






8
Sep
有限内存下全局打乱几百G文件(Python)
By 苏剑林 | 2021-09-08 | 70108位读者 | 引用这篇文章我们来做一道编程题:
如何在有限内存下全局随机打乱(Shuffle)几百G的文本文件?
题目背景其实很明朗,现在预训练模型动辄就几十甚至几百G语料了,为了让模型能更好地进行预训练,对训练语料进行一次全局的随机打乱是很有必要的。但对于很多人来说,几百G的语料往往比内存还要大,所以如何能在有限内存下做到全局的随机打乱,便是一个很值得研究的问题了。
已有工具
假设我们的文件是按行存储的,也就是一行代表一个样本,我们要做的就是按行随机打乱文件。假设我们只有一个文件,并且这个文件大小明显小于内存,那么我们可以用linux自带的shuf命令:
shuf input.txt -o output.txt
22
Oct
CAN:借助先验分布提升分类性能的简单后处理技巧
By 苏剑林 | 2021-10-22 | 145482位读者 | 引用顾名思义,本文将会介绍一种用于分类问题的后处理技巧——CAN(Classification with Alternating Normalization),出自论文《When in Doubt: Improving Classification Performance with Alternating Normalization》。经过笔者的实测,CAN确实多数情况下能提升多分类问题的效果,而且几乎没有增加预测成本,因为它仅仅是对预测结果的简单重新归一化操作。
有趣的是,其实CAN的思想是非常朴素的,朴素到每个人在生活中都应该用过同样的思想。然而,CAN的论文却没有很好地说清楚这个思想,只是纯粹形式化地介绍和实验这个方法。本文的分享中,将会尽量将算法思想介绍清楚。
思想例子
假设有一个二分类问题,模型对于输入$a$给出的预测结果是$p^{(a)} = [0.05, 0.95]$,那么我们就可以给出预测类别为$1$;接下来,对于输入$b$,模型给出的预测结果是$p^{(b)}=[0.5,0.5]$,这时候处于最不确定的状态,我们也不知道输出哪个类别好。
17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 65086位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
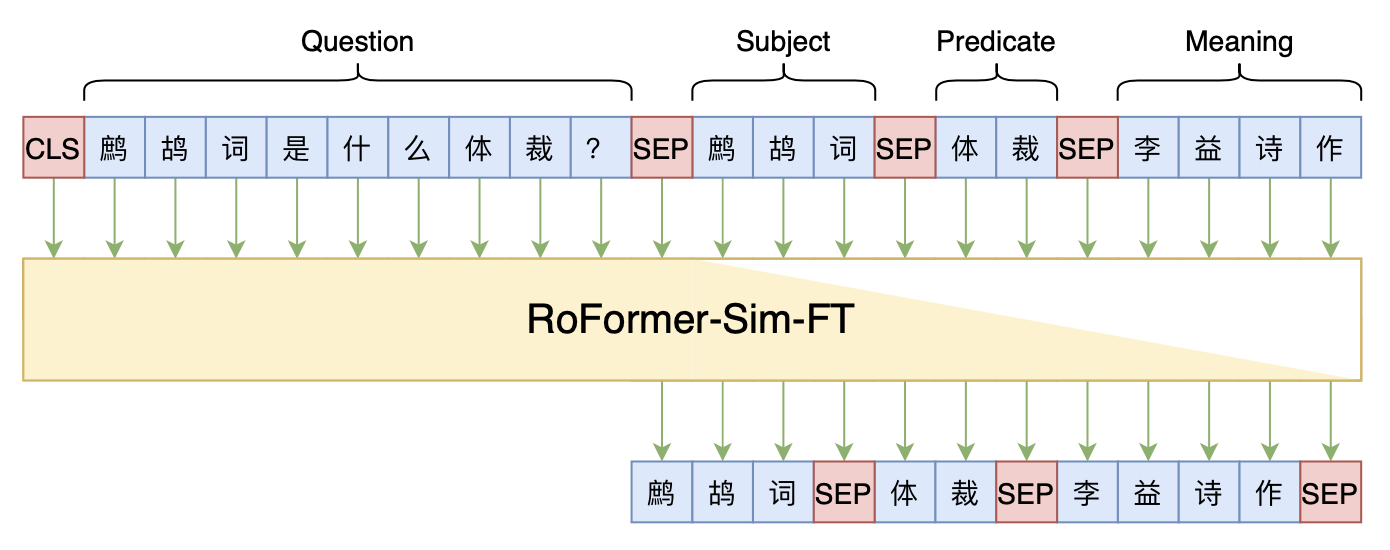
本文baseline模型示意图
21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 113214位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在$Q,K$转置相乘之后还要除以一个$\sqrt{d}$再做Softmax(下面均不失一般性地假设$Q,K,V\in\mathbb{R}^{n\times d}$):
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{QK^{\top}}{\sqrt{d}}\right)V\label{eq:std}\end{equation}
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以$\sqrt{d}$的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
\begin{equation}\boldsymbol{o}_i = \sum_{j=1}^n a_{i,j}\boldsymbol{v}_j,\quad a_{i,j}=\frac{e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_{j=1}^n e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}
其中$\lambda$是缩放因子,它跟$\boldsymbol{q}_i,\boldsymbol{k}_j$无关,但原则上可以跟长度$n$、维度$d$等参数有关,目前主流的就是$\lambda=1/\sqrt{d}$。
12
Jan
CoSENT(二):特征式匹配与交互式匹配有多大差距?
