






27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 151313位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
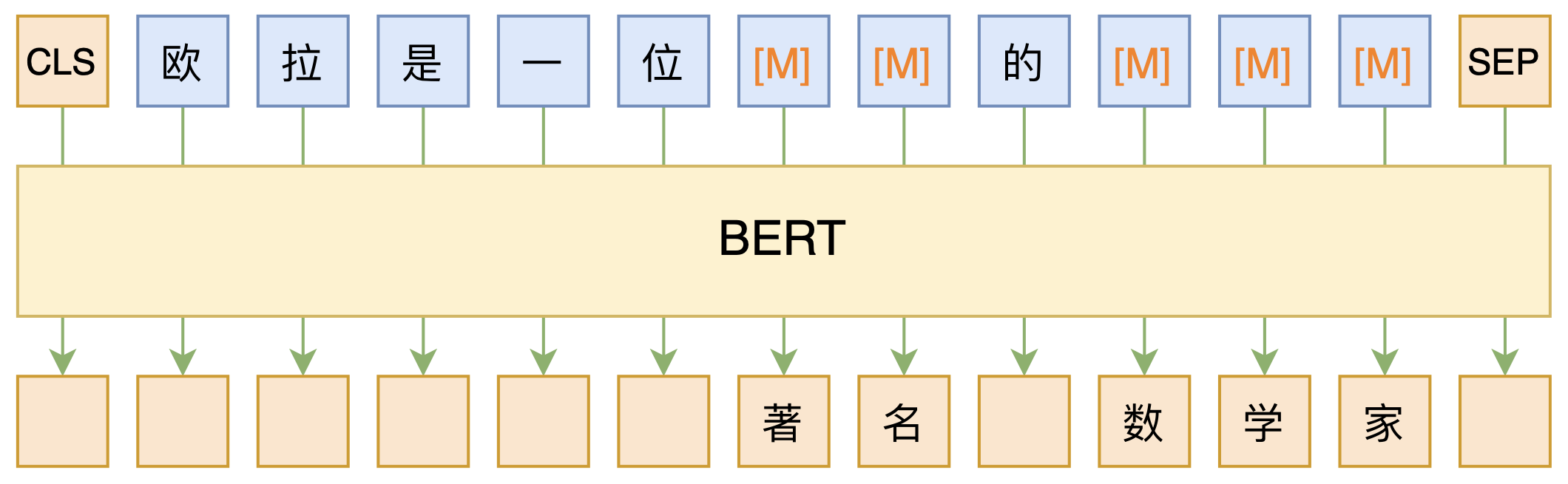
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。
9
Dec
变分自编码器(八):估计样本概率密度
By 苏剑林 | 2021-12-09 | 61847位读者 | 引用在本系列的前面几篇文章中,我们已经从多个角度来理解了VAE,一般来说,用VAE是为了得到一个生成模型,或者是做更好的编码模型,这都是VAE的常规用途。但除了这些常规应用外,还有一些“小众需求”,比如用来估计$x$的概率密度,这在做压缩的时候通常会用到。
本文就从估计概率密度的角度来了解和推导一下VAE模型。
两个问题
所谓估计概率密度,就是在已知样本$x_1,x_2,\cdots,x_N\sim \tilde{p}(x)$的情况下,用一个待定的概率密度簇$q_{\theta}(x)$去拟合这批样本,拟合的目标一般是最小化负对数似然:
\begin{equation}\mathbb{E}_{x\sim \tilde{p}(x)}[-\log q_{\theta}(x)] = -\frac{1}{N}\sum_{i=1}^N \log q_{\theta}(x_i)\label{eq:mle}\end{equation}
3
Apr
P-tuning:自动构建模版,释放语言模型潜能
By 苏剑林 | 2021-04-03 | 145437位读者 | 引用在之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》中,我们介绍了一种名为Pattern-Exploiting Training(PET)的方法,它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
![P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性](/usr/uploads/2021/04/2868831073.png)
P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性
最近Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
15
Sep
殊途同归的策略梯度与零阶优化
By 苏剑林 | 2020-09-15 | 55877位读者 | 引用深度学习如此成功的一个巨大原因就是基于梯度的优化算法(SGD、Adam等)能有效地求解大多数神经网络模型。然而,既然是基于梯度,那么就要求模型是可导的,但随着研究的深入,我们时常会有求解不可导模型的需求,典型的例子就是直接优化准确率、F1、BLEU等评测指标,或者在神经网络里边加入了不可导模块(比如“跳读”操作)。

