






28
Apr
“让Keras更酷一些!”:中间变量、权重滑动和安全生成器
By 苏剑林 | 2019-04-28 | 84393位读者 | 引用继续“让Keras更酷一些”之旅。
今天我们会用Keras实现灵活地输出任意中间变量,还有无缝地进行权重滑动平均,最后顺便介绍一下生成器的进程安全写法。
首先是输出中间变量。在自定义层时,我们可能希望查看中间变量,这些需求有些是比较容易实现的,比如查看中间某个层的输出,只需要将截止到这个层的部分模型保存为一个新模型即可,但有些需求是比较困难的,比如在使用Attention层时我们可能希望查看那个Attention矩阵的值,如果用构建新模型的方法则会非常麻烦。而本文则给出一种简单的方法,彻底满足这个需求。
接着是权重滑动平均。权重滑动平均是稳定、加速模型训练甚至提升模型效果的一种有效方法,很多大型模型(尤其是GAN)几乎都用到了权重滑动平均。一般来说权重滑动平均是作为优化器的一部分,所以一般需要重写优化器才能实现它。本文介绍一个权重滑动平均的实现,它可以无缝插入到任意Keras模型中,不需要自定义优化器。
至于生成器的进程安全写法,则是因为Keras读取生成器的时候,用到了多进程,如果生成器本身也包含了一些多进程操作,那么可能就会导致异常,所以需要解决这个这个问题。
14
Dec
Mitchell近似:乘法变为加法,误差不超过1/9
By 苏剑林 | 2020-12-14 | 31113位读者 | 引用今天给大家介绍一篇1962年的论文《Computer Multiplication and Division Using Binary Logarithms》,作者是John N. Mitchell,他在里边提出了一个相当有意思的算法:在二进制下,可以完全通过加法来近似完成两个数的相乘,最大误差不超过1/9。整个算法相当巧妙,更有意思的是它还有着非常简洁的编程实现,让人拍案叫绝。然而,笔者发现网上居然找不到介绍这个算法的网页,所以在此介绍一番。
你以为这只是过时的玩意?那你就错了,前不久才有人利用它发了一篇NeurIPS 2020呢!所以,确定不来了解一下吗?
11
Jan
你可能不需要BERT-flow:一个线性变换媲美BERT-flow
By 苏剑林 | 2021-01-11 | 157746位读者 | 引用BERT-flow来自论文《On the Sentence Embeddings from Pre-trained Language Models》,中了EMNLP 2020,主要是用flow模型校正了BERT出来的句向量的分布,从而使得计算出来的cos相似度更为合理一些。由于笔者定时刷Arixv的习惯,早在它放到Arxiv时笔者就看到了它,但并没有什么兴趣,想不到前段时间小火了一把,短时间内公众号、知乎等地出现了不少的解读,相信读者们多多少少都被它刷屏了一下。
从实验结果来看,BERT-flow确实是达到了一个新SOTA,但对于这一结果,笔者的第一感觉是:不大对劲!当然,不是说结果有问题,而是根据笔者的理解,flow模型不大可能发挥关键作用。带着这个直觉,笔者做了一些分析,果不其然,笔者发现尽管BERT-flow的思路没有问题,但只要一个线性变换就可以达到相近的效果,flow模型并不是十分关键。
余弦相似度的假设
一般来说,我们语义相似度比较或检索,都是给每个句子算出一个句向量来,然后算它们的夹角余弦来比较或者排序。那么,我们有没有思考过这样的一个问题:余弦相似度对所输入的向量提出了什么假设呢?或者说,满足什么条件的向量用余弦相似度做比较效果会更好呢?
