






20
Jan
简单的迅雷VIP账号获取器(Python)
By 苏剑林 | 2016-01-20 | 31237位读者 | 引用在Windows工作的时候,经常会用迅雷下载东西,如果速度慢或者没资源,尤其是一些比较冷门的视频,迅雷的VIP会员服务总能够帮上大忙。后来无意间发现了有个“迅雷VIP账号获取器”的软件,可以获取一些临时的VIP账号供使用,这可是个好东西,因为开通迅雷会员虽然不贵,但是我又不经常下载,所以老感觉有点浪费,而有了这个之后,我随时下点东西都可以免费用了。
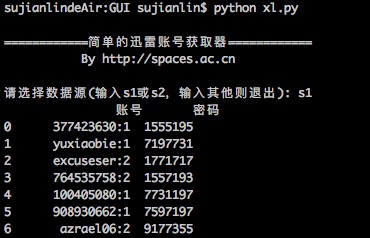
简单的迅雷VIP账号获取器
最近转移到了Mac上,而Mac也有迅雷,但那个账号获取器是exe的,不能在Mac运行。本以为获取器的构造会很复杂,谁知道,经过抓包研究,发现那个账号获取器的原理极其简单,说白了,就是一个简单的爬虫,以下这两个网站提供账号,它就到相应的抓取账号而已:
http://yunbo.xinjipin.com/
http://www.fenxs.com
据此,我也用Python简单写了一个,主要是方便我在Mac使用。读者如果有需要,也可以下载使用,代码兼容2.x和3.x的版本。主要的库是requests和re,pandas和sys的使用只不过是为了更加人性化。本来想用Tkinter写一个简单的GUI的,但是想想看,还是没必要了~~
20
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(三)
By 苏剑林 | 2015-12-20 | 66133位读者 | 引用上集回顾
在上一篇文章中,笔者分享了自己对最大熵原理的认识,包括最大熵原理的意义、最大熵原理的求解以及一些简单而常见的最大熵原理的应用。在上一篇的文末,我们还通过最大熵原理得到了正态分布,以此来说明最大熵原理的深刻内涵和广泛意义。
本文中,笔者将介绍基于最大熵原理的模型——最大熵模型。本文以有监督的分类问题来介绍最大熵模型,所谓有监督,就是基于已经标签好的数据进行的。
事实上,第二篇文章的最大熵原理才是主要的,最大熵模型,实质上只是最大熵原理的一个延伸,或者说应用。
最大熵模型
分类:意味着什么?
在引入最大熵模型之前,我们先来多扯一点东西,谈谈分类问题意味着什么。假设我们有一批标签好的数据:
$$\begin{array}{c|cccccccc}
\hline
\text{数据}x & 1 & 2 & 3 & 4 & 5 & 6 & \dots & 100 \\
\hline
\text{标签}y & 1 & 0 & 1 & 0 & 1 & 0 & \dots & 0\\
\hline \end{array}$$
9
Jan
《量子力学与路径积分》习题解答V0.4
By 苏剑林 | 2016-01-09 | 31226位读者 | 引用
流年
《量子力学与路径积分》的习题解答终于艰难地推进到了0.4版本,目前已经基本完成了前7章的习题。
今天已经是2016年1月9号了,2015年已经远去,都忘记跟大家说一声新年快乐了,实在抱歉。在这里补充一句:祝大家新年快乐,事事如意!。
笔者已经大四了,现在是临近期末考,又临近毕业。最近忙的事情有很多,其中之一是我加入了一个互联网小公司的创业队伍中,负责文本挖掘,偶尔也写写爬虫,等等,感觉自己进去之后,增长了不少见识,也增加了不少技术知识,较之我上一次实习,又有不一样的高度。现在里边有好几样事情排队着做,可谓忙得不亦悦乎了。还有,我也开始写毕业论文了,早点写完能够多点时间,学学自己喜欢的东西,毕业论文我写的是路径积分相关的内容,自我感觉写得还是比较清楚易懂的,等时机成熟了,发出来,向大家普及路径积分^_^。此外,每天做点路径积分的习题,也要消耗不少时间,有些比较难的题目,基本一道就做几个早上才能写出比较满意的答案。总感觉想学的想做的事情有很多,可是时间很少。
18
Jan
当大数据进入厨房:让大数据教你做菜!
By 苏剑林 | 2016-01-18 | 41197位读者 | 引用说在前面

