






13
Oct
基于fine tune的图像分类(百度分狗竞赛)
By 苏剑林 | 2017-10-13 | 27555位读者 | 引用
baidu_jingsai
前两年百度的大数据竞赛都是自然语言处理方面的,今年画风一转,变成了图像的细颗粒度分类,赛题内容就是将宠物狗归为100类中的其中一类。这个任务本身是很平凡的,做法也很常规,无外乎就是数据扩增、imagenet模型的fine tune、模型集成三个方面。笔者并不擅长于模型集成,只做了前面两个步骤,成绩也非常一般(准确率80%上下)。但感觉里边的某些代码可能对读者有帮助,遂共享一翻。下面结合着代码来讲解。
比赛官网(随时有失效的可能):http://js.baidu.com
模型
模型主要用tensorflow+keras实现。首先自然是导入各种模块
#! -*- coding:utf-8 -*-
import numpy as np
from scipy import misc
import tensorflow as tf
from keras.applications.xception import Xception,preprocess_input
from keras.layers import Input,Dense,Lambda,Embedding
from keras.layers.merge import multiply
from keras import backend as K
from keras.models import Model
from keras.optimizers import SGD
from tqdm import tqdm
import glob
np.random.seed(2017)
tf.set_random_seed(2017)
15
Feb
能量视角下的GAN模型(二):GAN=“分析”+“采样”
By 苏剑林 | 2019-02-15 | 124871位读者 | 引用在这个系列中,我们尝试从能量的视角理解GAN。我们会发现这个视角如此美妙和直观,甚至让人拍案叫绝。
上一篇文章里,我们给出了一个直白而用力的能量图景,这个图景可以让我们轻松理解GAN的很多内容,换句话说,通俗的解释已经能让我们完成大部分的理解了,并且把最终的结论都已经写了出来。在这篇文章中,我们继续从能量的视角理解GAN,这一次,我们争取把前面简单直白的描述,用相对严密的数学语言推导一遍。
跟第一篇文章一样,对于笔者来说,这个推导过程依然直接受启发于Bengio团队的新作《Maximum Entropy Generators for Energy-Based Models》。
原作者的开源实现:https://github.com/ritheshkumar95/energy_based_generative_models
本文的大致内容如下:
1、推导了能量分布下的正负相对抗的更新公式;
2、比较了理论分析与实验采样的区别,而将两者结合便得到了GAN框架;
3、导出了生成器的补充loss,理论上可以防止mode collapse;
4、简单提及了基于能量函数的MCMC采样。
10
Apr
分享一次专业领域词汇的无监督挖掘
By 苏剑林 | 2019-04-10 | 81056位读者 | 引用去年 Data Fountain 曾举办了一个“电力专业领域词汇挖掘”的比赛,该比赛有意思的地方在于它是一个“无监督”的比赛,也就是说它考验的是从大量的语料中无监督挖掘专业词汇的能力。