21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 79616位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在$Q,K$转置相乘之后还要除以一个$\sqrt{d}$再做Softmax(下面均不失一般性地假设$Q,K,V\in\mathbb{R}^{n\times d}$):
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{QK^{\top}}{\sqrt{d}}\right)V\label{eq:std}\end{equation}
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以$\sqrt{d}$的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
\begin{equation}\boldsymbol{o}_i = \sum_{j=1}^n a_{i,j}\boldsymbol{v}_j,\quad a_{i,j}=\frac{e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_{j=1}^n e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}
其中$\lambda$是缩放因子,它跟$\boldsymbol{q}_i,\boldsymbol{k}_j$无关,但原则上可以跟长度$n$、维度$d$等参数有关,目前主流的就是$\lambda=1/\sqrt{d}$。
10
Apr
从JL引理看熵不变性Attention
By 苏剑林 | 2023-04-10 | 19373位读者 | 引用在《从熵不变性看Attention的Scale操作》、《熵不变性Softmax的一个快速推导》中笔者提出了熵不变性Softmax,简单来说就是往Softmax之前的Attention矩阵多乘上一个$\log n$,理论上有助于增强长度外推性,其中$n$是序列长度。$\log n$这个因子让笔者联系到了JL引理(Johnson-Lindenstrauss引理),因为JL引理告诉我们编码$n$个向量只需要$\mathscr{O}(\log n)$的维度就行了,大家都是$\log n$,这两者有没有什么关联呢?
熵不变性
我们知道,熵是不确定性的度量,用在注意力机制中,我们将它作为“集中注意力的程度”。所谓熵不变性,指的是不管序列长度$n$是多少,我们都要将注意力集中在关键的几个token上,而不要太过分散。为此,我们提出的熵不变性Attention形式为
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{\log_{512} n}{\sqrt{d}}QK^{\top}\right)V\label{eq:core}\end{equation}
29
Jul
基于GRU和am-softmax的句子相似度模型
