






23
Feb
SVD分解(三):连Word2Vec都只不过是个SVD?
By 苏剑林 | 2017-02-23 | 96103位读者 | 引用这篇文章要带来一个“重磅”消息,如标题所示,居然连大名鼎鼎的深度学习词向量工具Word2Vec都只不过是个SVD!
当然,Word2Vec的超级忠实粉丝们,你们也不用太激动,这里只是说模型结构上是等价的,并非完全等价,Word2Vec还是有它的独特之处。只不过,经过我这样解释之后,估计很多问题就可以类似想通了。
词向量=one hot
让我们先来回顾一下去年的一篇文章《词向量与Embedding究竟是怎么回事?》,这篇文章主要说的是:所谓Embedding层,就是一个one hot的全连接层罢了(再次强调,这里说的完全等价,而不是“相当于”),而词向量,就是这个全连接层的参数;至于Word2Vec,就通过大大简化的语言模型来训练Embedding层,从而得到词向量(它的优化技巧有很多,但模型结构就只是这么简单);词向量能够减少过拟合风险,是因为用Word2Vec之类的工具、通过大规模语料来无监督地预训练了这个Embedding层,而跟one hot还是Embedding还是词向量本身没啥关系。
有了这个观点后,马上可以解释我们以前的一个做法为什么可行了。在做情感分类问题时,如果有了词向量,想要得到句向量,最简单的一个方案就是直接对句子中的词语的词向量求和或者求平均,这约能达到85%的准确率。事实上这也是facebook出品的文本分类工具FastText的做法了(FastText还多引入了ngram特征,来缓解词序问题,但总的来说,依旧是把特征向量求平均来得到句向量)。为什么这么一个看上去毫不直观的、简单粗暴的方案也能达到这么不错的准确率?
14
Mar
泰迪杯赛前培训之数据挖掘与建模“慢谈”
By 苏剑林 | 2017-03-14 | 32524位读者 | 引用
泰迪杯赛前培训
应广州泰迪科技公司之邀,给泰迪杯数据挖掘竞赛录制了赛前培训视频,内容基本上是各种常见的数学模型及入门用法,以一种比较独特的思路,将朴素贝叶斯、HMM、逻辑回归、组合模型、神经网络、深度学习等等串了起来。视频讲解难度为入门级,当然,真的要融合贯通所有内容,恐怕要骨灰级。
不管怎么样,简单分享一下,欢迎大家留言讨论、建议甚至批评。
PPT下载:泰迪杯赛前培训ppt.zip
17
May
如何“扒”站?手把手教你爬百度百科~
By 苏剑林 | 2017-05-17 | 33276位读者 | 引用
8
Aug
【备忘】谈谈dropout
By 苏剑林 | 2017-08-08 | 33563位读者 | 引用其实这只是一篇备忘...
dropout是深度学习中防止过拟合的一项有效措施,当然,就其思想而言,dropout其实也不仅仅可以用在深度学习中,还可以用在传统的机器学习方法中,只不过在深度学习的神经网络框架下,dropout显得更为自然罢了。
做了什么
dropout是怎么操作的?一般来做,对于输入的张量$x$,dropout就是将部分元素置零,然后将置零后的结果做一个尺度变换。具体来说,以Keras的Dropout(0.6)(x)为例,实际上等价于numpy做的这件事情
import numpy as np
x = np.random.random((10,100)) #模拟一个batch_size=10、维度为100的输入
def Dropout(x, drop_proba):
return x*np.random.choice(
[0,1],
x.shape,
p=[drop_proba,1-drop_proba]
