






24
Oct
行星密度与其公转周期(更新)
By 苏剑林 | 2012-10-24 | 24920位读者 | 引用===我与《天文爱好者》不得不说的故事===
去年在订阅2012年的《天文爱好者》时,考虑到之后就要上大学了,所以只是订了半年,因此过了今年六月我就没有看新的《天文爱好者》了。暑假的两个月,还有九月、十月,将近四个月没有看它了,我本以为我已经适应了没有天爱的日子。
大概一个星期前,我在天爱的淘宝网重新买了最近四个月的《天文爱好者》,18日下午,我再见了它。那天晚上,我突然觉得很感动,有种感慨万千的感觉。虽然这么久没有看了,但是再看的感觉是如此的熟悉,如此的温馨。我原来觉得天文只是我的一个业余兴趣,如同生物化学那样,但在那瞬间我明白了我真的爱着天文,而且时间和空间的距离并不能减少我的爱!在那时,我决定了,我一定要从事天文相关专业——虽然我只是一个数学系学生!
==========行星周期下限==========
(2012.10.25:zwhzjh提出攝动力公式有错误,修正了攝动力的计算公式,之前写少了一个因子2,还有在最后的实际检验时,为了追求结果的合理性,忽略了方法的科学性,现在已经进行了修正,欢迎各位提更多意见。)

首颗被发现的系外行星
本文要探讨的东西是我在阅读《天文爱好者》的时候偶然发现的。在发现系外行星以前,人们通常都认为像木星这样的气态巨行星,公转周期都应该在十年以上。因此当瑞士天文学家米歇尔·迈耶和迪戴尔·邱洛兹发现第一颗系外行星时,他们简直无法确信自己的发现,因为这颗类木行星的公转周期只有短短的4.2天!但是经过确认,这的确是一颗系外行星,颠覆了过去的看法。我饶有兴致地研究下去,企图推导出某一密度行星的公转周期下限。
各位读者不妨先估计一下,它会与什么物理量有关?行星质量?母星质量?还是...?
26
Sep
数学基本技艺(A Mathematical Trivium)
By 苏剑林 | 2013-09-26 | 24688位读者 | 引用这是Arnold给物理系学生出的基础数学题。原文是Arnold于1991年,在Russian Math Surveys 46:1(1991),271-278上发的一篇文章,英文名叫 A mathematical trivium,这篇文章是有个前言的,用两页纸的内容吐槽了1991年的学生数学学得很烂,尤其是物理系的。文后附了100道数学题,号称是物理系学生的数学底线。
这是给物理系出的数学题,所以和一般的数学竞赛题目不同,没太多证明题,主要就是计算和解模型,而且还有不少近似估算的,带有明显的物理风格。虽然作者说这是物理系学生数学的底线,但即使对于数学系的学生来说,这些题目还是有不少难度的。网络也有一些题目的答案,但是都比较零散。在这里与大家分享一下题目。什么时候有时间了,或者刚好碰到类似的研究,我也会把题目做做,与各位分享。希望有兴趣的朋友做了之后也把答案与大家交流呀。

