






11
Dec
从动力学角度看优化算法(六):为什么SimSiam不退化?
By 苏剑林 | 2020-12-11 | 79510位读者 | 引用自SimCLR以来,CV中关于无监督特征学习的工作层出不穷,让人眼花缭乱。这些工作大多数都是基于对比学习的,即通过适当的方式构造正负样本进行分类学习的。然而,在众多类似的工作中总有一些特立独行的研究,比如Google的BYOL和最近的SimSiam,它们提出了单靠正样本就可以完成特征学习的方案,让人觉得耳目一新。但是没有负样本的支撑,模型怎么不会退化(坍缩)为一个没有意义的常数模型呢?这便是这两篇论文最值得让人思考和回味的问题了。
其中SimSiam给出了让很多人都点赞的答案,但笔者觉得SimSiam也只是把问题换了种说法,并没有真的解决这个问题。笔者认为,像SimSiam、GAN等模型的成功,很重要的原因是使用了基于梯度的优化器(而非其他更强或者更弱的优化器),所以不结合优化动力学的答案都是不完整的。在这里,笔者尝试结合动力学来分析SimSiam不会退化的原因。
SimSiam
在看SimSiam之前,我们可以先看看BYOL,来自论文《Bootstrap your own latent: A new approach to self-supervised Learning》,其学习过程很简单,就是维护两个编码器Student和Teacher,其中Teacher是Student的滑动平均,Student则又反过来向Teacher学习,有种“左脚踩右脚”就可以飞起来的感觉。示意图如下:
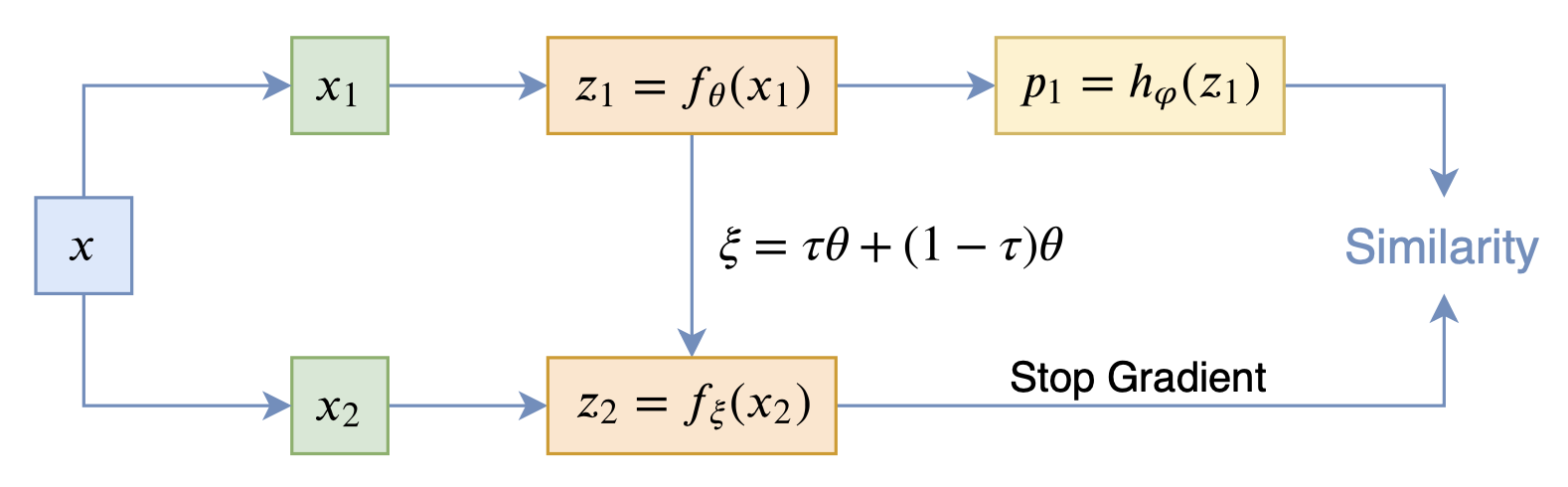
BYOL示意图
24
Dec
RealFormer:把残差转移到Attention矩阵上面去
By 苏剑林 | 2020-12-24 | 93774位读者 | 引用大家知道Layer Normalization是Transformer模型的重要组成之一,它的用法有PostLN和PreLN两种,论文《On Layer Normalization in the Transformer Architecture》中有对两者比较详细的分析。