By 苏剑林 | 2018-07-29 | 288215位读者 | 引用搞计算机视觉的朋友会知道,am-softmax是人脸识别中的成果。所以这篇文章就是借鉴人脸识别的做法来做句子相似度模型,顺便介绍在Keras下各种margin loss的写法。
背景
细想之下会发现,句子相似度与人脸识别有很多的相似之处~
已有的做法
在我搜索到的资料中,深度学习做句子相似度模型,就只有两种做法:一是输入一对句子,然后输出一个0/1标签代表相似程度,也就是视为一个二分类问题,比如《Learning Text Similarity with Siamese Recurrent Networks》中的模型是这样的
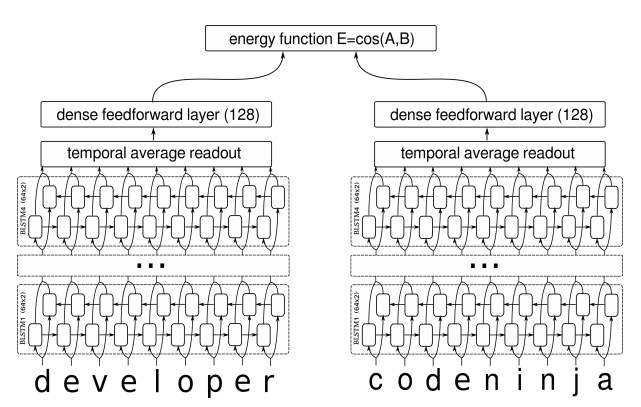
将句子相似度视为二分类模型
包括今年拍拍贷的“魔镜杯”,也是这种格式。另外一种做法是输入一个三元组“(句子A,跟A相似的句子,跟A不相似的句子)”,然后用triplet loss的做法解决,比如文章《Applying Deep Learning To Answer Selection: A Study And An Open Task》中的做法。
这两种做法其实也可以看成是一种,本质上是一样的,只不过loss和训练方法有所差别。但是,这两种方法却都有一个很严重的问题:负样本采样严重不足,导致效果提升非常慢。
26
Dec
【学习清单】最近比较重要的GAN进展论文
By 苏剑林 | 2018-12-26 | 56691位读者 | 引用这篇文章简单列举一下我认为最近这段时间中比较重要的GAN进展论文,这基本也是我在学习GAN的过程中主要去研究的论文清单。
生成模型之味
GAN是一个大坑,尤其像我这样的业余玩家,一头扎进去很久也很难有什么产出,尤其是各个大公司拼算力搞出来一个个大模型,个人几乎都没法玩了。但我总觉得,真的去碰了生成模型,才觉得自己碰到了真正的机器学习。这一点,不管在图像中还是文本中都是如此。所以,我还是愿意去关注生成模型。
当然,GAN不是生成模型的唯一选择,却是一个非常有趣的选择。在图像中至少有GAN、flow、pixelrnn/pixelcnn这几种选择,但要说潜力,我还是觉得GAN才是最具前景的,不单是因为效果,主要是因为它那对抗的思想。而在文本中,事实上seq2seq机制就是一个概率生成模型了,而pixelrnn这类模型,实际上就是模仿着seq2seq来做的,当然也有用GAN做文本生成的研究(不过基本上都涉及到了强化学习)。也就是说,其实在NLP中,生成模型也有很多成果,哪怕你主要是研究NLP的,也终将碰到生成模型。
好了,话不多说,还是赶紧把清单列一列,供大家参考,也作为自己的备忘。
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 205286位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
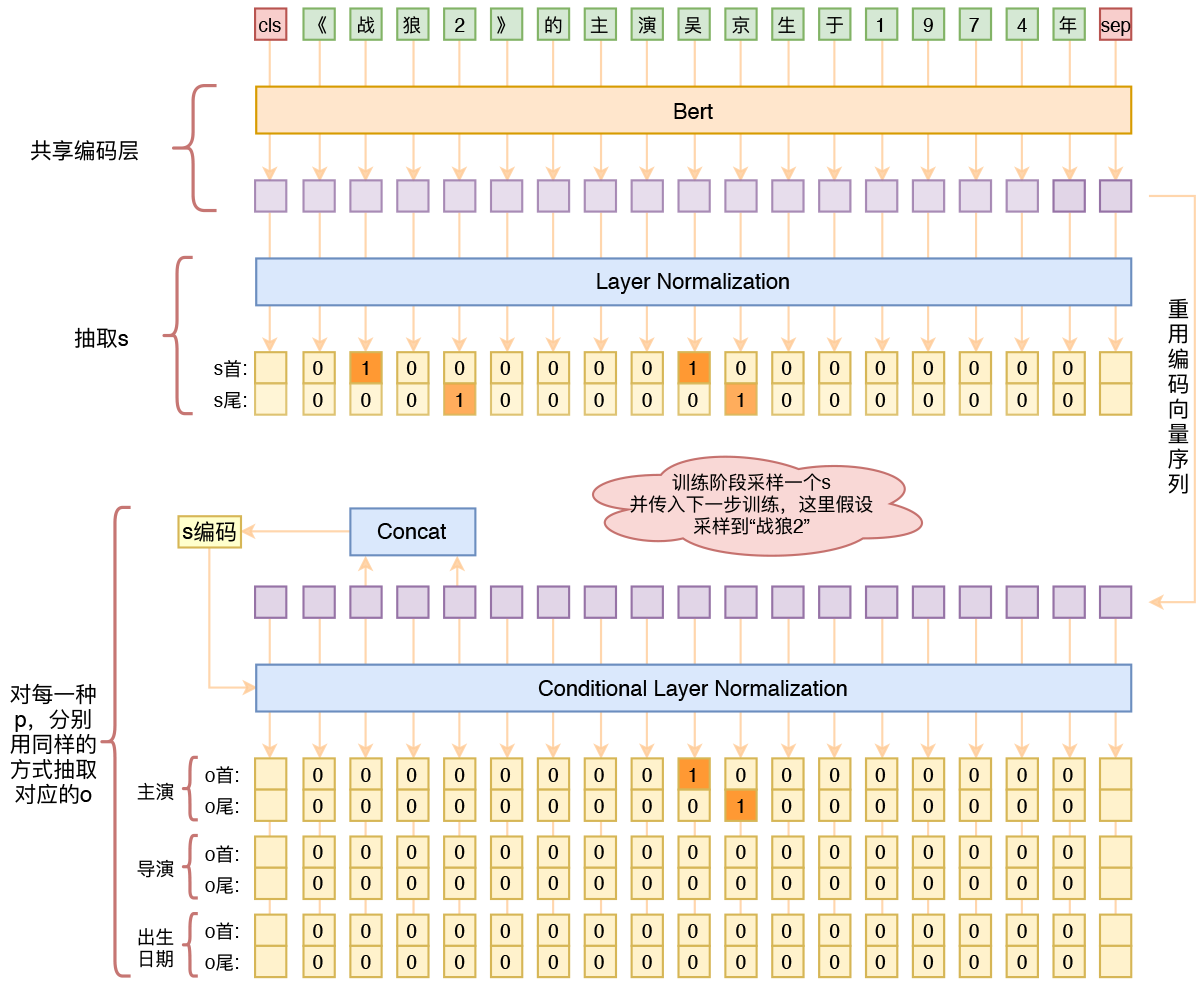
基于Bert的三元组抽取模型结构示意图

最近评论