






7
Aug
修改Transformer结构,设计一个更快更好的MLM模型
By 苏剑林 | 2020-08-07 | 51367位读者 | 引用大家都知道,MLM(Masked Language Model)是BERT、RoBERTa的预训练方式,顾名思义,就是mask掉原始序列的一些token,然后让模型去预测这些被mask掉的token。随着研究的深入,大家发现MLM不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载BERT的MLM权重就可以当作UniLM来做Seq2Seq任务(参考这里),又比如发表在ACL 2020的《Spelling Error Correction with Soft-Masked BERT》将MLM模型用于文本纠错。
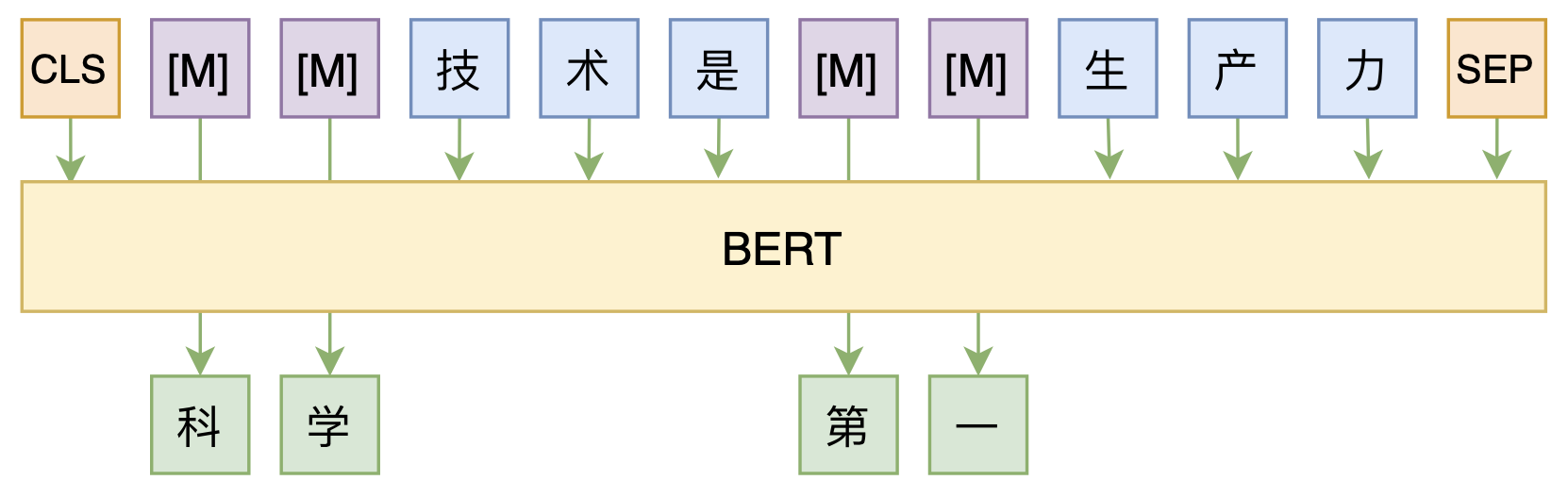
MLM任务示意图
然而,仔细读过BERT的论文或者亲自尝试过的读者应该都知道,原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练。ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。
20
Aug
最小熵原理(六):词向量的维度应该怎么选择?
By 苏剑林 | 2020-08-20 | 96885位读者 | 引用随着NLP的发展,像Word2Vec、Glove这样的词向量模型,正逐渐地被基于Transformer的BERT等模型代替,不过经典始终是经典,词向量模型依然在不少场景发光发热,并且仍有不少值得我们去研究的地方。本文我们来关心一个词向量模型可能有的疑惑:词向量的维度大概多少才够?
