






28
Mar
变分自编码器(二):从贝叶斯观点出发
By 苏剑林 | 2018-03-28 | 435925位读者 | 引用源起
前几天写了博文《变分自编码器(一):原来是这么一回事》,从一种比较通俗的观点来理解变分自编码器(VAE),在那篇文章的视角中,VAE跟普通的自编码器差别不大,无非是多加了噪声并对噪声做了约束。然而,当初我想要弄懂VAE的初衷,是想看看究竟贝叶斯学派的概率图模型究竟是如何与深度学习结合来发挥作用的,如果仅仅是得到一个通俗的理解,那显然是不够的。
所以我对VAE继续思考了几天,试图用更一般的、概率化的语言来把VAE说清楚。事实上,这种思考也能回答通俗理解中无法解答的问题,比如重构损失用MSE好还是交叉熵好、重构损失和KL损失应该怎么平衡,等等。
建议在阅读《变分自编码器(一):原来是这么一回事》后对本文进行阅读,本文在内容上尽量不与前文重复。
准备
在进入对VAE的描述之前,我觉得有必要把一些概念性的内容讲一下。
15
Apr
基于CNN的阅读理解式问答模型:DGCNN
By 苏剑林 | 2018-04-15 | 416284位读者 | 引用2019.08.20更新:开源了一个Keras版(https://kexue.fm/archives/6906)
早在年初的《Attention is All You Need》的介绍文章中就已经承诺过会分享CNN在NLP中的使用心得,然而一直不得其便。这几天终于下定决心来整理一下相关的内容了。
背景
事不宜迟,先来介绍一下模型的基本情况。
模型特点
本模型——我称之为DGCNN——是基于CNN和简单的Attention的模型,由于没有用到RNN结构,因此速度相当快,而且是专门为这种WebQA式的任务定制的,因此也相当轻量级。SQUAD排行榜前面的模型,如AoA、R-Net等,都用到了RNN,并且还伴有比较复杂的注意力交互机制,而这些东西在DGCNN中基本都没有出现。
这是一个在GTX1060上都可以几个小时训练完成的模型!

