






13
Aug
exp(1/2 t^2+xt)级数展开的图解技术
By 苏剑林 | 2015-08-13 | 31107位读者 | 引用本文要研究的是关于$t$的函数
$$\exp\left(\frac{1}{2}t^2+xt\right)$$
在$t=0$处的泰勒展开式。显然,它并不困难,手算或者软件都可以做出来,答案是:
$$1+x t+\frac{1}{2} \left(x^2+1\right) t^2+\frac{1}{6}\left(x^3+3 x\right) t^3 +\frac{1}{24} \left(x^4+6 x^2+3\right) t^4 + \dots$$
不过,本文将会给出笔者构造的该级数的一个图解方法。通过这个图解方法比较比较直观而方便地手算出展开式的前面一些项。后面我们再来谈谈这种图解技术的起源以及进一步的应用。
级数的图解方法:说明
首先,很明显要写出这个级数,关键是写出展开式的每一项,也就是要求出
$$f_k (x) = \left.\frac{d^k}{dt^k}\exp\left(\frac{1}{2}t^2+xt\right)\right|_{t=0}$$
$f_k (x)$是一个关于$x$的$k$次整系数多项式,$k$是展开式的阶,也是求导的阶数。
这里,我们用一个“点”表示一个$x$,用“两点之间的一条直线”表示“相乘”,那么,$x^2$就可以表示成

x^2项
13
Nov
ARXIV数学论文分布:偏微分方程最热门!
By 苏剑林 | 2015-11-13 | 31256位读者 | 引用笔者成功地保研到了中山大学的基础数学专业,这个专业自然是比较理论性的,虽然如此,我还会保持着我对数据分析、计算机等方面的兴趣。这几天兴致来了,想做一下结合我的专业跟数据挖掘相结合的研究,所以就爬取了ARXIV上面近五年(2010年到2014年)的数学论文(包含的数据有:标题、分类、年份、月份),想对这几年来数学的“行情”做一下简单的分析。个人认为,ARVIX作为目前全球最大的论文预印本的电子数据库,对它的数据进行分析,所得到的结论是能够具有一定的代表性的。
当然,本文只是用来练手爬虫和基本数据分析的文章,并没有挖掘出特别有价值的信息。文末附录了笔者爬取到的数据,供有兴趣的读者进一步分析研究。
整体情况
这五年来,ARXIV的数学论文总数为135009篇,平均每年27000篇,或者每天74篇。
3
Aug
运动相机测试:家乡的星空
By 苏剑林 | 2016-08-03 | 38072位读者 | 引用记得很早之前就想尝试一下拍星空,无奈一直都没有设备。以前只知道单反可以拍星空,因此,一直以来的想法就是有钱了就去买台单反。因为各种原因一拖再拖,最后慢慢觉得,对于我这种三分钟热度的人来说,单反的意义还真的不是很大。
这两年,在小米的鼓吹下,小蚁运动相机在国内算是慢慢掀起了一股运动相机潮。这种相机的特点是小巧、灵活,价格也不贵(相比单反)。灵活不仅仅是说它便于携带,而且还是功能上的灵活,比如一代小蚁还支持编程拍摄!(写程序控制快门、ISO、拍摄间隔,并实现定时拍摄等)这样当然很快就吸引了我,在小蚁2代众筹之时,我也咬咬牙,入了一台。
前两天回到家,刚好晴夜,马上就试了一下拍星空的效果。下面是在我家楼顶拍的,用ISO400曝光30秒的效果:

