






25
May
从重参数的角度看离散概率分布的构建
By 苏剑林 | 2022-05-25 | 15115位读者 | 引用一般来说,神经网络的输出都是无约束的,也就是值域为$\mathbb{R}$,而为了得到有约束的输出,通常是采用加激活函数的方式。例如,如果我们想要输出一个概率分布来代表每个类别的概率,那么通常在最后加上Softmax作为激活函数。那么一个紧接着的疑问就是:除了Softmax,还有什么别的操作能生成一个概率分布吗?
在《漫谈重参数:从正态分布到Gumbel Softmax》中,我们介绍了Softmax的重参数操作,本文将这个过程反过来,即先定义重参数操作,然后去反推对应的概率分布,从而得到一个理解概率分布构建的新视角。
问题定义
假设模型的输出向量为$\boldsymbol{\mu}=[\mu_1,\cdots,\mu_n]\in\mathbb{R}^n$,不失一般性,这里假设$\mu_i$两两不等。我们希望通过某个变换$\mathcal{T}$将$\boldsymbol{\mu}$转换为$n$元概率分布$\boldsymbol{p}=[p_1,\cdots,p_n]$,并保持一定的性质。比如,最基本的要求是:
\begin{equation}{\color{red}1.}\,p_i\geq 0 \qquad {\color{red}2.}\,\sum_i p_i = 1 \qquad {\color{red}3.}\,p_i \geq p_j \Leftrightarrow \mu_i \geq \mu_j\end{equation}
6
Mar
【中文分词系列】 7. 深度学习分词?只需一个词典!
By 苏剑林 | 2017-03-06 | 112604位读者 | 引用这个系列慢慢写到第7篇,基本上也把分词的各种模型理清楚了,除了一些细微的调整(比如最后的分类器换成CRF)外,剩下的就看怎么玩了。基本上来说,要速度,就用基于词典的分词,要较好地解决组合歧义何和新词识别,则用复杂模型,比如之前介绍的LSTM、FCN都可以。但问题是,用深度学习训练分词器,需要标注语料,这费时费力,仅有的公开的几个标注语料,又不可能赶得上时效,比如,几乎没有哪几个公开的分词系统能够正确切分出“扫描二维码,关注微信号”来。
本文就是做了这样的一个实验,仅用一个词典,就完成了一个深度学习分词器的训练,居然效果还不错!这种方案可以称得上是半监督的,甚至是无监督的。
17
May
正项级数敛散性最有力的判别法?
By 苏剑林 | 2013-05-17 | 91706位读者 | 引用在学习正项级数的时候,我们的数学分析教材提供了各种判别法,比如积分判别法、比较判别法,并由此衍生出了根植法、比值法等,在最后提供了一个比较精细的“Raabe判别法”。这些方法的精度(强度)各不相同,一般认为“Raabe判别法”的应用范围最广的。但是在我看来,基于p级数的比较判别法已经可以用于所有题目了,它才是最强的方法。
p级数就是我们熟悉的
$$\sum_{n=1}^{\infty} \frac{1}{n^p}$$
通过积分判别法可以得到当p>1时该级数收敛,反之发散。虽然我不能证明,但是我觉得以下结论是成立的:
若正项级数$\sum_{n=1}^{\infty} a_n$收敛,则总可以找到一个常数A以及一个大于1的常数p,使每项都有$a_n < \frac{A}{n^p}$。