By 苏剑林 | 2022-01-12 | 87987位读者 | 引用一般来说,文本匹配有交互式(Interaction-based)和特征式(Representation-based)两种实现方案,其中交互式是指将两个文本拼接在一起当成单文本进行分类,而特征式则是指两个句子分别由编码器编码为句向量后再做简单的融合处理(算cos值或者接一个浅层网络)。通常的结论是,交互式由于使得两个文本能够进行充分的比较,所以它准确性通常较好,但明显的缺点是在检索场景的效率较差;而特征式则可以提前计算并缓存好句向量,所以它有着较高的效率,但由于句子间的交互程度较浅,所以通常效果不如交互式。
上一篇文章笔者介绍了CoSENT,它本质上也是一种特征式方案,并且相比以往的特征式方案效果有所提高。于是笔者的好胜心就上来了:CoSENT能比得过交互式吗?特征式相比交互式的差距有多远呢?本文就来做个比较。
自动阈值
在文章《CoSENT(一):比Sentence-BERT更有效的句向量方案》中,我们评测CoSENT所用的指标是Spearman系数,它是一个只依赖于预测结果相对顺序的指标,不依赖于阈值,比较适合检索场景的评测。但如果评测指标是accuracy或者F1这些分类指标,则必须确定一个阈值,将预测结果大于这个数的预测结果视为正、小于则为负,然后才能计算指标。在二分类的场景,我们用二分法就可以有效地确定这个阈值。
30
Jan
GPLinker:基于GlobalPointer的实体关系联合抽取
By 苏剑林 | 2022-01-30 | 117523位读者 | 引用在将近三年前的百度“2019语言与智能技术竞赛”(下称LIC2019)中,笔者提出了一个新的关系抽取模型(参考《基于DGCNN和概率图的轻量级信息抽取模型》),后被进一步发表和命名为“CasRel”,算是当时关系抽取的SOTA。然而,CasRel提出时笔者其实也是首次接触该领域,所以现在看来CasRel仍有诸多不完善之处,笔者后面也有想过要进一步完善它,但也没想到特别好的设计。
后来,笔者提出了GlobalPointer以及近日的Efficient GlobalPointer,感觉有足够的“材料”来构建新的关系抽取模型了。于是笔者从概率图思想出发,参考了CasRel之后的一些SOTA设计,最终得到了一版类似TPLinker的模型。
基础思路
关系抽取乍看之下是三元组$(s,p,o)$(即subject, predicate, object)的抽取,但落到具体实现上,它实际是“五元组”$(s_h,s_t,p,o_h,o_t)$的抽取,其中$s_h,s_t$分别是$s$的首、尾位置,而$o_h,o_t$则分别是$o$的首、尾位置。
25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 175332位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
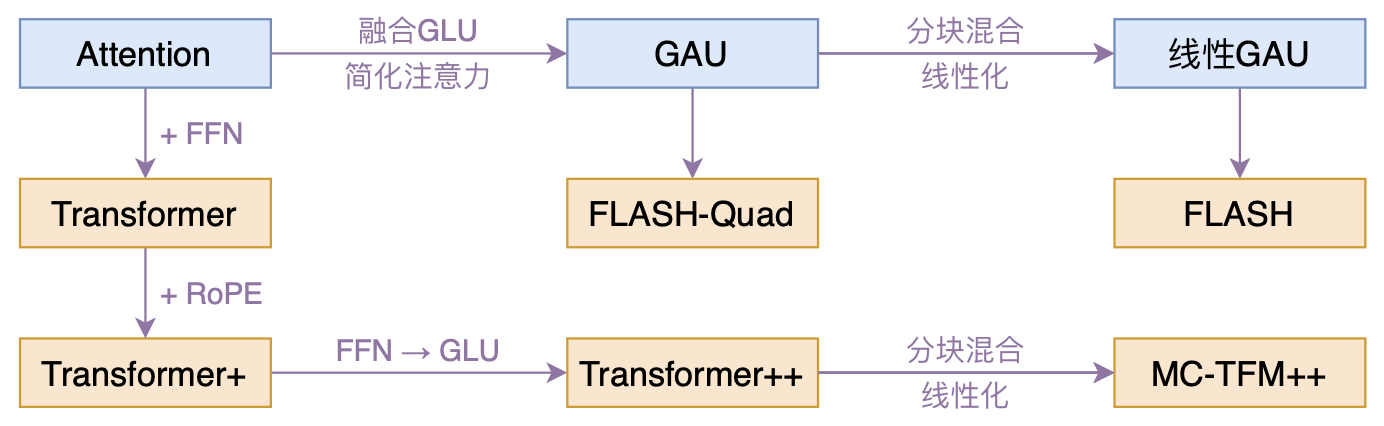
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
15
Apr
GlobalPointer下的“KL散度”应该是怎样的?
By 苏剑林 | 2022-04-15 | 25569位读者 | 引用最近有读者提到想测试一下GlobalPointer与R-Drop结合的效果,但不知道GlobalPointer下的KL散度该怎么算。像R-Drop或者虚拟对抗训练这些正则化手段,里边都需要算概率分布的KL散度,但GlobalPointer的预测结果并非一个概率分布,因此无法直接进行计算。
经过一番尝试,笔者给出了一个可用的形式,并通过简单实验验证了它的可行性,遂在此介绍笔者的分析过程。
对称散度
KL散度是关于两个概率分布的函数,它是不对称的,即$KL(p\Vert q)$通常不等于$KL(q\Vert p)$,在实际应用中,我们通常使用对称化的KL散度:
\begin{equation}D(p,q) = KL(p\Vert q) + KL(q\Vert p)\end{equation}

最近评论