






4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 605254位读者 | 引用
1
Jul
从Boosting学习到神经网络:看山是山?
By 苏剑林 | 2016-07-01 | 64452位读者 | 引用前段时间在潮州给韩师的同学讲文本挖掘之余,涉猎到了Boosting学习算法,并且做了一番头脑风暴,最后把Boosting学习算法的一些本质特征思考清楚了,而且得到一些意外的结果,比如说AdaBoost算法的一些理论证明也可以用来解释神经网络模型这么强大。
AdaBoost算法
Boosting学习,属于组合模型的范畴,当然,与其说它是一个算法,倒不如说是一种解决问题的思路。以有监督的分类问题为例,它说的是可以把弱的分类器(只要准确率严格大于随机分类器)通过某种方式组合起来,就可以得到一个很优秀的分类器(理论上准确率可以100%)。AdaBoost算法是Boosting算法的一个例子,由Schapire在1996年提出,它构造了一种Boosting学习的明确的方案,并且从理论上给出了关于错误率的证明。
以二分类问题为例子,假设我们有一批样本$\{x_i,y_i\},i=1,2,\dots,n$,其中$x_i$是样本数据,有可能是多维度的输入,$y_i\in\{1,-1\}$为样本标签,这里用1和-1来描述样本标签而不是之前惯用的1和0,只是为了后面证明上的方便,没有什么特殊的含义。接着假设我们已经有了一个弱分类器$G(x)$,比如逻辑回归、SVM、决策树等,对分类器的唯一要求是它的准确率要严格大于随机(在二分类问题中就是要严格大于0.5),所谓严格大于,就是存在一个大于0的常数$\epsilon$,每次的准确率都不低于$\frac{1}{2}+\epsilon$。
6
Sep
基于双向LSTM和迁移学习的seq2seq核心实体识别
By 苏剑林 | 2016-09-06 | 161416位读者 | 引用暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下。模型的效果不是最好的,但是胜在“端到端”,迁移性强,估计对大家会有一定的参考价值。
比赛的主题是“核心实体识别”,其实有两个任务:核心识别 + 实体识别。这两个任务虽然有关联,但在传统自然语言处理程序中,一般是将它们分开处理的,而这次需要将两个任务联合在一起。如果只看“核心识别”,那就是传统的关键词抽取任务了,不同的是,传统的纯粹基于统计的思路(如TF-IDF抽取)是行不通的,因为单句中的核心实体可能就只出现一次,这时候统计估计是不可靠的,最好能够从语义的角度来理解。我一开始就是从“核心识别”入手,使用的方法类似QA系统:
1、将句子分词,然后用Word2Vec训练词向量;
2、用卷积神经网络(在这种抽取式问题上,CNN效果往往比RNN要好)卷积一下,得到一个与词向量维度一样的输出;
3、损失函数就是输出向量跟训练样本的核心词向量的cos值。
6
Mar
【中文分词系列】 7. 深度学习分词?只需一个词典!
By 苏剑林 | 2017-03-06 | 115717位读者 | 引用这个系列慢慢写到第7篇,基本上也把分词的各种模型理清楚了,除了一些细微的调整(比如最后的分类器换成CRF)外,剩下的就看怎么玩了。基本上来说,要速度,就用基于词典的分词,要较好地解决组合歧义何和新词识别,则用复杂模型,比如之前介绍的LSTM、FCN都可以。但问题是,用深度学习训练分词器,需要标注语料,这费时费力,仅有的公开的几个标注语料,又不可能赶得上时效,比如,几乎没有哪几个公开的分词系统能够正确切分出“扫描二维码,关注微信号”来。
本文就是做了这样的一个实验,仅用一个词典,就完成了一个深度学习分词器的训练,居然效果还不错!这种方案可以称得上是半监督的,甚至是无监督的。
18
Apr
最小熵原理(一):无监督学习的原理
By 苏剑林 | 2018-04-18 | 85695位读者 | 引用话在开头
在深度学习等端到端方案已经逐步席卷NLP的今天,你是否还愿意去思考自然语言背后的基本原理?我们常说“文本挖掘”,你真的感受到了“挖掘”的味道了吗?
