






15
Dec
生成扩散模型漫谈(十四):构建ODE的一般步骤(上)
By 苏剑林 | 2022-12-15 | 57245位读者 | 引用书接上文,在《生成扩散模型漫谈(十三):从万有引力到扩散模型》中,我们介绍了一个由万有引力启发的、几何意义非常清晰的ODE式生成扩散模型。有的读者看了之后就疑问:似乎“万有引力”并不是唯一的选择,其他形式的力是否可以由同样的物理绘景构建扩散模型?另一方面,该模型在物理上确实很直观,但还欠缺从数学上证明最后确实能学习到数据分布。
本文就尝试从数学角度比较精确地回答“什么样的力场适合构建ODE式生成扩散模型”这个问题。
基础结论
要回答这个问题,需要用到在《生成扩散模型漫谈(十二):“硬刚”扩散ODE》中我们推导过的一个关于常微分方程对应的分布变化的结论。
考虑$\boldsymbol{x}_t\in\mathbb{R}^d, t\in[0,T]$的一阶(常)微分方程(组)
\begin{equation}\frac{d\boldsymbol{x}_t}{dt}=\boldsymbol{f}_t(\boldsymbol{x}_t)\label{eq:ode}\end{equation}
4
Jan
智能家居之热水器零冷水技术原理浅析
By 苏剑林 | 2023-01-04 | 45449位读者 | 引用如果家庭使用单一的热水器集中供热水,那么当我们想要用热水时,往往需要先放一段时间的冷水,而如果放冷水时间比较长的话,就会比较影响体验。所谓零冷水,实际上就是想办法提前把热水管中的冷水排放掉,以达到(几乎)瞬间出热水的效果。事实上,零冷水并不是什么高大上的技术,但可能由于观念没跟上、理解上有误等原因,零冷水技术还没有在家庭中得到普及,不过随着大家对生活品质的要求越来越高,零冷水确实在慢慢流行起来了。
本文来简单分析一下零冷水技术的实现原理,包括各种方案的优缺点和自省DIY的参考思路。
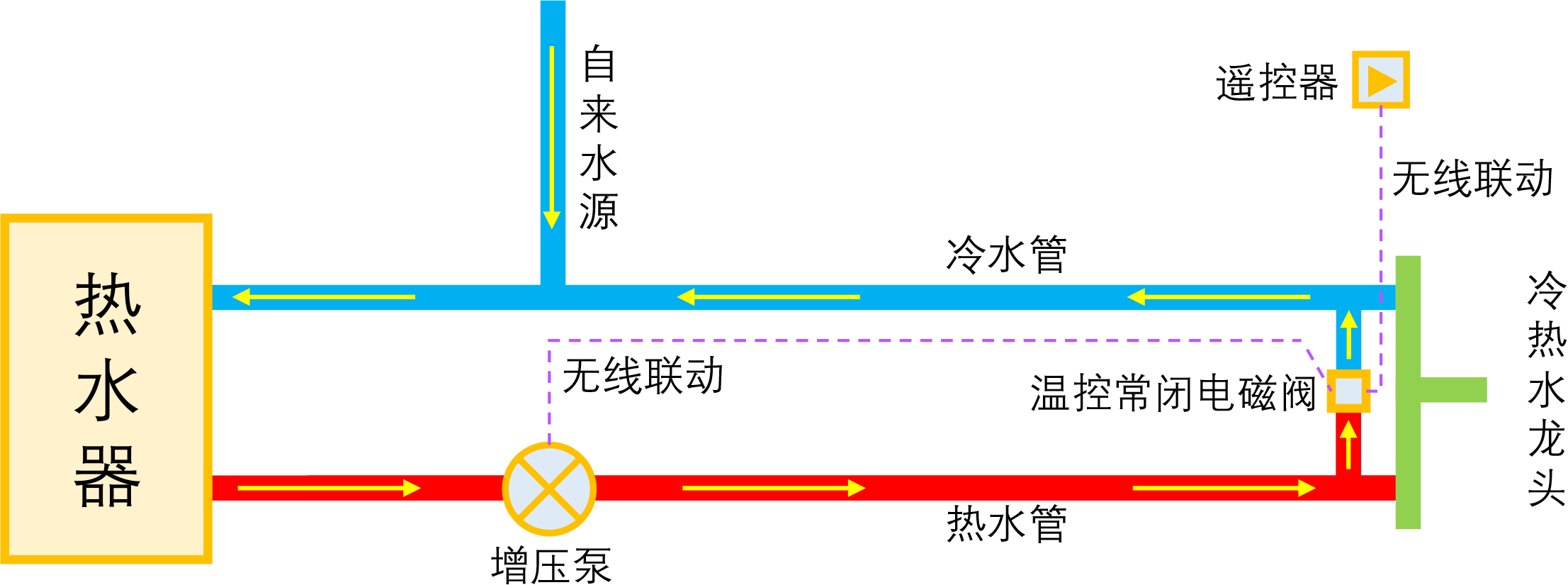
理想的零冷水方案
写在前面
在文章开始,需要纠正很多人的一个错误观念:零冷水不是为了省钱,而是为了提升生活品质。如果你是省钱最大的心态,那么接下来的内容就可以不用看了,零冷水技术对你毫无价值。
25
Apr
注意力和Softmax的两点有趣发现:鲁棒性和信息量
By 苏剑林 | 2023-04-25 | 30843位读者 | 引用最近几周笔者一直都在思考注意力机制的相关性质,在这个过程中对注意力及Softmax有了更深刻的理解。在这篇文章中,笔者简单分享其中的两点:
1、Softmax注意力天然能够抵御一定的噪声扰动;
2、从信息熵角度也可以对初始化问题形成直观理解。
鲁棒性
基于Softmax归一化的注意力机制,可以写为
\begin{equation}o = \frac{\sum\limits_{i=1}^n e^{s_i} v_i}{\sum\limits_{i=1}^n e^{s_i}}\end{equation}
有一天笔者突然想到一个问题:如果往$s_i$中加入独立同分布的噪声会怎样?
14
Mar
缓解交叉熵过度自信的一个简明方案