截止到2018.04.14的排行榜
DGCNN,全名为Dilate Gated Convolutional Neural Network,即“膨胀门卷积神经网络”,顾名思义,融合了两个比较新的卷积用法:膨胀卷积、门卷积,并增加了一些人工特征和trick,最终使得模型在轻、快的基础上达到最佳的效果。在本文撰写之时,本文要介绍的模型还位于榜首,得分(得分是准确率与F1的平均)为0.7583,而且是到目前为止唯一一个一直没有跌出前三名、并且获得周冠军次数最多的模型。
16
Mar
现在可以用Keras玩中文GPT2了(GPT2_ML)
By 苏剑林 | 2020-03-16 | 88108位读者 | 引用前段时间留意到有大牛开源了一个中文的GPT2模型,是最大的15亿参数规模的,看作者给的demo,生成效果还是蛮惊艳的,就想着加载到自己的bert4keras来玩玩。不过早期的bert4keras整体架构写得比较“死”,集成多个不同的模型很不方便。前两周终于看不下去了,把bert4keras的整体结构重写了一遍,现在的bert4keras总能算比较灵活地编写各种Transformer结构的模型了,比如GPT2、T5等都已经集成在里边了。
GPT2科普
GPT,相信很多读者都听说过它了,简单来说,它就是一个基于Transformer结构的语言模型,源自论文《GPT:Improving Language Understanding by Generative Pre-Training》,但它又不是为了做语言模型而生,它是通过语言模型来预训练自身,然后在下游任务微调,提高下游任务的表现。它是“Transformer + 预训练 + 微调”这种模式的先驱者,相对而言,BERT都算是它的“后辈”,而GPT2,则是GPT的升级版——模型更大,训练数据更多——模型最大版的参数量达到了15亿。
3
Apr
变分自编码器(三):这样做为什么能成?
By 苏剑林 | 2018-04-03 | 176407位读者 | 引用话说我觉得我自己最近写文章都喜欢长篇大论了,而且扎堆地来~之前连续写了三篇关于Capsule的介绍,这次轮到VAE了,本文是VAE的第三篇探索,说不准还会有第四篇~不管怎么样,数量不重要,重要的是能把问题都想清楚。尤其是对于VAE这种新奇的建模思维来说,更加值得细细地抠。
这次我们要关心的一个问题是:VAE为什么能成?
估计看VAE的读者都会经历这么几个阶段。第一个阶段是刚读了VAE的介绍,然后云里雾里的,感觉像自编码器又不像自编码器的,反复啃了几遍文字并看了源码之后才知道大概是怎么回事;第二个阶段就是在第一个阶段的基础上,再去细读VAE的原理,诸如隐变量模型、KL散度、变分推断等等,细细看下去,发现虽然折腾来折腾去,最终居然都能看明白了。
这时候读者可能就进入第三个阶段了。在这个阶段中,我们会有诸多疑问,尤其是可行性的疑问:“为什么它这样反复折腾,最终出来模型是可行的?我也有很多想法呀,为什么我的想法就不行?”
前文之要
让我们再不厌其烦地回顾一下前面关于VAE的一些原理。
VAE希望通过隐变量分解来描述数据$X$的分布
$$p(x)=\int p(x|z)p(z)dz,\quad p(x,z) = p(x|z)p(z)\tag{1}$$
18
Apr
最小熵原理(一):无监督学习的原理
By 苏剑林 | 2018-04-18 | 80627位读者 | 引用话在开头
在深度学习等端到端方案已经逐步席卷NLP的今天,你是否还愿意去思考自然语言背后的基本原理?我们常说“文本挖掘”,你真的感受到了“挖掘”的味道了吗?
无意中的邂逅
前段时间看了一篇关于无监督句法分析的文章,继而从它的参考文献中发现了论文《Redundancy Reduction as a Strategy for Unsupervised Learning》,这篇论文介绍了如何从去掉空格的英文文章中将英文单词复原。对应到中文,这不就是词库构建吗?于是饶有兴致地细读了一番,发现论文思路清晰、理论完整、结果漂亮,让人赏心悦目。
尽管现在看来,这篇论文的价值不是很大,甚至其结果可能已经被很多人学习过了,但是要注意:这是一篇1993年的论文!在PC机还没有流行的年代,就做出了如此前瞻性的研究。虽然如今深度学习流行,NLP任务越做越复杂,这确实是一大进步,但是我们对NLP原理的真正了解,还不一定超过几十年前的前辈们多少。
这篇论文是通过“去冗余”(Redundancy Reduction)来实现无监督地构建词库的,从信息论的角度来看,“去冗余”就是信息熵的最小化。无监督句法分析那篇文章也指出“信息熵最小化是无监督的NLP的唯一可行的方案”。我进而学习了一些相关资料,并且结合自己的理解思考了一番,发现这个评论确实是耐人寻味。我觉得,不仅仅是NLP,信息熵最小化很可能是所有无监督学习的根本。
24
Apr
最小熵原理(二):“当机立断”之词库构建
By 苏剑林 | 2018-04-24 | 76873位读者 | 引用在本文,我们介绍“套路宝典”第一式——“当机立断”:1、导出平均字信息熵的概念,然后基于最小熵原理推导出互信息公式;2、并且完成词库的无监督构建、给出一元分词模型的信息熵诠释,从而展示有关生成套路、识别套路的基本方法和技巧。
这既是最小熵原理的第一个使用案例,也是整个“套路宝典”的总纲。
你练或者不练,套路就在那里,不增不减。
为什么需要词语
从上一篇文章可以看到,假设我们根本不懂中文,那么我们一开始会将中文看成是一系列“字”随机组合的字符串,但是慢慢地我们会发现上下文是有联系的,它并不是“字”的随机组合,它应该是“套路”的随机组合。于是为了减轻我们的记忆成本,我们会去挖掘一些语言的“套路”。第一个“套路”,是相邻的字之间的组合定式,这些组合定式,也就是我们理解的“词”。
平均字信息熵
假如有一批语料,我们将它分好词,以词作为中文的单位,那么每个词的信息量是$-\log p_w$,因此我们就可以计算记忆这批语料所要花费的时间为
$$-\sum_{w\in \text{语料}}\log p_w\tag{2.1}$$
这里$w\in \text{语料}$是对语料逐词求和,不用去重。如果不分词,按照字来理解,那么需要的时间为
$$-\sum_{c\in \text{语料}}\log p_c\tag{2.2}$$
11
May
【致敬】费曼诞辰100年
By 苏剑林 | 2018-05-11 | 29435位读者 | 引用
18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 307790位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
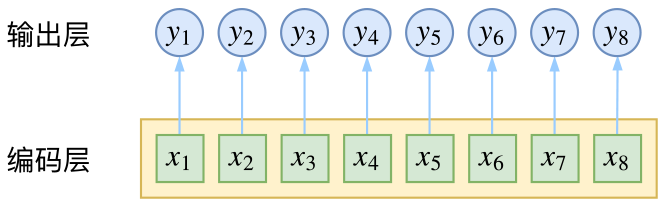
逐帧softmax并没有直接考虑输出的上下文关联

最近评论