






18
Nov
《量子力学与路径积分》习题解答V0.3
By 苏剑林 | 2015-11-18 | 18506位读者 | 引用新的《量子力学与路径积分》习题解答又放出来啦。与前两个版本不同的是,前两次更新,每次基本上完成了两章的习题,而这一次,只是增加了第6章的22道习题(第6章共有29道)。原因很多,各种忙就不说啦,主要是第6章开始,各种题目开始复杂起来,计算量也增大,虽然笔者是数学系的,可是还是前进得艰难。还有,第4、5两章加起来也只是25道习题,第6章却有29题,因此,本次更新的工作量,远远大于前两次更新的工作量。
为什么只有22题?当然是没有做完啦。为什么没有做完就更新啦?因为笔者觉得右面的题目,跟第7章的联系更为密切,因此,怕读者等不及,所以剩下的题目,跟第7章一起再发吧。
此外,我是看着中文版来做题的,中文版的翻译质量还不错,但是细微之处却有些不妥当,所以笔者要来回参考中英文版,颇累。读者可以发现,这一版中,“勘误”增加了不少。
9
Jan
《量子力学与路径积分》习题解答V0.4
By 苏剑林 | 2016-01-09 | 32598位读者 | 引用
流年
《量子力学与路径积分》的习题解答终于艰难地推进到了0.4版本,目前已经基本完成了前7章的习题。
今天已经是2016年1月9号了,2015年已经远去,都忘记跟大家说一声新年快乐了,实在抱歉。在这里补充一句:祝大家新年快乐,事事如意!。
笔者已经大四了,现在是临近期末考,又临近毕业。最近忙的事情有很多,其中之一是我加入了一个互联网小公司的创业队伍中,负责文本挖掘,偶尔也写写爬虫,等等,感觉自己进去之后,增长了不少见识,也增加了不少技术知识,较之我上一次实习,又有不一样的高度。现在里边有好几样事情排队着做,可谓忙得不亦悦乎了。还有,我也开始写毕业论文了,早点写完能够多点时间,学学自己喜欢的东西,毕业论文我写的是路径积分相关的内容,自我感觉写得还是比较清楚易懂的,等时机成熟了,发出来,向大家普及路径积分^_^。此外,每天做点路径积分的习题,也要消耗不少时间,有些比较难的题目,基本一道就做几个早上才能写出比较满意的答案。总感觉想学的想做的事情有很多,可是时间很少。
3
Jul
《交换代数导引》参考答案
By 苏剑林 | 2017-07-03 | 35696位读者 | 引用这学期我们的一门课是《交换代数》,是本科抽象代数的升级版。我们用的教材是Atiyah的《Introduction to Commutative Algebra》(交换代数导引),而且根据老师的上课安排,还需要我们把部分课后习题完成并讲解...不得不说这门课上得真累啊~
习题做到后面,我干脆懒得起草稿了,直接把做的答案用LaTeX录入了,既方便排版也方便修改。在这里分享给有需要的读者~答案是用中文写的,注释比较详细,适合刚学这门课的同学~
笔者所做的部分:《交换代数导引》参考答案.pdf
当然这份答案只包括老师对我们的要求的那部分习题,下面是网上搜索到的完整的习题解答,英文版的:
网上找到的答案:Jeffrey Daniel Kasik Carlson - Exercises to Atiya.pdf
如果答案有问题,欢迎留言指出。
20
Mar
《为什么现在的LLM都是Decoder-only的架构?》FAQ