先说结论,笔者给出的估算结果是
\begin{equation}n > 8.33\log N\label{eq:final}\end{equation}
更简约的话可以直接记$n > 8\log N$,其中$N$是词表大小,$n$就是词向量维度,$\log$是自然对数。当$n$超过这个阈值时,就说明模型有足够的容量容纳这$N$个词语(当然$n$越大过拟合风险也越大)。这样一来,当$N=100000$时,得到的$n$大约是96,所以对于10万个词的词向量模型来说,维度选择96就足够了;如果要容纳500万个词,那么$n$大概就是128。
4
Dec
层次分解位置编码,让BERT可以处理超长文本
By 苏剑林 | 2020-12-04 | 114868位读者 | 引用大家都知道,目前的主流的BERT模型最多能处理512个token的文本。导致这一瓶颈的根本原因是BERT使用了从随机初始化训练出来的绝对位置编码,一般的最大位置设为了512,因此顶多只能处理512个token,多出来的部分就没有位置编码可用了。当然,还有一个重要的原因是Attention的$\mathcal{O}(n^2)$复杂度,导致长序列时显存用量大大增加,一般显卡也finetune不了。
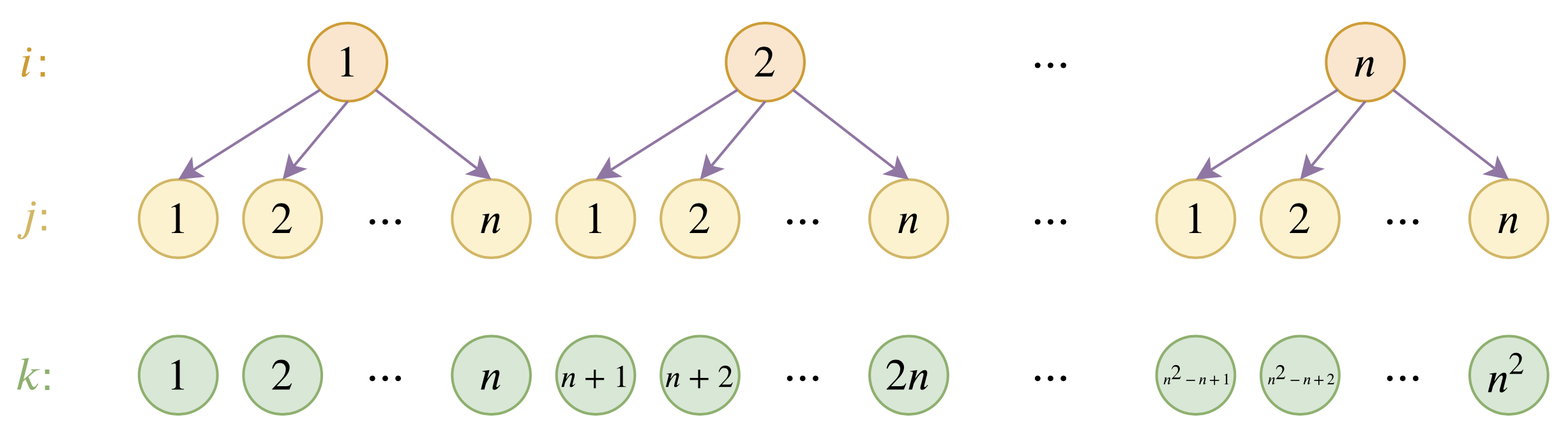
位置编码的层次分解示意图
本文主要面向前一个原因,即假设有足够多的显存前提下,如何简单修改当前最大长度为512的BERT模型,使得它可以直接处理更长的文本,主要思路是层次分解已经训练好的绝对位置编码,使得它可以延拓到更长的位置。
14
Jan
【搜出来的文本】⋅(二)从MCMC到模拟退火
By 苏剑林 | 2021-01-14 | 48785位读者 | 引用在上一篇文章中,我们介绍了“受限文本生成”这个概念,指出可以通过量化目标并从中采样的方式来无监督地完成某些带条件的文本生成任务。同时,上一篇文章还介绍了“重要性采样”和“拒绝采样”两个方法,并且指出对于高维空间而言,它们所依赖的易于采样的分布往往难以设计,导致它们难以满足我们的采样需求。
此时,我们就需要引入采样界最重要的算法之一“Markov Chain Monte Carlo(MCMC)”方法了,它将马尔可夫链和蒙特卡洛方法结合起来,使得(至少理论上是这样)我们从很多高维分布中进行采样成为可能,也是后面我们介绍的受限文本生成应用的重要基础算法之一。本文试图对它做一个基本的介绍。
马尔可夫链
马尔可夫链实际上就是一种“无记忆”的随机游走过程,它以转移概率$p(\boldsymbol{y}\leftarrow\boldsymbol{x})$为基础,从一个初始状态$\boldsymbol{x}_0$出发,每一步均通过该转移概率随机选择下一个状态,从而构成随机状态列$\boldsymbol{x}_0, \boldsymbol{x}_1, \boldsymbol{x}_2, \cdots, \boldsymbol{x}_t, \cdots $,我们希望考察对于足够大的步数$t$,$\boldsymbol{x}_t$所服从的分布,也就是该马尔可夫链的“平稳分布”。
9
Feb
一个二值化词向量模型,是怎么跟果蝇搭上关系的?