1
2
Jul
[追溯]封装界传奇人物
By 苏剑林 | 2014-07-02 | 19546位读者 | 引用转载理由:现在的deepin和ylmf(已经改为StartOs)都已经在制作自己的Linux,而当初它们都是制作GhostXp的大家。我的初中,即2009年以前,是GhostXP流行的时代,而我当时也加入了这一行列中,发表过一些GhostXP的作品。后来随着时代的发展,XP也就慢慢退出了舞台。我也就随之退出了这个舞台,也因此得以专注科学。但是,几乎所有我的电脑知识,都积累于那个时期,因为为了完成一个系统的制作和推广,需要懂得的电脑技术很多很多,我也得到了充分的锻炼。下面列举的一些人,都是当年GhostXP界的神话人物,有些我并不认识,但其名在当时就如雷贯耳;有些人在当时还十分幸运地加上了他们的QQ。这篇文章实际上已经是很久已经的了,但还是值得回味过去的时间,以此为我的初中时代留下一些回忆。
6
May
记录一次爬取淘宝/天猫评论数据的过程
By 苏剑林 | 2015-05-06 | 172765位读者 | 引用笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行。对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了。本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似的做法,不赘述。主要是分析页面以及用Python实现简单方便的抓取。
笔者使用的工具如下
Python 3——极其方便的编程语言。选择3.x的版本是因为3.x对中文处理更加友好。
Pandas——Python的一个附加库,用于数据整理。
IE 11——分析页面请求过程(其他类似的流量监控工具亦可)。
剩下的还有requests,re,这些都是Python自带的库。
实例页面(美的某热水器):http://detail.tmall.com/item.htm?id=41464129793
22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 230352位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
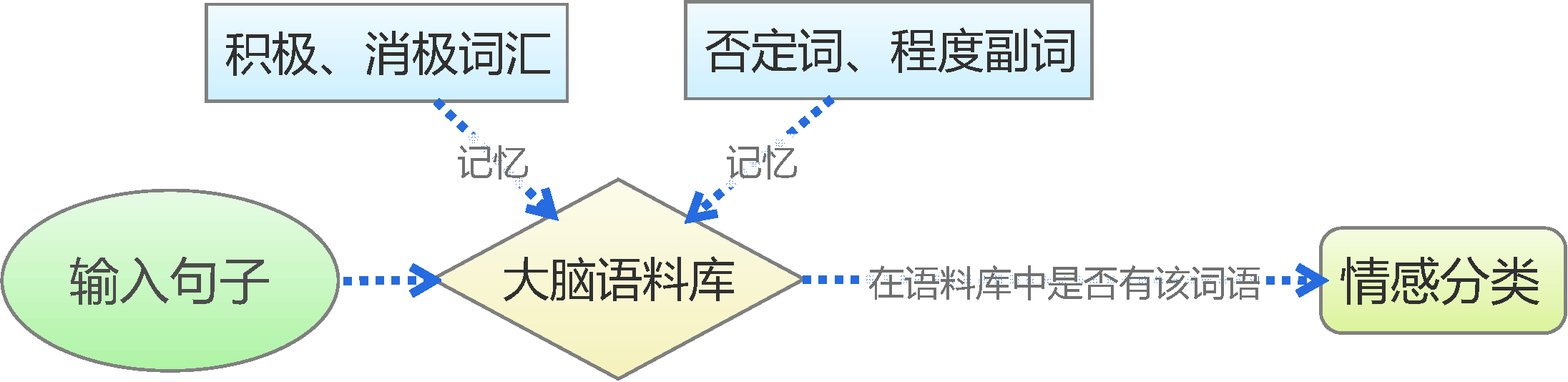
人的最简单的判断思维
15
Jul
漫话模型|模型与选芒果
By 苏剑林 | 2015-07-15 | 38919位读者 | 引用很多人觉得“模型”、“大数据”、“机器学习”这些字眼很高大很神秘,事实上,它跟我们生活中选水果差不了多少。本文用了几千字,来试图教会大家怎么选芒果...
模型的比喻

芒果
假如我要从一批芒果中,找出好吃的那个来。而我不能直接切开芒果尝尝,所以我只能观察芒果,能观察到的量有颜色、表面的气味、大小等等,这些就是我们能够收集到的信息(特征)。
生活中还要很多这样的例子,比如买火柴(可能年轻的城里人还没见过火柴?),如何判断一盒火柴的质量?难道要每根火柴都划划,看看着不着火?显然不行,我们最多也只能划几根,全部划了,火柴也不成火柴了。当然,我们还能看看火柴的样子,闻闻火柴的气味,这些动作是可以接受的。
4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 616031位读者 | 引用
6
Dec


最近评论