家乡的星空
最近一直在考虑一些自然语言处理问题和一些非线性分析问题,无暇总结发文,在此表示抱歉。本文要说的是对于一阶非线性差分方程(当然高阶也可以类似地做)的一种摄动格式,理论上来说,本方法可以得到任意一阶非线性差分方程的显式渐近解。
非线性差分方程
对于一般的一阶非线性差分方程
$$\begin{equation}\label{chafenfangcheng}x_{n+1}-x_n = f(x_n)\end{equation}$$
通常来说,差分方程很少有解析解,因此要通过渐近分析等手段来分析非线性差分方程的性质。很多时候,我们首先会考虑将差分替换为求导,得到微分方程
$$\begin{equation}\label{weifenfangcheng}\frac{dx}{dn}=f(x)\end{equation}$$
作为差分方程$\eqref{chafenfangcheng}$的近似。其中的原因,除了微分方程有比较简单的显式解之外,另一重要原因是微分方程$\eqref{weifenfangcheng}$近似保留了差分方程$\eqref{chafenfangcheng}$的一些比较重要的性质,如渐近性。例如,考虑离散的阻滞增长模型:
$$\begin{equation}\label{zuzhizengzhang}x_{n+1}=(1+\alpha)x_n -\beta x_n^2\end{equation}$$
对应的微分方程为(差分替换为求导):
$$\begin{equation}\frac{dx}{dn}=\alpha x -\beta x^2\end{equation}$$
此方程解得
$$\begin{equation}x_n = \frac{\alpha}{\beta+c e^{-\alpha n}}\end{equation}$$
其中$c$是任意常数。上述结果已经大概给出了原差分方程$\eqref{zuzhizengzhang}$的解的变化趋势,并且成功给出了最终的渐近极限$x_n \to \frac{\alpha}{\beta}$。下图是当$\alpha=\beta=1$且$c=1$(即$x_0=\frac{1}{2}$)时,微分方程的解与差分方程的解的值比较。
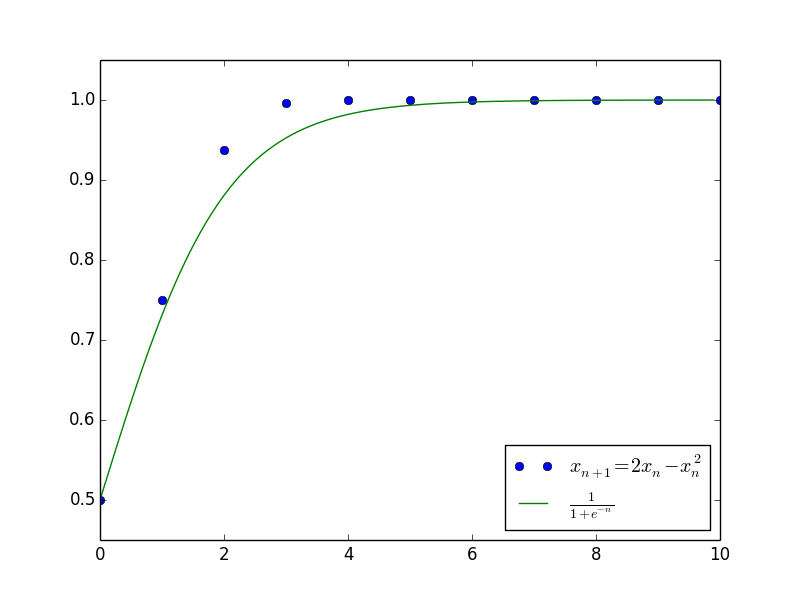
差分方程的摄动法1
现在的问题是,既然微分方程的解可以作为一个形态良好的近似解了,那么是否可以在微分方程的解的基础上,进一步加入修正项提高精度?
6
Dec
人生苦短,我用Python!
By 苏剑林 | 2015-12-06 | 56548位读者 | 引用
11
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(二)
By 苏剑林 | 2015-12-11 | 83462位读者 | 引用上集回顾
在第一篇中,笔者介绍了“熵”这个概念,以及它的一些来龙去脉。熵的公式为
$$S=-\sum_x p(x)\log p(x)\tag{1}$$
或
$$S=-\int p(x)\log p(x) dx\tag{2}$$
并且在第一篇中,我们知道熵既代表了不确定性,又代表了信息量,事实上它们是同一个概念。
说完了熵这个概念,接下来要说的是“最大熵原理”。最大熵原理告诉我们,当我们想要得到一个随机事件的概率分布时,如果没有足够的信息能够完全确定这个概率分布(可能是不能确定什么分布,也可能是知道分布的类型,但是还有若干个参数没确定),那么最为“保险”的方案是选择使得熵最大的分布。
最大熵原理
承认我们的无知
很多文章在介绍最大熵原理的时候,会引用一句著名的句子——“不要把鸡蛋放在同一个篮子里”——来通俗地解释这个原理。然而,笔者窃以为这句话并没有抓住要点,并不能很好地体现最大熵原理的要义。笔者认为,对最大熵原理更恰当的解释是:承认我们的无知!
20
Jan
简单的迅雷VIP账号获取器(Python)
By 苏剑林 | 2016-01-20 | 31959位读者 | 引用在Windows工作的时候,经常会用迅雷下载东西,如果速度慢或者没资源,尤其是一些比较冷门的视频,迅雷的VIP会员服务总能够帮上大忙。后来无意间发现了有个“迅雷VIP账号获取器”的软件,可以获取一些临时的VIP账号供使用,这可是个好东西,因为开通迅雷会员虽然不贵,但是我又不经常下载,所以老感觉有点浪费,而有了这个之后,我随时下点东西都可以免费用了。
简单的迅雷VIP账号获取器
最近转移到了Mac上,而Mac也有迅雷,但那个账号获取器是exe的,不能在Mac运行。本以为获取器的构造会很复杂,谁知道,经过抓包研究,发现那个账号获取器的原理极其简单,说白了,就是一个简单的爬虫,以下这两个网站提供账号,它就到相应的抓取账号而已:
http://yunbo.xinjipin.com/
http://www.fenxs.com
据此,我也用Python简单写了一个,主要是方便我在Mac使用。读者如果有需要,也可以下载使用,代码兼容2.x和3.x的版本。主要的库是requests和re,pandas和sys的使用只不过是为了更加人性化。本来想用Tkinter写一个简单的GUI的,但是想想看,还是没必要了~~
20
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(三)
By 苏剑林 | 2015-12-20 | 68686位读者 | 引用上集回顾
在上一篇文章中,笔者分享了自己对最大熵原理的认识,包括最大熵原理的意义、最大熵原理的求解以及一些简单而常见的最大熵原理的应用。在上一篇的文末,我们还通过最大熵原理得到了正态分布,以此来说明最大熵原理的深刻内涵和广泛意义。
本文中,笔者将介绍基于最大熵原理的模型——最大熵模型。本文以有监督的分类问题来介绍最大熵模型,所谓有监督,就是基于已经标签好的数据进行的。
事实上,第二篇文章的最大熵原理才是主要的,最大熵模型,实质上只是最大熵原理的一个延伸,或者说应用。
最大熵模型
分类:意味着什么?
在引入最大熵模型之前,我们先来多扯一点东西,谈谈分类问题意味着什么。假设我们有一批标签好的数据:
$$\begin{array}{c|cccccccc}
\hline
\text{数据}x & 1 & 2 & 3 & 4 & 5 & 6 & \dots & 100 \\
\hline
\text{标签}y & 1 & 0 & 1 & 0 & 1 & 0 & \dots & 0\\
\hline \end{array}$$

最近评论