简单来说,就是PreLN对梯度下降更加友好,收敛更快,对训练时的超参数如学习率等更加鲁棒等,反正一切都好但就有一点硬伤:PreLN的性能似乎总略差于PostLN。最近Google的一篇论文《RealFormer: Transformer Likes Residual Attention》提出了RealFormer设计,成功地弥补了这个Gap,使得模型拥有PreLN一样的优化友好性,并且效果比PostLN还好,可谓“鱼与熊掌兼得”了。
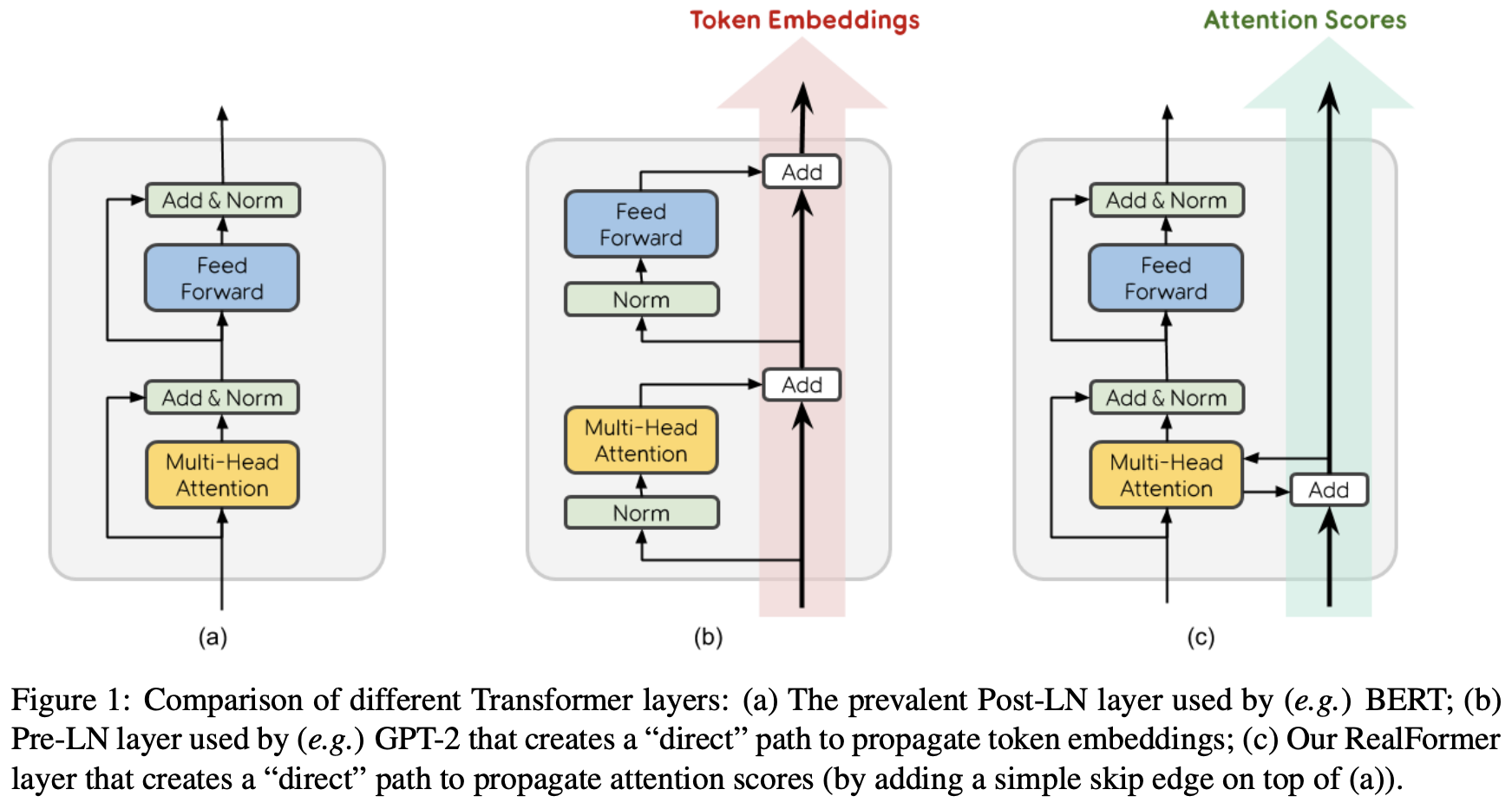
PostLN、PreLN和RealFormer结构示意图
11
Jan
你可能不需要BERT-flow:一个线性变换媲美BERT-flow
By 苏剑林 | 2021-01-11 | 204363位读者 | 引用BERT-flow来自论文《On the Sentence Embeddings from Pre-trained Language Models》,中了EMNLP 2020,主要是用flow模型校正了BERT出来的句向量的分布,从而使得计算出来的cos相似度更为合理一些。由于笔者定时刷Arixv的习惯,早在它放到Arxiv时笔者就看到了它,但并没有什么兴趣,想不到前段时间小火了一把,短时间内公众号、知乎等地出现了不少的解读,相信读者们多多少少都被它刷屏了一下。
从实验结果来看,BERT-flow确实是达到了一个新SOTA,但对于这一结果,笔者的第一感觉是:不大对劲!当然,不是说结果有问题,而是根据笔者的理解,flow模型不大可能发挥关键作用。带着这个直觉,笔者做了一些分析,果不其然,笔者发现尽管BERT-flow的思路没有问题,但只要一个线性变换就可以达到相近的效果,flow模型并不是十分关键。
余弦相似度的假设
一般来说,我们语义相似度比较或检索,都是给每个句子算出一个句向量来,然后算它们的夹角余弦来比较或者排序。那么,我们有没有思考过这样的一个问题:余弦相似度对所输入的向量提出了什么假设呢?或者说,满足什么条件的向量用余弦相似度做比较效果会更好呢?