By 苏剑林 | 2023-03-14 | 33234位读者 | 引用众所周知,分类问题的常规评估指标是正确率,而标准的损失函数则是交叉熵,交叉熵有着收敛快的优点,但它并非是正确率的光滑近似,这就带来了训练和预测的不一致性问题。另一方面,当训练样本的预测概率很低时,交叉熵会给出一个非常巨大的损失(趋于$-\log 0^{+}=\infty$),这意味着交叉熵会特别关注预测概率低的样本——哪怕这个样本可能是“脏数据”。所以,交叉熵训练出来的模型往往有过度自信现象,即每个样本都给出较高的预测概率,这会带来两个副作用:一是对脏数据的过度拟合带来的效果下降,二是预测的概率值无法作为不确定性的良好指标。
围绕交叉熵的改进,学术界一直都有持续输出,目前这方面的研究仍处于“八仙过海,各显神通”的状态,没有标准答案。在这篇文章中,我们来学习一下论文《Tailoring Language Generation Models under Total Variation Distance》给出的该问题的又一种简明的候选方案。
14
Feb
生成扩散模型漫谈(十六):W距离 ≤ 得分匹配
By 苏剑林 | 2023-02-14 | 24197位读者 | 引用Wasserstein距离(下面简称“W距离”),是基于最优传输思想来度量两个概率分布差异程度的距离函数,笔者之前在《从Wasserstein距离、对偶理论到WGAN》等博文中也做过介绍。对于很多读者来说,第一次听说W距离,是因为2017年出世的WGAN,它开创了从最优传输视角来理解GAN的新分支,也提高了最优传输理论在机器学习中的地位。很长一段时间以来,GAN都是生成模型领域的“主力军”,直到最近这两年扩散模型异军突起,GAN的风头才有所下降,但其本身仍不失为一个强大的生成模型。
从形式上来看,扩散模型和GAN差异很明显,所以其研究一直都相对独立。不过,去年底的一篇论文《Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance》打破了这个隔阂:它证明了扩散模型的得分匹配损失可以写成W距离的上界形式。这意味着在某种程度上,最小化扩散模型的损失函数,实则跟WGAN一样,都是在最小化两个分布的W距离。
16
Feb
Google新搜出的优化器Lion:效率与效果兼得的“训练狮”
By 苏剑林 | 2023-02-16 | 51310位读者 | 引用昨天在Arixv上发现了Google新发的一篇论文《Symbolic Discovery of Optimization Algorithms》,主要是讲自动搜索优化器的,咋看上去没啥意思,因为类似的工作也有不少,大多数结果都索然无味。然而,细读之下才发现别有洞天,原来作者们通过数千TPU小时的算力搜索并结合人工干预,得到了一个速度更快、显存更省的优化器Lion(EvoLved Sign Momentum,不得不吐槽这名字起得真勉强),并在图像分类、图文匹配、扩散模型、语言模型预训练和微调等诸多任务上做了充分的实验,多数任务都显示Lion比目前主流的AdamW等优化器有着更好的效果。
更省显存还更好效果,真可谓是鱼与熊掌都兼得了,什么样的优化器能有这么强悍的性能?本文一起来欣赏一下论文的成果。
先说结果
本文主要关心搜索出来的优化器本身,所以关于搜索过程的细节就不讨论了,对此有兴趣读者自行看原论文就好。Lion优化器的更新过程为
\begin{equation}\text{Lion}:=\left\{\begin{aligned}