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 123357位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
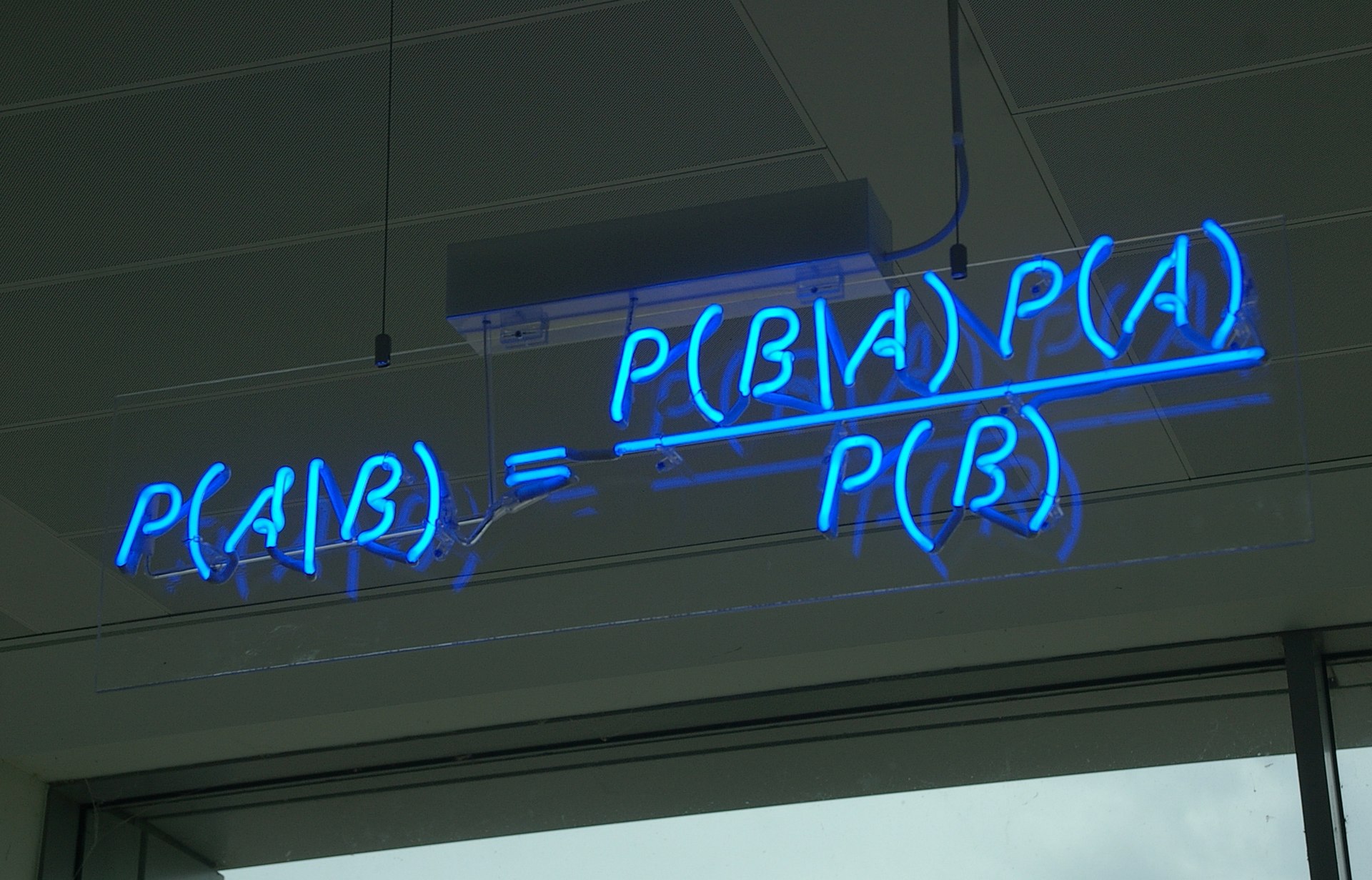
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
27
Jul
生成扩散模型漫谈(四):DDIM = 高观点DDPM
By 苏剑林 | 2022-07-27 | 179367位读者 | 引用相信很多读者都听说过甚至读过克莱因的《高观点下的初等数学》这套书,顾名思义,这是在学到了更深入、更完备的数学知识后,从更高的视角重新审视过往学过的初等数学,以得到更全面的认知,甚至达到温故而知新的效果。类似的书籍还有很多,比如《重温微积分》、《复分析:可视化方法》等。
回到扩散模型,目前我们已经通过三篇文章从不同视角去解读了DDPM,那么它是否也存在一个更高的理解视角,让我们能从中得到新的收获呢?当然有,《Denoising Diffusion Implicit Models》介绍的DDIM模型就是经典的案例,本文一起来欣赏它。
思路分析
在《生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪》中,我们提到过该文章所介绍的推导跟DDIM紧密相关。具体来说,文章的推导路线可以简单归纳如下:
\begin{equation}p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})\xrightarrow{\text{推导}}p(\boldsymbol{x}_t|\boldsymbol{x}_0)\xrightarrow{\text{推导}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0)\xrightarrow{\text{近似}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)\end{equation}
12
Aug
生成扩散模型漫谈(七):最优扩散方差估计(上)
By 苏剑林 | 2022-08-12 | 68366位读者 | 引用对于生成扩散模型来说,一个很关键的问题是生成过程的方差应该怎么选择,因为不同的方差会明显影响生成效果。
在《生成扩散模型漫谈(二):DDPM = 自回归式VAE》我们提到,DDPM分别假设数据服从两种特殊分布推出了两个可用的结果;《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中的DDIM则调整了生成过程,将方差变为超参数,甚至允许零方差生成,但方差为0的DDIM的生成效果普遍差于方差非0的DDPM;而《生成扩散模型漫谈(五):一般框架之SDE篇》显示前、反向SDE的方差应该是一致的,但这原则上在$\Delta t\to 0$时才成立;《Improved Denoising Diffusion Probabilistic Models》则提出将它视为可训练参数来学习,但会增加训练难度。
