不了Keras实现了。
seq2seq可以做的事情非常多,我这挑选的是比较简单的根据文章内容生成标题(中文),也可以理解为自动摘要的一种。选择这个任务主要是因为“文章-标题”这样的语料对比较好找,能快速实验一下。
seq2seq简介
所谓seq2seq,就是指一般的序列到序列的转换任务,比如机器翻译、自动文摘等等,这种任务的特点是输入序列和输出序列是不对齐的,如果对齐的话,那么我们称之为序列标注,这就比seq2seq简单很多了。所以尽管序列标注任务也可以理解为序列到序列的转换,但我们在谈到seq2seq时,一般不包含序列标注。
要自己实现seq2seq,关键是搞懂seq2seq的原理和架构,一旦弄清楚了,其实不管哪个框架实现起来都不复杂。早期有一个第三方实现的Keras的seq2seq库,现在作者也已经放弃更新了,也许就是觉得这么简单的事情没必要再建一个库了吧。可以参考的资料还有去年Keras官方博客中写的《A ten-minute introduction to sequence-to-sequence learning in Keras》。
8
Jul
“闭门造车”之多模态思路浅谈(二):自回归
By 苏剑林 | 2024-07-08 | 44533位读者 | 引用这篇文章我们继续来闭门造车,分享一下笔者最近对多模态学习的一些新理解。
在前文《“闭门造车”之多模态思路浅谈(一):无损输入》中,我们强调了无损输入对于理想的多模型模态的重要性。如果这个观点成立,那么当前基于VQ-VAE、VQ-GAN等将图像离散化的主流思路就存在能力瓶颈,因为只需要简单计算一下信息熵就可以表明离散化必然会有严重的信息损失,所以更有前景或者说更长远的方案应该是输入连续型特征,比如直接将图像的原始像素特征Patchify后输入到模型中。
然而,连续型输入对于图像理解自然简单,但对图像生成来说则引入了额外的困难,因为非离散化无法直接套用文本的自回归框架,多少都要加入一些新内容如扩散,这就引出了本文的主题——如何进行多模态的自回归学习与生成。当然,非离散化只是表面的困难,更艰巨的部份还在后头...
无损含义
首先我们再来明确一下无损的含义。无损并不是指整个计算过程中一丁点损失都不能有,这不现实,也不符合我们所理解的深度学习的要义——在2015年的文章《闲聊:神经网络与深度学习》我们就提到过,深度学习成功的关键是信息损失。所以,这里无损的含义很简单,单纯是希望作为模型的输入来说尽可能无损。
13
Nov
n维空间下两个随机向量的夹角分布
By 苏剑林 | 2019-11-13 | 133195位读者 | 引用昨天群里大家讨论到了$n$维向量的一些反直觉现象,其中一个话题是“一般$n$维空间下两个随机向量几乎都是垂直的”,这就跟二维/三维空间的认知有明显出入了。要从理论上认识这个结论,我们可以考虑两个随机向量的夹角$\theta$分布,并算算它的均值方差。
概率密度
首先,我们来推导$\theta$的概率密度函数。呃,其实也不用怎么推导,它是$n$维超球坐标的一个直接结论。
要求两个随机向量之间的夹角分布,很显然,由于各向同性,所以我们只需要考虑单位向量,而同样是因为各向同性,我们只需要固定其中一个向量,考虑另一个向量随机变化。不是一般性,考虑随机向量为
\begin{equation}\boldsymbol{x}=(x_1,x_2,\dots,x_n)\end{equation}
而固定向量为
\begin{equation}\boldsymbol{y}=(1,0,\dots,0)\end{equation}
8
Jul
两个多元正态分布的KL散度、巴氏距离和W距离
By 苏剑林 | 2021-07-08 | 102121位读者 | 引用正态分布是最常见的连续型概率分布之一。它是给定均值和协方差后的最大熵分布(参考《“熵”不起:从熵、最大熵原理到最大熵模型(二)》),也可以看作任意连续型分布的二阶近似,它的地位就相当于一般函数的线性近似。从这个角度来看,正态分布算得上是最简单的连续型分布了。也正因为简单,所以对于很多估计量来说,它都能写出解析解来。
本文主要来计算两个多元正态分布的几种度量,包括KL散度、巴氏距离和W距离,它们都有显式解析解。
正态分布
这里简单回顾一下正态分布的一些基础知识。注意,仅仅是回顾,这还不足以作为正态分布的入门教程。
概率密度
正态分布,也即高斯分布,是定义在$\mathbb{R}^n$上的连续型概率分布,其概率密度函数为
\begin{equation}p(\boldsymbol{x})=\frac{1}{\sqrt{(2\pi)^n \det(\boldsymbol{\Sigma})}}\exp\left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\top}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right\}\end{equation}
14
Feb
生成扩散模型漫谈(十六):W距离 ≤ 得分匹配
By 苏剑林 | 2023-02-14 | 22974位读者 | 引用Wasserstein距离(下面简称“W距离”),是基于最优传输思想来度量两个概率分布差异程度的距离函数,笔者之前在《从Wasserstein距离、对偶理论到WGAN》等博文中也做过介绍。对于很多读者来说,第一次听说W距离,是因为2017年出世的WGAN,它开创了从最优传输视角来理解GAN的新分支,也提高了最优传输理论在机器学习中的地位。很长一段时间以来,GAN都是生成模型领域的“主力军”,直到最近这两年扩散模型异军突起,GAN的风头才有所下降,但其本身仍不失为一个强大的生成模型。
从形式上来看,扩散模型和GAN差异很明显,所以其研究一直都相对独立。不过,去年底的一篇论文《Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance》打破了这个隔阂:它证明了扩散模型的得分匹配损失可以写成W距离的上界形式。这意味着在某种程度上,最小化扩散模型的损失函数,实则跟WGAN一样,都是在最小化两个分布的W距离。

最近评论