






25
Jan
Efficient GlobalPointer:少点参数,多点效果
By 苏剑林 | 2022-01-25 | 118580位读者 | 引用在《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》中,我们提出了名为“GlobalPointer”的token-pair识别模块,当它用于NER时,能统一处理嵌套和非嵌套任务,并在非嵌套场景有着比CRF更快的速度和不逊色于CRF的效果。换言之,就目前的实验结果来看,至少在NER场景,我们可以放心地将CRF替换为GlobalPointer,而不用担心效果和速度上的损失。
在这篇文章中,我们提出GlobalPointer的一个改进版——Efficient GlobalPointer,它主要针对原GlobalPointer参数利用率不高的问题进行改进,明显降低了GlobalPointer的参数量。更有趣的是,多个任务的实验结果显示,参数量更少的Efficient GlobalPointer反而还取得更好的效果。
大量的参数
这里简单回顾一下GlobalPointer,详细介绍则请读者阅读《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》。简单来说,GlobalPointer是基于内积的token-pair识别模块,它可以用于NER场景,因为对于NER来说我们只需要把每一类实体的“(首, 尾)”这样的token-pair识别出来就行了。
21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 76165位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
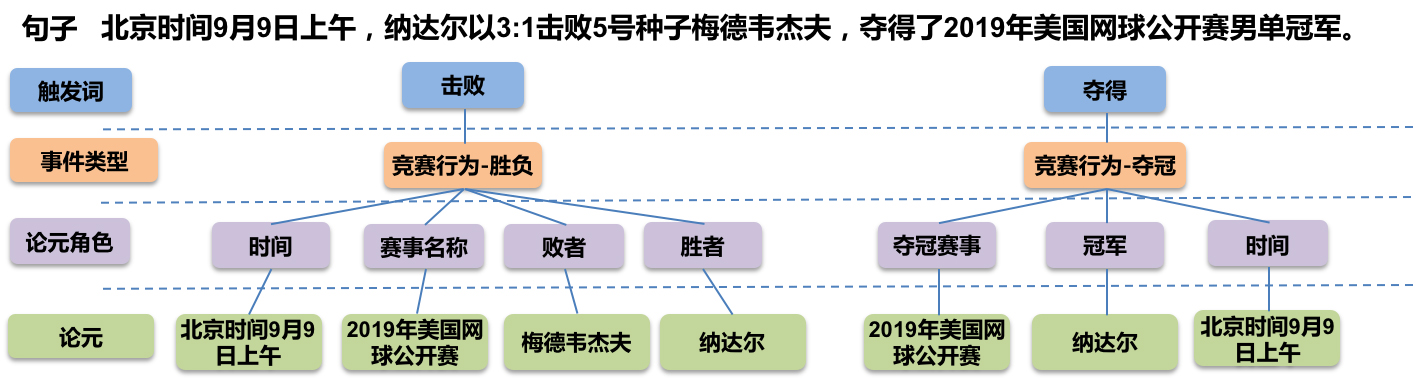
标准的事件抽取样本(图片来自百度DuEE的GitHub)
7
May
多标签“Softmax+交叉熵”的软标签版本
By 苏剑林 | 2022-05-07 | 48187位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
在《将“Softmax+交叉熵”推广到多标签分类问题》中,我们提出了一个用于多标签分类的损失函数:
\begin{equation}\log \left(1 + \sum\limits_{i\in\Omega_{neg}} e^{s_i}\right) + \log \left(1 + \sum\limits_{j\in\Omega_{pos}} e^{-s_j}\right)\label{eq:original}\end{equation}
这个损失函数有着单标签分类中“Softmax+交叉熵”的优点,即便在正负类不平衡的依然能够有效工作。但从这个损失函数的形式我们可以看到,它只适用于“硬标签”,这就意味着label smoothing、mixup等技巧就没法用了。本文则尝试解决这个问题,提出上述损失函数的一个软标签版本。
巧妙联系
多标签分类的经典方案就是转化为多个二分类问题,即每个类别用sigmoid函数$\sigma(x)=1/(1+e^{-x})$激活,然后各自用二分类交叉熵损失。当正负类别极其不平衡时,这种做法的表现通常会比较糟糕,而相比之下损失$\eqref{eq:original}$通常是一个更优的选择。
20
Apr
你的语言模型有没有“无法预测的词”?
