






26
Aug
近乎完美地解决MathJax与Marked的冲突
By 苏剑林 | 2024-08-26 | 12904位读者 | 引用在《让MathJax更好地兼容谷歌翻译和延时加载》我们提到Cool Papers加入了MathJax来解析LaTeX公式,不过万万没想到引发了诸多兼容性问题,虽然部分问题纯粹是笔者的强迫症作祟,但一个尽可能完美的解决方案终究是让人赏心悦目的,所以还是愿意在上面花一点心思。
上一篇文章我们已经解决了MathJax与谷歌翻译、延时加载的兼容性,这篇文章我们则来解决MathJax与Marked的冲突。
问题简述
Markdown是一种轻量级标记语言,允许人们使用易读易写的纯文本格式编写文档,可谓是目前最流行的写作语法之一,Cool Papers中的[Kimi]功能,基本上也是按照Markdown语法输出。然而。Markdown并不是直接面向浏览器的语言,面向浏览器的语言叫做HTML,所以在展示给用户之前,有一个Markdown转HTML的过程(渲染)。
15
Oct
让MathJax的数学公式随窗口大小自动缩放
By 苏剑林 | 2024-10-15 | 16065位读者 | 引用随着MathJax的出现和流行,在网页上显示数学公式便逐渐有了标准答案。然而,MathJax(包括其竞品KaTeX)只是负责将网页LaTeX代码转化为数学公式,对于自适应分辨率方面依然没有太好的办法。像本站一些数学文章,因为是在PC端排版好的,所以在PC端浏览效果尚可,但转到手机上看就可能有点难以入目了。
经过测试,笔者得到了一个方案,让MathJax的数学公式也能像图片一样,随着窗口大小而自适应缩放,从而尽量保证移动端的显示效果,在此跟大家分享一波。
背景思路
这个问题的起源是,即便在PC端进行排版,有时候也会遇到一些单行公式的长度超出了网页宽度,但又不大好换行的情况,这时候一个解决方案是用HTML代码手动调整一下公式的字体大小,比如
<span style="font-size:90%">
\begin{equation}一个超长的数学公式\end{equation}
</span>
16
Oct
Cool Papers浏览器扩展升级至v0.2.0
By 苏剑林 | 2024-10-16 | 19529位读者 | 引用年初,我们在《更便捷的Cool Papers打开方式:Chrome重定向扩展》中发布了一个Chrome浏览器插件(Cool Papers Redirector v0.1.0),可以通过右击菜单从任意页面中重定向到Cool Papers中,让大家更方便地获取Kimi对论文的理解。前几天我们把该插件升级到了v0.2.0,并顺利上架到了Chrome应用商店中,遂在此向大家推送一下。
更新汇总
相比旧版v0.1.0,当前版v0.2.0的主要更新内容如下:
1、右键菜单跳转改为在新标签页打开;
2、右键菜单支持同时访问多个论文ID;
3、右键菜单支持PDF页面;
4、右键菜单新增更多论文源(arXiv、OpenReview、ACL、IJCAI、PMLR);
5、右键菜单在搜索不到论文ID时,转入站内搜索(即划词搜索);
6、在某些网站的适当位置插入快捷跳转链接(arXiv、OpenReview,ACL)。
29
Nov
从Hessian近似看自适应学习率优化器