By 苏剑林 | 2021-02-09 | 25725位读者 | 引用
果蝇(图片来自Google搜索)
可能有些读者最近会留意到ICLR 2021的论文《Can a Fruit Fly Learn Word Embeddings?》,文中写到它是基于仿生思想(仿果蝇的嗅觉回路)做出来的一个二值化词向量模型。其实论文的算法部分并不算难读,可能整篇论文读下来大家的最主要疑惑就是“这东西跟果蝇有什么关系?”、“作者真是从果蝇里边受到启发的?”等等。本文就让我们来追寻一下该算法的来龙去脉,试图回答一下这个词向量模型是怎么跟果蝇搭上关系的。
BioWord
原论文并没有给该词向量模型起个名字,为了称呼上的方便,这里笔者就自作主张将其称为“BioWord”了。总的来说,论文内容大体上有三部分:
1、给每个n-gram构建了一个词袋表示向量;
2、对这些n-gram向量执行BioHash算法,得到所谓的(二值化的)静态/动态词向量;
3、“拼命”讲了一个故事。
22
Jan
【搜出来的文本】⋅(三)基于BERT的文本采样
By 苏剑林 | 2021-01-22 | 80039位读者 | 引用从这一篇开始,我们就将前面所介绍的采样算法应用到具体的文本生成例子中。而作为第一个例子,我们将介绍如何利用BERT来进行文本随机采样。所谓文本随机采样,就是从模型中随机地产生一些自然语言句子出来,通常的观点是这种随机采样是GPT2、GPT3这种单向自回归语言模型专有的功能,而像BERT这样的双向掩码语言模型(MLM)是做不到的。
事实真的如此吗?当然不是。利用BERT的MLM模型其实也可以完成文本采样,事实上它就是上一篇文章所介绍的Gibbs采样。这一事实首先由论文《BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model》明确指出。论文的标题也颇为有趣:“BERT也有嘴巴,所以它得说点什么。”现在就让我们看看BERT究竟能说出什么来~
9
Oct
关于WhiteningBERT原创性的疑问和沟通
By 苏剑林 | 2021-10-09 | 64090位读者 | 引用在文章《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》中,笔者受到BERT-flow的启发,提出了一种名为BERT-whitening的替代方案,它比BERT-flow更简单,但多数数据集下能取得相近甚至更好的效果,此外它还可以用于对句向量降维以提高检索速度。后来,笔者跟几位合作者一起补充了BERT-whitening的实验,并将其写成了英文论文《Whitening Sentence Representations for Better Semantics and Faster Retrieval》,在今年3月29日发布在Arxiv上。
然而,大约一周后,一篇名为《WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach》的论文 (下面简称WhiteningBERT)出现在Arxiv上,内容跟BERT-whitening高度重合,有读者看到后向我反馈WhiteningBERT抄袭了BERT-whitening。本文跟关心此事的读者汇报一下跟WhiteningBERT的作者之间的沟通结果。
时间节点
首先,回顾一下BERT-whitening的相关时间节点,以帮助大家捋一下事情的发展顺序:
25
Feb
【搜出来的文本】⋅(四)通过增、删、改来用词造句
By 苏剑林 | 2021-02-25 | 45424位读者 | 引用“用词造句”是小学阶段帮助我们理解和运用词语的一个经典任务,从自然语言处理的角度来看,它是一个句子扩写或者句子补全任务,它其实要求我们具有不定向地进行文本生成的能力。然而,当前主流的语言模型都是单方向生成的(多数是正向的,即从左往右,少数是反向的,即从右往左),但用词造句任务中所给的若干个词未必一定出现在句首或者句末,这导致无法直接用语言模型来完成造句任务。
本文我们将介绍论文《CGMH: Constrained Sentence Generation by Metropolis-Hastings Sampling》,它使用MCMC采样使得单向语言模型也可以做到不定向生成,通过增、删、改操作模拟了人的写作润色过程,从而能无监督地完成用词造句等多种文本生成任务。
问题设置
无监督地进行文本采样,那么直接可以由语言模型来完成,而我们同样要做的,是往这个采样过程中加入一些信号$\boldsymbol{c}$,使得它能生成我们期望的一些文本。在本系列第一篇文章《【搜出来的文本】⋅(一)从文本生成到搜索采样》的“明确目标”一节中,我们就介绍了本系列的指导思想:把我们要寻找的目标量化地写下来,然后最大化它或者从中采样。

最近评论