这个显然确实是工业界比较有价值的一个能力,又想着我之前也在无监督新词发现中做过一定的研究,加之“无监督比赛”的新颖性,所以当时毫不犹豫地参加了,然而最终排名并不靠前~
不管怎样,还是分享一下我自己的做法,这是一个真正意义上的无监督做法,也许会对部分读者有些参考价值。
基准对比
首先,新词发现部分,用到了我自己写的库nlp zero,基本思路是先分别对“比赛所给语料”、“自己爬的一部分百科百科语料”做新词发现,然后两者进行对比,就能找到一批“比赛所给语料”的特征词。
13
Nov
n维空间下两个随机向量的夹角分布
By 苏剑林 | 2019-11-13 | 125008位读者 | 引用昨天群里大家讨论到了$n$维向量的一些反直觉现象,其中一个话题是“一般$n$维空间下两个随机向量几乎都是垂直的”,这就跟二维/三维空间的认知有明显出入了。要从理论上认识这个结论,我们可以考虑两个随机向量的夹角$\theta$分布,并算算它的均值方差。
概率密度
首先,我们来推导$\theta$的概率密度函数。呃,其实也不用怎么推导,它是$n$维超球坐标的一个直接结论。
要求两个随机向量之间的夹角分布,很显然,由于各向同性,所以我们只需要考虑单位向量,而同样是因为各向同性,我们只需要固定其中一个向量,考虑另一个向量随机变化。不是一般性,考虑随机向量为
\begin{equation}\boldsymbol{x}=(x_1,x_2,\dots,x_n)\end{equation}
而固定向量为
\begin{equation}\boldsymbol{y}=(1,0,\dots,0)\end{equation}
11
Oct
BN究竟起了什么作用?一个闭门造车的分析
By 苏剑林 | 2019-10-11 | 109580位读者 | 引用BN,也就是Batch Normalization,是当前深度学习模型(尤其是视觉相关模型)的一个相当重要的技巧,它能加速训练,甚至有一定的抗过拟合作用,还允许我们用更大的学习率,总的来说颇多好处(前提是你跑得起较大的batch size)。
那BN究竟是怎么起作用呢?早期的解释主要是基于概率分布的,大概意思是将每一层的输入分布都归一化到$\mathcal{N}(0,1)$上,减少了所谓的Internal Covariate Shift,从而稳定乃至加速了训练。这种解释看上去没什么毛病,但细思之下其实有问题的:不管哪一层的输入都不可能严格满足正态分布,从而单纯地将均值方差标准化无法实现标准分布$\mathcal{N}(0,1)$;其次,就算能做到$\mathcal{N}(0,1)$,这种诠释也无法进一步解释其他归一化手段(如Instance Normalization、Layer Normalization)起作用的原因。
在去年的论文《How Does Batch Normalization Help Optimization?》里边,作者明确地提出了上述质疑,否定了原来的一些观点,并提出了自己关于BN的新理解:他们认为BN主要作用是使得整个损失函数的landscape更为平滑,从而使得我们可以更平稳地进行训练。
本博文主要也是分享这篇论文的结论,但论述方法是笔者“闭门造车”地构思的。窃认为原论文的论述过于晦涩了,尤其是数学部分太不好理解,所以本文试图尽可能直观地表达同样观点。
(注:阅读本文之前,请确保你已经清楚知道BN是什么,本文不再重复介绍BN的概念和流程。)
25
Apr
将“Softmax+交叉熵”推广到多标签分类问题
By 苏剑林 | 2020-04-25 | 311224位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