By 苏剑林 | 2022-04-20 | 20456位读者 | 引用众所周知,分类模型通常都是先得到编码向量,然后接一个Dense层预测每个类别的概率,而预测时则是输出概率最大的类别。但大家是否想过这样一种可能:训练好的分类模型可能存在“无法预测的类别”,即不管输入是什么,都不可能预测出某个类别$k$,类别$k$永远不可能成为概率最大的那个。
当然,这种情况一般只出现在类别数远远超过编码向量维度的场景,常规的分类问题很少这么极端的。然而,我们知道语言模型本质上也是一个分类模型,它的类别数也就是词表的总大小,往往是远超过向量维度的,那么我们的语言模型是否有“无法预测的词”?(只考虑Greedy解码)
是否存在
ACL2022的论文《Low-Rank Softmax Can Have Unargmaxable Classes in Theory but Rarely in Practice》首先探究了这个问题,正如其标题所言,答案是“理论上存在但实际出现概率很小”。
13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 390073位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
28
Jun
“维度灾难”之Hubness现象浅析
By 苏剑林 | 2022-06-28 | 37735位读者 | 引用这几天读到论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》,了解到了一个新的名词“Hubness现象”,说的是高维空间中的一种聚集效应,本质上是“维度灾难”的体现之一。论文借助Hubness的概念得到了一个提升GAN模型生成质量的方案,看起来还蛮有意思。所以笔者就顺便去学习了一下Hubness现象的相关内容,记录在此,供大家参考。
坍缩的球
“维度灾难”是一个很宽泛的概念,所有在高维空间中与相应的二维、三维空间版本出入很大的结论,都可以称之为“维度灾难”,比如《n维空间下两个随机向量的夹角分布》中介绍的“高维空间中任何两个向量几乎都是垂直的”。其中,有不少维度灾难现象有着同一个源头——“高维空间单位球与其外切正方体的体积之比逐渐坍缩至0”,包括本文的主题“Hubness现象”亦是如此。
12
Aug
生成扩散模型漫谈(七):最优扩散方差估计(上)
By 苏剑林 | 2022-08-12 | 73996位读者 | 引用对于生成扩散模型来说,一个很关键的问题是生成过程的方差应该怎么选择,因为不同的方差会明显影响生成效果。
在《生成扩散模型漫谈(二):DDPM = 自回归式VAE》我们提到,DDPM分别假设数据服从两种特殊分布推出了两个可用的结果;《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中的DDIM则调整了生成过程,将方差变为超参数,甚至允许零方差生成,但方差为0的DDIM的生成效果普遍差于方差非0的DDPM;而《生成扩散模型漫谈(五):一般框架之SDE篇》显示前、反向SDE的方差应该是一致的,但这原则上在$\Delta t\to 0$时才成立;《Improved Denoising Diffusion Probabilistic Models》则提出将它视为可训练参数来学习,但会增加训练难度。
所以,生成过程的方差究竟该怎么设置呢?今年的两篇论文《Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models》和《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》算是给这个问题提供了比较完美的答案。接下来我们一起欣赏一下它们的结果。
3
Aug
生成扩散模型漫谈(五):一般框架之SDE篇
By 苏剑林 | 2022-08-03 | 183252位读者 | 引用在写生成扩散模型的第一篇文章时,就有读者在评论区推荐了宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》,可以说该论文构建了一个相当一般化的生成扩散模型理论框架,将DDPM、SDE、ODE等诸多结果联系了起来。诚然,这是一篇好论文,但并不是一篇适合初学者的论文,里边直接用到了随机微分方程(SDE)、Fokker-Planck方程、得分匹配等大量结果,上手难度还是颇大的。
不过,在经过了前四篇文章的积累后,现在我们可以尝试去学习一下这篇论文了。在接下来的文章中,笔者将尝试从尽可能少的理论基础出发,尽量复现原论文中的推导结果。
随机微分
在DDPM中,扩散过程被划分为了固定的$T$步,还是用《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》的类比来说,就是“拆楼”和“建楼”都被事先划分为了$T$步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。

最近评论