)/(1.-drop_proba)
print Dropout(x, 0.6)
3
Jul
《交换代数导引》参考答案
By 苏剑林 | 2017-07-03 | 35547位读者 | 引用这学期我们的一门课是《交换代数》,是本科抽象代数的升级版。我们用的教材是Atiyah的《Introduction to Commutative Algebra》(交换代数导引),而且根据老师的上课安排,还需要我们把部分课后习题完成并讲解...不得不说这门课上得真累啊~
习题做到后面,我干脆懒得起草稿了,直接把做的答案用LaTeX录入了,既方便排版也方便修改。在这里分享给有需要的读者~答案是用中文写的,注释比较详细,适合刚学这门课的同学~
笔者所做的部分:《交换代数导引》参考答案.pdf
当然这份答案只包括老师对我们的要求的那部分习题,下面是网上搜索到的完整的习题解答,英文版的:
网上找到的答案:Jeffrey Daniel Kasik Carlson - Exercises to Atiya.pdf
如果答案有问题,欢迎留言指出。
6
Oct
从马尔科夫过程到主方程(推导过程)
By 苏剑林 | 2017-10-06 | 74417位读者 | 引用主方程(master equation)是对随机过程进行建模的重要方法,它代表着马尔科夫过程的微分形式,我们的专业主要工具之一就是主方程,说宏大一点,量子力学和统计力学等也不外乎是主方程的一个特例。
然而,笔者阅读了几个著作,比如《统计物理现代教程》,还有我导师的《生物系统的随机动力学》,我发现这些著作对于主方程的推导都很模糊,他们在着力解释结果的意义,但并不说明结果的思想来源,因此其过程难以让人信服。而知乎上有人提问《如何理解马尔科夫过程的主方程的推导过程?》但没有得到很好的答案,也表明了这个事实。
马尔可夫过程
主方程是用来描述马尔科夫过程的,而马尔科夫过程可以理解为运动的无记忆性,说通俗点,就是下一刻的概率分布,只跟当前时刻有关,跟历史状态无关。用概率公式写出来就是(这里只考虑连续型概率,因此这里的$p$是概率密度):
$$\begin{equation}\label{eq:maerkefu}p(x,\tau)=\int p(x,\tau|y,t) p(y,t) dy\end{equation}$$
这里的积分区域是全空间。这里的$p(x,\tau|y,t)$称为跃迁概率,即已经确定了$t$时刻来到了$y$位置后、在$\tau$时刻达到$x$的概率密度,这个式子的物理意义是很明显的,就不多做解释了。
23
Jan
分享一个slide:花式自然语言处理
By 苏剑林 | 2018-01-23 | 82670位读者 | 引用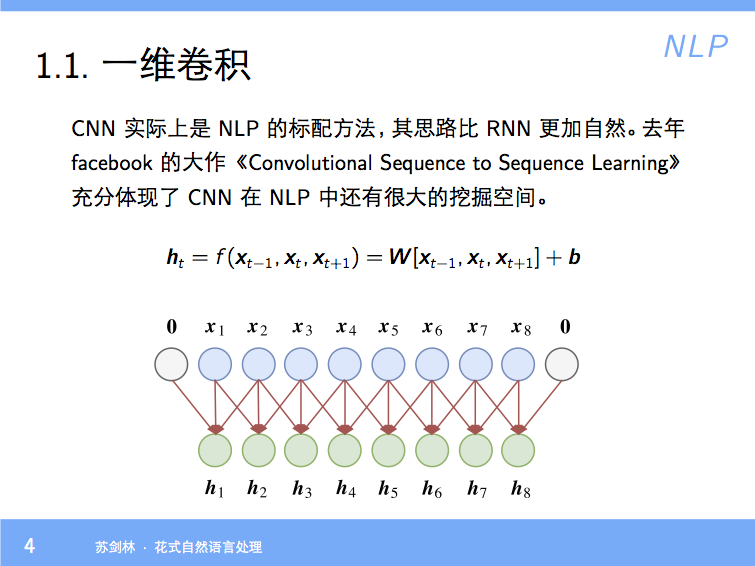
30
Jan
【分享】千万级百度知道语料
By 苏剑林 | 2018-01-30 | 82694位读者 | 引用发布
2018年01月30日
数目
共1千万条
格式
[
{
"url": "http://zhidao.baidu.com/question/565618371557484884.html",
"question": "学文员有哪些专科学校",
"tags": [
"学校",
"专科",
"院校信息"
]
},
{
"url": "http://zhidao.baidu.com/question/2079794100345438428.html",
"question": "网赌和澳门赌有区别吗",
"tags": [
"网络",
"澳门",
"赌博"
]
}
]
最近评论