一般来说,在处理常规的多分类问题时,我们会在模型的最后用一个全连接层输出每个类的分数,然后用softmax激活并用交叉熵作为损失函数。在这篇文章里,我们尝试将“Softmax+交叉熵”方案推广到多标签分类场景,希望能得到用于多标签分类任务的、不需要特别调整类权重和阈值的loss。

类别不平衡
单标签到多标签
一般来说,多分类问题指的就是单标签分类问题,即从$n$个候选类别中选$1$个目标类别。假设各个类的得分分别为$s_1,s_2,
\dots,s_n$,目标类为$t\in\{1,2,\dots,n\}$,那么所用的loss为
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_{i=1}^n e^{s_i}}= - s_t + \log \sum\limits_{i=1}^n e^{s_i}\label{eq:log-softmax}\end{equation}
这个loss的优化方向是让目标类的得分$s_t$变为$s_1,s_2,\dots,s_t$中的最大值。关于softmax的相关内容,还可以参考《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等文章。
28
Jun
积分梯度:一种新颖的神经网络可视化方法
By 苏剑林 | 2020-06-28 | 85588位读者 | 引用本文介绍一种神经网络的可视化方法:积分梯度(Integrated Gradients),它首先在论文《Gradients of Counterfactuals》中提出,后来《Axiomatic Attribution for Deep Networks》再次介绍了它,两篇论文作者都是一样的,内容也大体上相同,后一篇相对来说更易懂一些,如果要读原论文的话,建议大家优先读后一篇。当然,它已经是2016~2017年间的工作了,“新颖”说的是它思路上的创新有趣,而不是指最近发表。

笔者在中文情感分类上对积分梯度的实验效果(越红的token越重要)
所谓可视化,简单来说就是对于给定的输入$x$以及模型$F(x)$,我们想办法指出$x$的哪些分量对模型的决策有重要影响,或者说对$x$各个分量的重要性做个排序,用专业的话术来说那就是“归因”。一个朴素的思路是直接使用梯度$\nabla_x F(x)$来作为$x$各个分量的重要性指标,而积分梯度是对它的改进。然而,笔者认为,很多介绍积分梯度方法的文章(包括原论文),都过于“生硬”(形式化),没有很好地突出积分梯度能比朴素梯度更有效的本质原因。本文试图用自己的思路介绍一下积分梯度方法。
4
Dec
层次分解位置编码,让BERT可以处理超长文本
By 苏剑林 | 2020-12-04 | 111058位读者 | 引用大家都知道,目前的主流的BERT模型最多能处理512个token的文本。导致这一瓶颈的根本原因是BERT使用了从随机初始化训练出来的绝对位置编码,一般的最大位置设为了512,因此顶多只能处理512个token,多出来的部分就没有位置编码可用了。当然,还有一个重要的原因是Attention的$\mathcal{O}(n^2)$复杂度,导致长序列时显存用量大大增加,一般显卡也finetune不了。
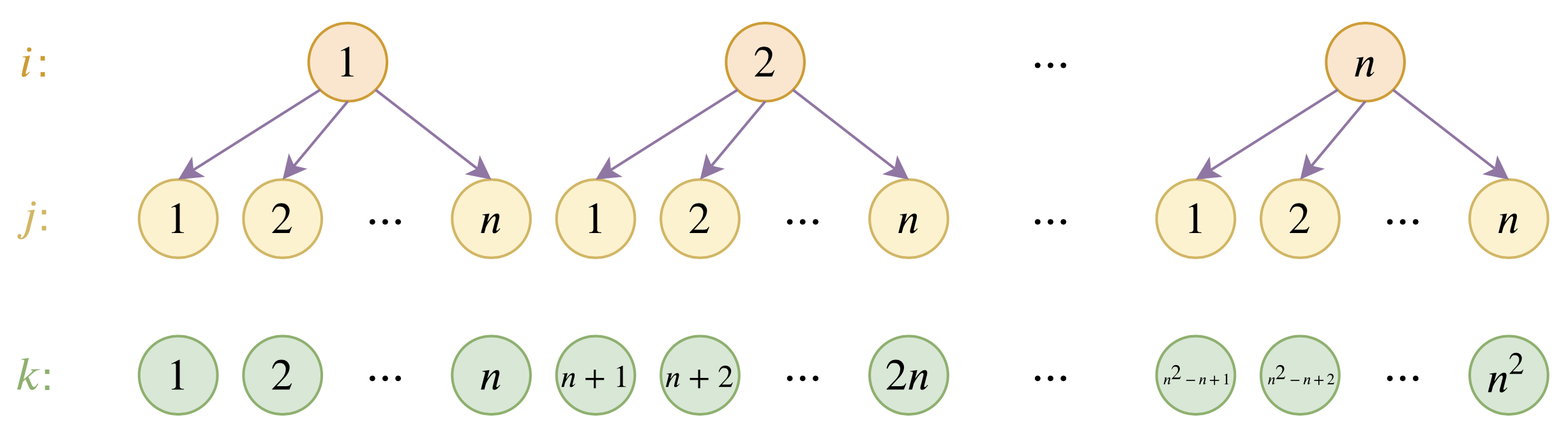
位置编码的层次分解示意图
本文主要面向前一个原因,即假设有足够多的显存前提下,如何简单修改当前最大长度为512的BERT模型,使得它可以直接处理更长的文本,主要思路是层次分解已经训练好的绝对位置编码,使得它可以延拓到更长的位置。

最近评论