8
Jul
两个多元正态分布的KL散度、巴氏距离和W距离
By 苏剑林 | 2021-07-08 | 103428位读者 | 引用正态分布是最常见的连续型概率分布之一。它是给定均值和协方差后的最大熵分布(参考《“熵”不起:从熵、最大熵原理到最大熵模型(二)》),也可以看作任意连续型分布的二阶近似,它的地位就相当于一般函数的线性近似。从这个角度来看,正态分布算得上是最简单的连续型分布了。也正因为简单,所以对于很多估计量来说,它都能写出解析解来。
本文主要来计算两个多元正态分布的几种度量,包括KL散度、巴氏距离和W距离,它们都有显式解析解。
正态分布
这里简单回顾一下正态分布的一些基础知识。注意,仅仅是回顾,这还不足以作为正态分布的入门教程。
概率密度
正态分布,也即高斯分布,是定义在$\mathbb{R}^n$上的连续型概率分布,其概率密度函数为
\begin{equation}p(\boldsymbol{x})=\frac{1}{\sqrt{(2\pi)^n \det(\boldsymbol{\Sigma})}}\exp\left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\top}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right\}\end{equation}
29
Jun
UniVAE:基于Transformer的单模型、多尺度的VAE模型
By 苏剑林 | 2021-06-29 | 72345位读者 | 引用
17
Aug
浅谈Transformer的初始化、参数化与标准化
By 苏剑林 | 2021-08-17 | 170609位读者 | 引用前几天在训练一个新的Transformer模型的时候,发现怎么训都不收敛了。经过一番debug,发现是在做Self Attention的时候$\boldsymbol{Q}\boldsymbol{K}^{\top}$之后忘记除以$\sqrt{d}$了,于是重新温习了一下为什么除以$\sqrt{d}$如此重要的原因。当然,Google的T5确实是没有除以$\sqrt{d}$的,但它依然能够正常收敛,那是因为它在初始化策略上做了些调整,所以这个事情还跟初始化有关。
藉着这个机会,本文跟大家一起梳理一下模型的初始化、参数化和标准化等内容,相关讨论将主要以Transformer为心中展开。
采样分布
初始化自然是随机采样的的,所以这里先介绍一下常用的采样分布。一般情况下,我们都是从指定均值和方差的随机分布中进行采样来初始化。其中常用的随机分布有三个:正态分布(Normal)、均匀分布(Uniform)和截尾正态分布(Truncated Normal)。
13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 394267位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
28
Jun
“维度灾难”之Hubness现象浅析
By 苏剑林 | 2022-06-28 | 38124位读者 | 引用这几天读到论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》,了解到了一个新的名词“Hubness现象”,说的是高维空间中的一种聚集效应,本质上是“维度灾难”的体现之一。论文借助Hubness的概念得到了一个提升GAN模型生成质量的方案,看起来还蛮有意思。所以笔者就顺便去学习了一下Hubness现象的相关内容,记录在此,供大家参考。
坍缩的球
“维度灾难”是一个很宽泛的概念,所有在高维空间中与相应的二维、三维空间版本出入很大的结论,都可以称之为“维度灾难”,比如《n维空间下两个随机向量的夹角分布》中介绍的“高维空间中任何两个向量几乎都是垂直的”。其中,有不少维度灾难现象有着同一个源头——“高维空间单位球与其外切正方体的体积之比逐渐坍缩至0”,包括本文的主题“Hubness现象”亦是如此。

最近评论