美食(图片来源于互联网)
在空间侧边栏的笔者的自我介绍中,有一行是“厨房爱好者”,虽然笔者不怎么会做菜,但确实,厨房是我的一个爱好。当然,笔者的爱好很多,数学、物理、天文、计算机等,都喜欢,都想学,弄到多而不精。在之前的文章中也已经提到过,数据挖掘也是我的一个爱好,而当数据挖掘跟厨房这两个爱好相遇了,会有什么有趣的结果吗?
笔者正是做了这样一个事情:从美食中国的家常菜目录下面,写了个简单的爬虫,抓取了一批菜谱数据下来,进行简单的数据分析。(在此对美食中国表示衷心感谢。选择美食中国的原因是它的数据比较规范。)数据分析在我目前公司的高性能服务器做,分析起来特别舒服~~
这里共收集了18209个菜谱,共包含了9700种食材(包括主料、辅料、调料,部分可能由于命名不规范等原因会重复)。当然,这个数据量相对于很多领域的大数据标准来说,实在不值一提。但是在大数据极少涉及的厨房,应该算是比较多的了。
15
Feb
积分估计的极值原理——变分原理的初级版本
By 苏剑林 | 2016-02-15 | 34286位读者 | 引用如果一直关注科学空间的朋友会发现,笔者一直对极值原理有偏爱。比如,之前曾经写过一系列《自然极值》的文章,介绍一些极值问题和变分法;在物理学中,笔者偏爱最小作用量原理的形式;在数据挖掘中,笔者也因此对基于最大熵原理的最大熵模型有浓厚的兴趣;最近,在做《量子力学与路径积分》的习题中,笔者也对第十一章所说的变分原理产生了很大的兴趣。
对于一样新东西,笔者的学习方法是以一个尽可能简单的例子搞清楚它的原理和思想,然后再逐步复杂化,这样子我就不至于迷失了。对于变分原理,它是估算路径积分的一个很强大的方法,路径积分是泛函积分,或者说,无穷维积分,那么很自然想到,对于有限维的积分估计,比如最简单的一维积分,有没有类似的估算原理呢?事实上是有的,它并不复杂,弄懂它有助于了解变分原理的核心思想。很遗憾,我并没有找到已有的资料描述这个简化版的原理,可能跟我找的资料比较少有关。
从高斯型积分出发
变分原理本质上是Jensen不等式的应用。我们从下述积分出发
$$\begin{equation}\label{jifen}I(\epsilon)=\int_{-\infty}^{\infty}e^{-x^2-\epsilon x^4}dx\end{equation}$$
20
Feb
熵的形象来源与熵的妙用
By 苏剑林 | 2016-02-20 | 30200位读者 | 引用在拙作《“熵”不起:从熵、最大熵原理到最大熵模型(一)》中,笔者从比较“专业”的角度引出了熵,并对熵做了诠释。当然,熵作为不确定性的度量,应该具有更通俗、更形象的来源,本文就是试图补充这一部分,并由此给出一些妙用。
熵的形象来源
我们考虑由0-9这十个数字组成的自然数,如果要求小于10000的话,那么很自然有10000个,如果我们说“某个小于10000的自然数”,那么0~9999都有可能出现,那么10000便是这件事的不确定性的一个度量。类似地,考虑$n$个不同元素(可重复使用)组成的长度为$m$的序列,那么这个序列有$n^m$种情况,这时$n^m$也是这件事情的不确定性的度量。
$n^m$是指数形式的,数字可能异常地大,因此我们取了对数,得到$m\log n$,这也可以作为不确定性的度量,它跟我们原来熵的定义是一致的。因为
$$m\log n=-\sum_{i=1}^{n^m} \frac{1}{n^m}\log \frac{1}{n^m}$$
读者可能会疑惑,$n^m$和$m\log n$都算是不确定性的度量,那么究竟是什么原因决定了我们用$m\log n$而不是用$n^m$呢?答案是可加性。取对数后的度量具有可加性,方便我们运算。当然,可加性只是便利的要求,并不是必然的。如果使用$n^m$形式,那么就相应地具有可乘性。
6
Mar
Openwrt自动扫描WiFi并连接中继
By 苏剑林 | 2016-03-06 | 53671位读者 | 引用
29
Mar
【备忘】电脑远程控制手机的解决方案
By 苏剑林 | 2016-03-29 | 45567位读者 | 引用最近由于数据挖掘上的研究,需要想办法通过电脑远程控制手机(主要是安卓),遂查找了网络上的一些工具,这里记录一下结果,纯粹做备忘。有同样需要的读者可以参考。
之前在阿里云的服务器和树莓派上都做过远程控制的,记得Linux下的远程控制工具叫做VNC,于是我google和百度了vnc server android、vnc server apk等,发现这类工具确实不少,比如最知名的当属droid vnc server。但是同类的几个软件我都测试了,它确实是VNC软件,但是在我的几个安卓4.x上,显示都不正常(花屏),无奈抛弃了。再看一下日期,发现原来这些软件基本到2013年就停止更新了,一般支持到安卓2.3而已,怪不得。

最近评论