无意中的邂逅
前段时间看了一篇关于无监督句法分析的文章,继而从它的参考文献中发现了论文《Redundancy Reduction as a Strategy for Unsupervised Learning》,这篇论文介绍了如何从去掉空格的英文文章中将英文单词复原。对应到中文,这不就是词库构建吗?于是饶有兴致地细读了一番,发现论文思路清晰、理论完整、结果漂亮,让人赏心悦目。
尽管现在看来,这篇论文的价值不是很大,甚至其结果可能已经被很多人学习过了,但是要注意:这是一篇1993年的论文!在PC机还没有流行的年代,就做出了如此前瞻性的研究。虽然如今深度学习流行,NLP任务越做越复杂,这确实是一大进步,但是我们对NLP原理的真正了解,还不一定超过几十年前的前辈们多少。
这篇论文是通过“去冗余”(Redundancy Reduction)来实现无监督地构建词库的,从信息论的角度来看,“去冗余”就是信息熵的最小化。无监督句法分析那篇文章也指出“信息熵最小化是无监督的NLP的唯一可行的方案”。我进而学习了一些相关资料,并且结合自己的理解思考了一番,发现这个评论确实是耐人寻味。我觉得,不仅仅是NLP,信息熵最小化很可能是所有无监督学习的根本。
2
Oct
深度学习的互信息:无监督提取特征
By 苏剑林 | 2018-10-02 | 273493位读者 | 引用
随机采样的KNN样本
对于NLP来说,互信息是一个非常重要的指标,它衡量了两个东西的本质相关性。本博客中也多次讨论过互信息,而我也对各种利用互信息的文章颇感兴趣。前几天在机器之心上看到了最近提出来的Deep INFOMAX模型,用最大化互信息来对图像做无监督学习,自然也颇感兴趣,研读了一番,就得到了本文。
本文整体思路源于Deep INFOMAX的原始论文,但并没有照搬原始模型,而是按照这自己的想法改动了模型(主要是先验分布部分),并且会在相应的位置进行注明。
我们要做什么
自编码器
特征提取是无监督学习中很重要且很基本的一项任务,常见形式是训练一个编码器将原始数据集编码为一个固定长度的向量。自然地,我们对这个编码器的基本要求是:保留原始数据的(尽可能多的)重要信息。
我们怎么知道编码向量保留了重要信息呢?一个很自然的想法是这个编码向量应该也要能还原出原始图片出来,所以我们还训练一个解码器,试图重构原图片,最后的loss就是原始图片和重构图片的mse。这导致了标准的自编码器的设计。后来,我们还希望编码向量的分布尽量能接近高斯分布,这就导致了变分自编码器。
重构的思考
27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 150522位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
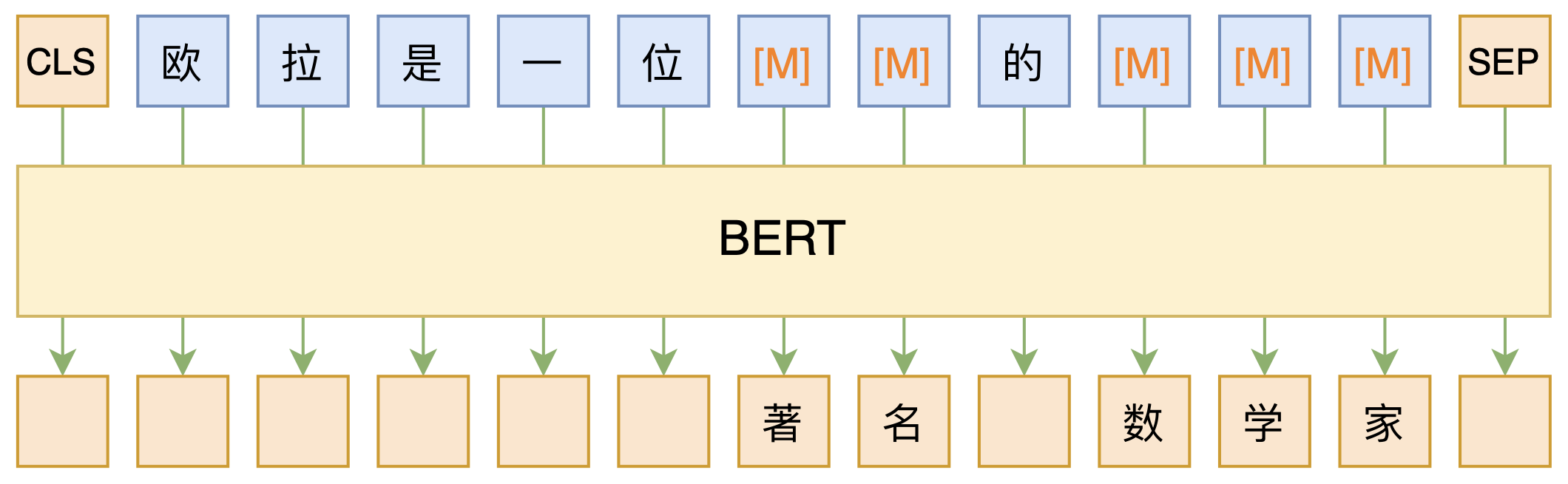
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。
17
Jun
对比学习可以使用梯度累积吗?
By 苏剑林 | 2021-06-17 | 59165位读者 | 引用在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们介绍过“梯度累积”,它是在有限显存下实现大batch_size效果的一种技巧。一般来说,梯度累积适用的是loss是独立同分布的场景,换言之每个样本单独计算loss,然后总loss是所有单个loss的平均或求和。然而,并不是所有任务都满足这个条件的,比如最近比较热门的对比学习,每个样本的loss还跟其他样本有关。
那么,在对比学习场景,我们还可以使用梯度累积来达到大batch_size的效果吗?本文就来分析这个问题。
简介
一般情况下,对比学习的loss可以写为
\begin{equation}\mathcal{L}=-\sum_{i,j=1}^b t_{i,j}\log p_{i,j} = -\sum_{i,j=1}^b t_{i,j}\log \frac{e^{s_{i,j}}}{\sum\limits_j e^{s_{i,j}}}=-\sum_{i,j=1}^b t_{i,j}s_{i,j} + \sum_{i=1}^b \log\sum_{j=1}^b e^{s_{i,j}}\label{eq:loss}\end{equation}
这里的$b$是batch_size;$t_{i,j}$是事先给定的标签,满足$t_{i,j}=t_{j,i}$,它是一个one hot矩阵,每一列只有一个1,其余都为0;而$s_{i,j}$是样本$i$和样本$j$的相似度,满足$s_{i,j}=s_{j,i}$,一般情况下还有个温度参数,这里假设温度参数已经整合到$s_{i,j}$中,从而简化记号。模型参数存在于$s_{i,j}$中,假设为$\theta$。

最近评论