Gradient
本文将简单介绍两种求解不可导的模型的有效方法:强化学习的重要方法之一策略梯度(Policy Gradient),以及干脆不需要梯度的零阶优化(Zeroth Order Optimization)。表面上来看,这是两种思路完全不一样的优化方法,但本文将进一步证明,在一大类优化问题中,其实两者基本上是等价的。
24
Jul
基于Xception的腾讯验证码识别(样本+代码)
By 苏剑林 | 2017-07-24 | 92782位读者 | 引用去年的时候,有幸得到网友提供的一批腾讯验证码样本,因此也研究了一下,过程记录在《端到端的腾讯验证码识别(46%正确率)》中。
后来,这篇文章引起了不少读者的兴趣,有求样本的,有求模型的,有一起讨论的,让我比较意外。事实上,原来的模型做得比较粗糙,尤其是准确率难登大雅之台,参考价值不大。这几天重新折腾了一下,弄了个准确率高一点的模型,同时也把样本公开给大家。
模型的思路跟《端到端的腾讯验证码识别(46%正确率)》是一样的,只不过把CNN部分换成了现成的Xception结构,当然,读者也可以换VGG、Resnet50等玩玩,事实上对验证码识别来说,这些模型都能够胜任。我挑选Xception,是因为它层数不多,模型权重也较小,我比较喜欢而已。
代码
8
Jun
互怼的艺术:从零直达WGAN-GP
By 苏剑林 | 2017-06-08 | 289057位读者 | 引用前言
GAN,全称Generative Adversarial Nets,中文名是生成对抗式网络。对于GAN来说,最通俗的解释就是“伪造者-鉴别者”的解释,如艺术画的伪造者和鉴别者。一开始伪造者和鉴别者的水平都不高,但是鉴别者还是比较容易鉴别出伪造者伪造出来的艺术画。但随着伪造者对伪造技术的学习后,其伪造的艺术画会让鉴别者识别错误;或者随着鉴别者对鉴别技术的学习后,能够很简单的鉴别出伪造者伪造的艺术画。这是一个双方不断学习技术,以达到最高的伪造和鉴别水平的过程。 然而,稍微深入了解的读者就会发现,跟现实中的造假者不同,造假者会与时俱进地使用新材料新技术来造假,而GAN最神奇而又让人困惑的地方是它能够将随机噪声映射为我们所希望的正样本,有噪声就有正样本,这不是无本生意吗,多划算~
另一个情况是,自从WGAN提出以来,基本上GAN的主流研究都已经变成了WGAN上去了,但WGAN的形式事实上已经跟“伪造者-鉴别者”差得比较远了。而且WGAN虽然最后的形式并不复杂,但是推导过程却用到了诸多复杂的数学,使得我无心研读原始论文。这迫使我要找从一条简明直观的线索来理解GAN。幸好,经过一段时间的思考,有点收获。
6
Aug
五种零食揭示宇宙的形状
By 苏剑林 | 2009-08-06 | 20725位读者 | 引用
4
Jan
智能家居之热水器零冷水技术原理浅析
By 苏剑林 | 2023-01-04 | 43361位读者 | 引用如果家庭使用单一的热水器集中供热水,那么当我们想要用热水时,往往需要先放一段时间的冷水,而如果放冷水时间比较长的话,就会比较影响体验。所谓零冷水,实际上就是想办法提前把热水管中的冷水排放掉,以达到(几乎)瞬间出热水的效果。事实上,零冷水并不是什么高大上的技术,但可能由于观念没跟上、理解上有误等原因,零冷水技术还没有在家庭中得到普及,不过随着大家对生活品质的要求越来越高,零冷水确实在慢慢流行起来了。
本文来简单分析一下零冷水技术的实现原理,包括各种方案的优缺点和自省DIY的参考思路。
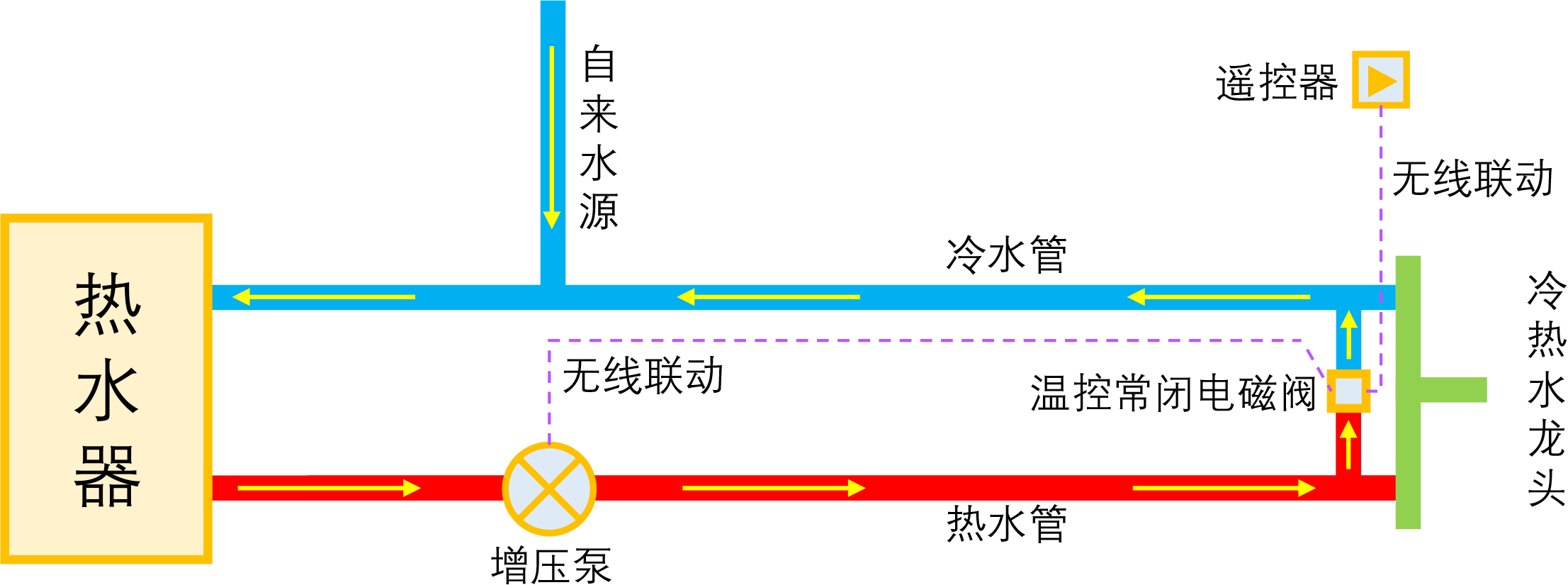
理想的零冷水方案
写在前面
在文章开始,需要纠正很多人的一个错误观念:零冷水不是为了省钱,而是为了提升生活品质。如果你是省钱最大的心态,那么接下来的内容就可以不用看了,零冷水技术对你毫无价值。

最近评论