所以,生成过程的方差究竟该怎么设置呢?今年的两篇论文《Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models》和《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》算是给这个问题提供了比较完美的答案。接下来我们一起欣赏一下它们的结果。
3
Aug
生成扩散模型漫谈(五):一般框架之SDE篇
By 苏剑林 | 2022-08-03 | 163285位读者 | 引用在写生成扩散模型的第一篇文章时,就有读者在评论区推荐了宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》,可以说该论文构建了一个相当一般化的生成扩散模型理论框架,将DDPM、SDE、ODE等诸多结果联系了起来。诚然,这是一篇好论文,但并不是一篇适合初学者的论文,里边直接用到了随机微分方程(SDE)、Fokker-Planck方程、得分匹配等大量结果,上手难度还是颇大的。
不过,在经过了前四篇文章的积累后,现在我们可以尝试去学习一下这篇论文了。在接下来的文章中,笔者将尝试从尽可能少的理论基础出发,尽量复现原论文中的推导结果。
随机微分
在DDPM中,扩散过程被划分为了固定的$T$步,还是用《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》的类比来说,就是“拆楼”和“建楼”都被事先划分为了$T$步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。
18
Aug
生成扩散模型漫谈(八):最优扩散方差估计(下)
By 苏剑林 | 2022-08-18 | 39113位读者 | 引用在上一篇文章《生成扩散模型漫谈(七):最优扩散方差估计(上)》中,我们介绍并推导了Analytic-DPM中的扩散模型最优方差估计结果,它是直接给出了已经训练好的生成扩散模型的最优方差的一个解析估计,实验显示该估计结果确实能有效提高扩散模型的生成质量。
这篇文章我们继续介绍Analytic-DPM的升级版,出自同一作者团队的论文《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》,在官方Github中被称为“Extended-Analytic-DPM”,下面我们也用这个称呼。
结果回顾
上一篇文章是在DDIM的基础上,推出DDIM的生成过程最优方差应该是
\begin{equation}\sigma_t^2 + \gamma_t^2\bar{\sigma}_t^2\end{equation}
其中$\bar{\sigma}_t^2$是分布$p(\boldsymbol{x}_0|\boldsymbol{x}_t)$的方差,它有如下的估计结果(这里取“方差估计2”的结果):
\begin{equation}\bar{\sigma}_t^2 = \frac{\bar{\beta}_t^2}{\bar{\alpha}_t^2}\left(1 - \frac{1}{d}\mathbb{E}_{\boldsymbol{x}_t\sim p(\boldsymbol{x}_t)}\left[ \Vert\boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t)\Vert^2\right]\right)\label{eq:basic}\end{equation}

最近评论