By 苏剑林 | 2024-11-29 | 8914位读者 | 引用这几天在重温去年的Meta的一篇论文《A Theory on Adam Instability in Large-Scale Machine Learning》,里边给出了看待Adam等自适应学习率优化器的新视角:它指出梯度平方的滑动平均某种程度上近似于在估计Hessian矩阵的平方,从而Adam、RMSprop等优化器实际上近似于二阶的Newton法。
这个角度颇为新颖,而且表面上跟以往的一些Hessian近似有明显的差异,因此值得我们去学习和思考一番。
牛顿下降
设损失函数为$\mathcal{L}(\boldsymbol{\theta})$,其中待优化参数为$\boldsymbol{\theta}$,我们的优化目标是
\begin{equation}\boldsymbol{\theta}^* = \mathop{\text{argmin}}_{\boldsymbol{\theta}} \mathcal{L}(\boldsymbol{\theta})\label{eq:loss}\end{equation}
假设$\boldsymbol{\theta}$的当前值是$\boldsymbol{\theta}_t$,Newton法通过将损失函数展开到二阶来寻求$\boldsymbol{\theta}_{t+1}$:
\begin{equation}\mathcal{L}(\boldsymbol{\theta})\approx \mathcal{L}(\boldsymbol{\theta}_t) + \boldsymbol{g}_t^{\top}(\boldsymbol{\theta} - \boldsymbol{\theta}_t) + \frac{1}{2}(\boldsymbol{\theta} - \boldsymbol{\theta}_t)^{\top}\boldsymbol{\mathcal{H}}_t(\boldsymbol{\theta} - \boldsymbol{\theta}_t)\end{equation}
10
Dec
Muon优化器赏析:从向量到矩阵的本质跨越
By 苏剑林 | 2024-12-10 | 7311位读者 | 引用随着LLM时代的到来,学术界对于优化器的研究热情似乎有所减退。这主要是因为目前主流的AdamW已经能够满足大多数需求,而如果对优化器“大动干戈”,那么需要巨大的验证成本。因此,当前优化器的变化,多数都只是工业界根据自己的训练经验来对AdamW打的一些小补丁。
不过,最近推特上一个名为“Muon”的优化器颇为热闹,它声称比AdamW更为高效,且并不只是在Adam基础上的“小打小闹”,而是体现了关于向量与矩阵差异的一些值得深思的原理。本文让我们一起赏析一番。
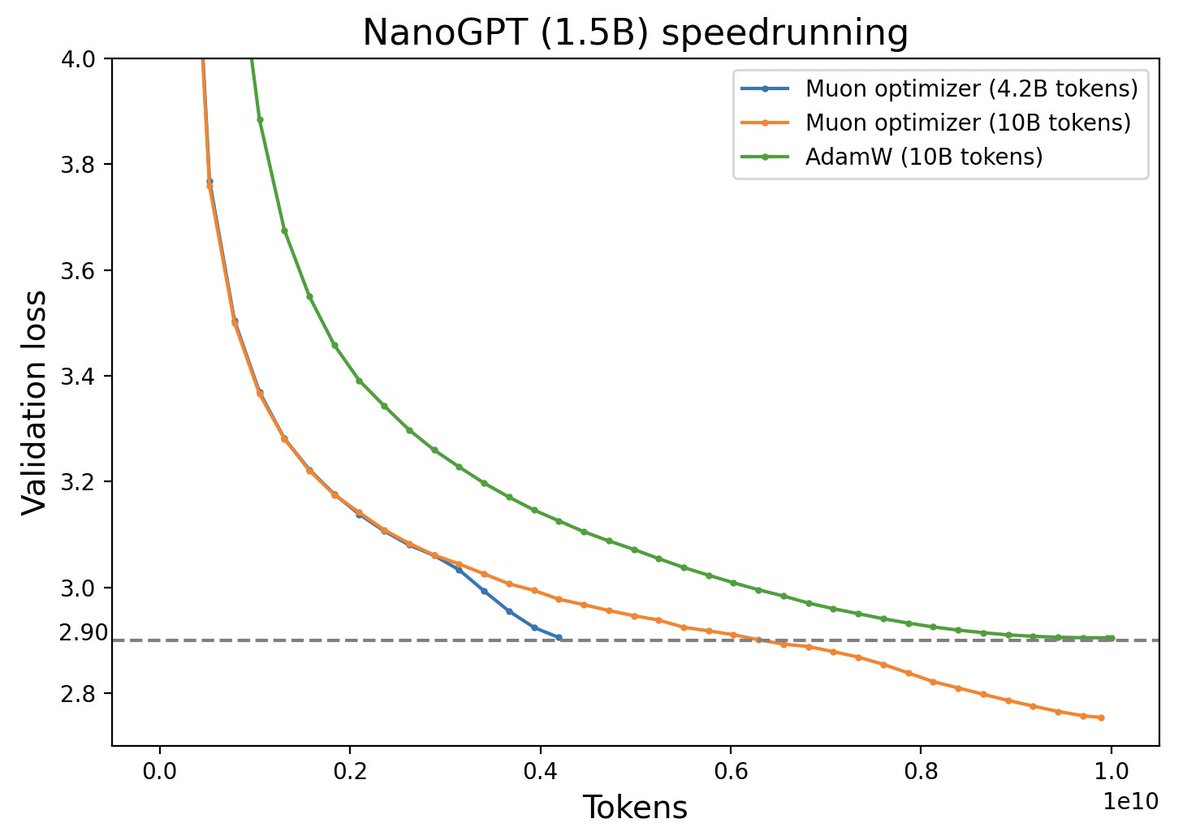
Muon与AdamW效果对比(来源:推特@Yuchenj_UW)
18
Dec
生成扩散模型漫谈(二十八):分步理解一致性模型
By 苏剑林 | 2024-12-18 | 2180位读者 | 引用在上文《生成扩散模型漫谈(二十七):将步长作为条件输入》中,我们介绍了加速采样的Shortcut模型,其对比的模型之一就是“一致性模型(Consistency Models)”。事实上,早在《生成扩散模型漫谈(十七):构建ODE的一般步骤(下)》介绍ReFlow时,就有读者提到了一致性模型,但笔者总感觉它更像是实践上的Trick,理论方面略显单薄,所以兴趣寥寥。
不过,既然我们开始关注扩散模型加速采样方面的进展,那么一致性模型就是一个绕不开的工作。因此,趁着这个机会,笔者在这里分享一下自己对一致性模型的理解。
