






8
Oct
【NASA每日一图】撞击目标:凯布斯月球坑
By 苏剑林 | 2009-10-08 | 17742位读者 | 引用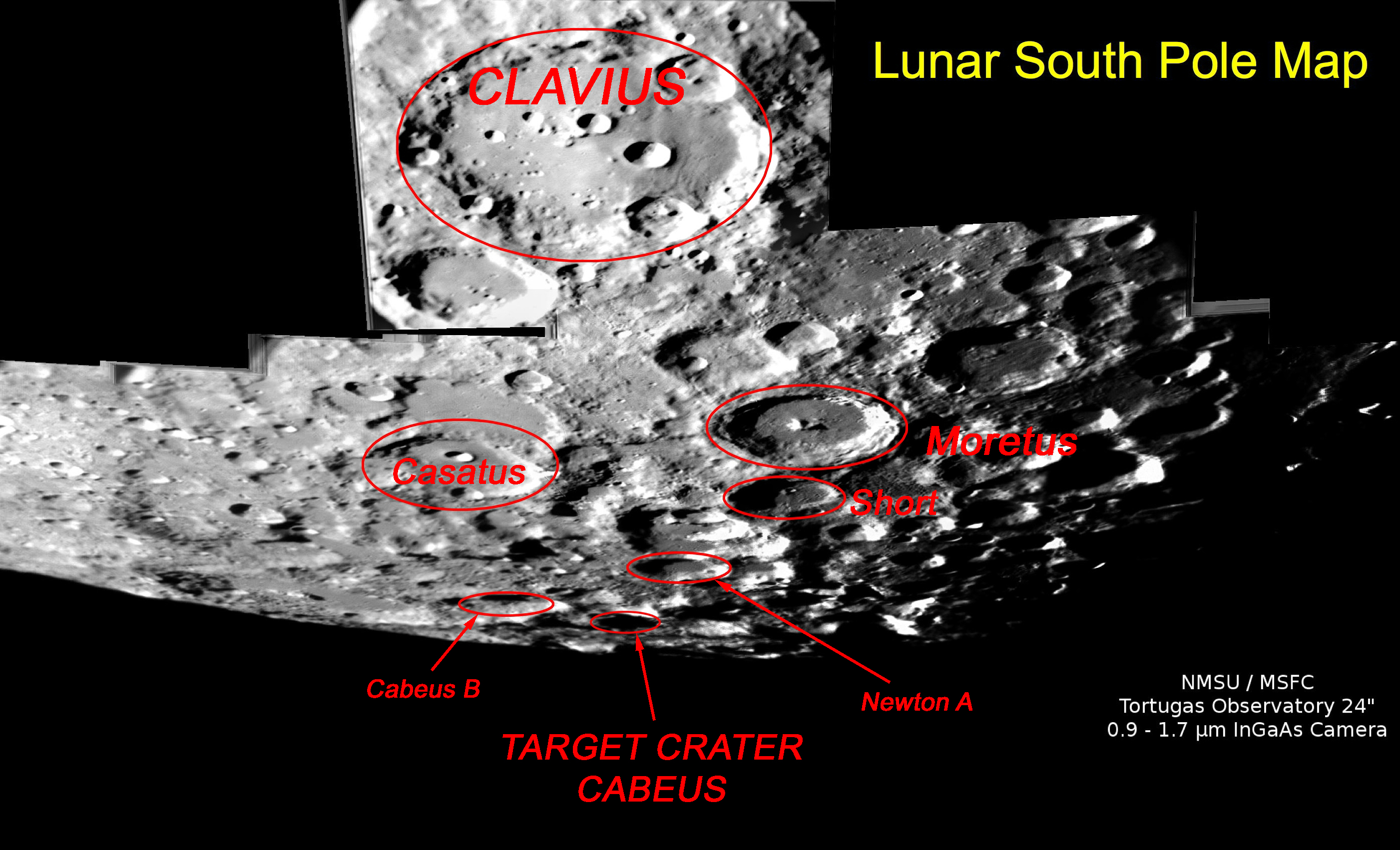
13
Oct
两名美国经济学家同获2009年诺贝尔经济学奖
By 苏剑林 | 2009-10-13 | 16834位读者 | 引用
20
Oct
世界最复杂的机器11月重启,温度宇宙最低
By 苏剑林 | 2009-10-20 | 16421位读者 | 引用
31
Oct
沉痛,默哀!中国科学巨星钱学森逝世
By 苏剑林 | 2009-10-31 | 22898位读者 | 引用
31
Oct
钱学森:人生书写时代
By 苏剑林 | 2009-10-31 | 18051位读者 | 引用
1
Nov
本站域名Spaces.Ac.Cn的PR为2了
By 苏剑林 | 2009-11-01 | 24243位读者 | 引用
3
Nov
美国科学家用3000幅照片拼接夜空全景
By 苏剑林 | 2009-11-03 | 17287位读者 | 引用
26
Oct
新词发现的信息熵方法与实现
By 苏剑林 | 2015-10-26 | 107922位读者 | 引用在本博客的前面文章中,已经简单提到过中文文本处理与挖掘的问题了,中文数据挖掘与英语同类问题中最大的差别是,中文没有空格,如果要较好地完成语言任务,首先得分词。目前流行的分词方法都是基于词库的,然而重要的问题就来了:词库哪里来?人工可以把一些常用的词语收集到词库中,然而这却应付不了层出不穷的新词,尤其是网络新词等——而这往往是语言任务的关键地方。因此,中文语言处理很核心的一个任务就是完善新词发现算法。
新词发现说的就是不加入任何先验素材,直接从大规模的语料库中,自动发现可能成词的语言片段。前两天我去小虾的公司膜拜,并且试着加入了他们的一个开发项目中,主要任务就是网络文章处理。因此,补习了一下新词发现的算法知识,参考了Matrix67.com的文章《互联网时代的社会语言学:基于SNS的文本数据挖掘》,尤其是里边的信息熵思想,并且根据他的思路,用Python写了个简单的脚本。

最近评论