&\boldsymbol{u}_t = \text{sign}\big(\beta_1 \boldsymbol{m}_{t-1} + \left(1 - \beta_1\right) \boldsymbol{g}_t\big) \\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}) \\
&\boldsymbol{m}_t = \beta_2 \boldsymbol{m}_{t-1} + \left(1 - \beta_2\right) \boldsymbol{g}_t
\end{aligned}\right.\end{equation}
8
Jun
Naive Bayes is all you need ?
By 苏剑林 | 2023-06-08 | 47424位读者 | 引用很抱歉,起了这么个具有标题党特征的题目。在写完《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度》之后,笔者就觉得朴素贝叶斯(Naive Bayes)跟Attention机制有很多相同的特征,后来再推导了一下发现,Attention机制其实可以看成是一种广义的、参数化的朴素贝叶斯。既然如此,“Attention is All You Need”不也就意味着“Naive Bayes is all you need”了?这就是本文标题的缘由。
接下来笔者将介绍自己的思考过程,分析如何从朴素贝叶斯角度来理解Attention机制。
朴素贝叶斯
本文主要考虑语言模型,它要建模的是$p(x_t|x_1,\cdots,x_{t-1})$。根据贝叶斯公式,我们有
\begin{equation}p(x_t|x_1,\cdots,x_{t-1}) = \frac{p(x_1,\cdots,x_{t-1}|x_t)p(x_t)}{p(x_1,\cdots,x_{t-1})}\propto p(x_1,\cdots,x_{t-1}|x_t)p(x_t)\end{equation}
16
Jun
梯度流:探索通向最小值之路
By 苏剑林 | 2023-06-16 | 32947位读者 | 引用在这篇文章中,我们将探讨一个被称为“梯度流(Gradient Flow)”的概念。简单来说,梯度流是将我们在用梯度下降法中寻找最小值的过程中的各个点连接起来,形成一条随(虚拟的)时间变化的轨迹,这条轨迹便被称作“梯度流”。在文章的后半部分,我们将重点讨论如何将梯度流的概念扩展到概率空间,从而形成“Wasserstein梯度流”,为我们理解连续性方程、Fokker-Planck方程等内容提供一个新的视角。
梯度下降
假设我们想搜索光滑函数$f(\boldsymbol{x})$的最小值,常见的方案是梯度下降(Gradient Descent),即按照如下格式进行迭代:
\begin{equation}\boldsymbol{x}_{t+1} = \boldsymbol{x}_t -\alpha \nabla_{\boldsymbol{x}_t}f(\boldsymbol{x}_t)\label{eq:gd-d}\end{equation}
如果$f(\boldsymbol{x})$关于$\boldsymbol{x}$是凸的,那么梯度下降通常能够找到最小值点;相反,则通常只能收敛到一个“驻点”——即梯度为0的点,比较理想的情况下能收敛到一个极小值(局部最小值)点。这里没有对极小值和最小值做严格区分,因为在深度学习中,即便是收敛到一个极小值点也是很难得的了。

最近评论