熟悉配方
还是熟悉的配方,我们的出发点依旧是ReFlow,因为它大概是ODE式扩散最简单的理解方式。设$\boldsymbol{x}_0\sim p_0(\boldsymbol{x}_0)$是目标分布的真实样本,$\boldsymbol{x}_1\sim p_1(\boldsymbol{x}_1)$是先验分布的随机噪声,$\boldsymbol{x}_t = (1-t)\boldsymbol{x}_0 + t\boldsymbol{x}_1$是加噪样本,那么ReFlow的训练目标是:
19
Aug
【中文分词系列】 3. 字标注法与HMM模型
By 苏剑林 | 2016-08-19 | 85840位读者 | 引用在这篇文章中,我们暂停查词典方法的介绍,转而介绍字标注的方法。前面已经提到过,字标注是通过给句子中每个字打上标签的思路来进行分词,比如之前提到过的,通过4标签来进行标注(single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾。均只取第一个字母。),这样,“为人民服务”就可以标注为“sbebe”了。4标注不是唯一的标注方式,类似地还有6标注,理论上来说,标注越多会越精细,理论上来说效果也越好,但标注太多也可能存在样本不足的问题,一般常用的就是4标注和6标注。
值得一提的是,这种通过给每个字打标签、进而将问题转化为序列到序列的学习,不仅仅是一种分词方法,还是一种解决大量自然语言问题的思路,比如命名实体识别等任务,同样可以用标注的方法来做。回到分词来,通过字标注法来进行分词的模型有隐马尔科夫模型(HMM)、最大熵模型(ME)、条件随机场模型(CRF),它们在精度上都是递增的,据说目前公开评测中分词效果最好的是4标注的CRF。然而,在本文中,我们要讲解的是最不精确的HMM。因为在我看来,它并非一个特定的模型,而是解决一大类问题的通用思想,一种简化问题的学问。
这一切,还得从概率模型谈起。
13
Jan
【中文分词系列】 6. 基于全卷积网络的中文分词
By 苏剑林 | 2017-01-13 | 60208位读者 | 引用之前已经写过用LSTM来做分词的方案了,今天再来一篇用CNN的,准确来说是FCN,全卷积网络。其实这个模型的主要目的并非研究中文分词,而是练习tensorflow。从两年前就开始用Keras了,可以说对它比较熟了,也渐渐发现了它的一些不足,比如处理变长输入时不方便、加入自定义的约束比较困难等,所以干脆试试原生的tensorflow了,试了之后发现其实也不复杂。嗯,都是python,能有多复杂。本文就是练习一下如何用tensorflow处理不定长输入任务,以中文分词为例,并在最后加入了硬解码,将深度学习与词典分词结合了起来。
CNN
另外,就是关于FCN的。放到语言任务中看,(一维)卷积其实就是ngram模型,从这个角度来看其实CNN远比RNN来得自然,RNN好像就是为序列任务精心设计的,而CNN则是传统ngram模型的一个延伸。另外不管CNN和RNN都有权值共享,看上去只是为了降低运算量的一个折中选择,但事实上里边大有道理。CNN中的权值共享是平移不变性的必然结果,而不是仅仅是降低运算量的一个选择,试想一下,将一幅图像平移一点点,或者在一个句子前插入一个无意义的空格(导致后面所有字都向后平移了一位),这样应该给出一个相似甚至相同的结果,而这要求卷积必然是权值共享的,即权值不能跟位置有关系。

最近评论