By 苏剑林 | 2023-03-20 | 51324位读者 | 引用上周笔者写了《为什么现在的LLM都是Decoder-only的架构?》,总结了一下我在这个问题上的一些实验结论和猜测。果然是热点问题流量大,paperweekly的转发没多久阅读量就破万了,知乎上点赞数也不少。在几个平台上,陆陆续续收到了读者的一些意见或者疑问,总结了其中一些有代表性的问题,做成了本篇FAQ,希望能进一步帮助大家解决疑惑。
回顾
在《为什么现在的LLM都是Decoder-only的架构?》中,笔者对GPT和UniLM两种架构做了对比实验,然后结合以往的研究经历,猜测了如下结论:
1、输入部分的注意力改为双向不会带来收益,Encoder-Decoder架构的优势很可能只是源于参数翻倍;
2、双向注意力没有带来收益,可能是因为双向注意力的低秩问题导致效果下降。
所以,基于这两点推测,我们得到结论:
在同等参数量、同等推理成本下,Decoder-only架构是最优选择。
6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 50047位读者 | 引用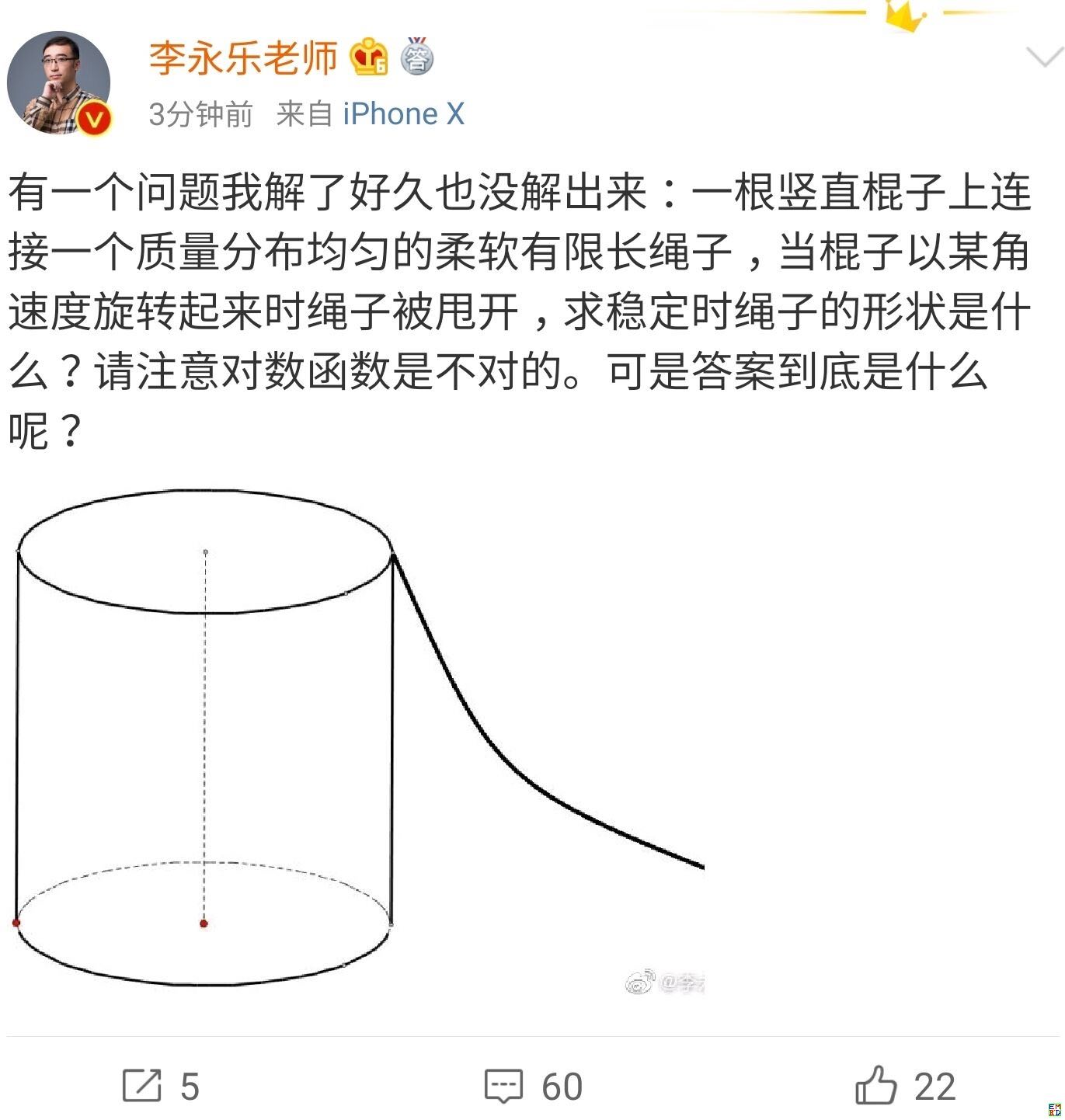
23
Mar
梯度下降和EM算法:系出同源,一脉相承
By 苏剑林 | 2017-03-23 | 213288位读者 | 引用PS:本文就是梳理了梯度下降与EM算法的关系,通过同一种思路,推导了普通的梯度下降法、pLSA中的EM算法、K-Means中的EM算法,以此表明它们基本都是同一个东西的不同方面,所谓“横看成岭侧成峰,远近高低各不同”罢了。
在机器学习中,通常都会将我们所要求解的问题表示为一个带有未知参数的损失函数(Loss),如平均平方误差(MSE),然后想办法求解这个函数的最小值,来得到最佳的参数值,从而完成建模。因将函数乘以-1后,最大值也就变成了最小值,因此一律归为最小值来说。如何求函数的最小值,在机器学习领域里,一般会流传两个大的方向:1、梯度下降;2、EM算法,也就是最大期望算法,一般用于复杂的最大似然问题的求解。
在通常的教程中,会将这两个方法描述得迥然不同,就像两大体系在分庭抗礼那样,而EM算法更是被描述得玄乎其玄的感觉。但事实上,这两个方法,都是同一个思路的不同例子而已,所谓“本是同根生”,它们就是一脉相承的东西。
让我们,先从远古的牛顿法谈起。
牛顿迭代法
给定一个复杂的非线性函数$f(x)$,希望求它的最小值,我们一般可以这样做,假定它足够光滑,那么它的最小值也就是它的极小值点,满足$f'(x_0)=0$,然后可以转化为求方程$f'(x)=0$的根了。非线性方程的根我们有个牛顿法,所以
\begin{equation}x_{n+1} = x_{n} - \frac{f'(x_n)}{f''(x_n)}\end{equation}

3
Feb
[SETI-50周年]茫茫宇宙觅知音
By 苏剑林 | 2011-02-03 | 20249位读者 | 引用转载自2011年1月的《天文爱好者》 作者:薛国轩
“多萝西计划”再探地外文明
据美国空间网站2010年11月13日报道,在人类“探索地外文明”(英文缩写为SETI)50周年纪念之际,世界多个国家的天文学家从本月起再度展开“且听外星人”的联合行动,以延续开始于1960年的“奥兹玛计划”。新的探索活动被命名为“多萝西计划”(Project Dorothy),已于11月5日正式启动,将持续整整一个月时间,来自澳大利亚、日本、韩国、意大利、荷兰、法国、阿根廷和美国的天文学家参与其中。他们将把大大小小的望远镜指向地球周围的一些星球,以期收听到外星人的“天外来音”。

Allen Telescope Array

最近评论