






15
Mar
WGAN的成功,可能跟Wasserstein距离没啥关系
By 苏剑林 | 2021-03-15 | 55045位读者 | 引用WGAN,即Wasserstein GAN,算是GAN史上一个比较重要的理论突破结果,它将GAN中两个概率分布的度量从f散度改为了Wasserstein距离,从而使得WGAN的训练过程更加稳定,而且生成质量通常也更好。Wasserstein距离跟最优传输相关,属于Integral Probability Metric(IPM)的一种,这类概率度量通常有着更优良的理论性质,因此WGAN的出现也吸引了很多人从最优传输和IPMs的角度来理解和研究GAN模型。
然而,最近Arxiv上的论文《Wasserstein GANs Work Because They Fail (to Approximate the Wasserstein Distance)》则指出,尽管WGAN是从Wasserstein GAN推导出来的,但是现在成功的WGAN并没有很好地近似Wasserstein距离,相反如果我们对Wasserstein距离做更好的近似,效果反而会变差。事实上,笔者一直以来也有这个疑惑,即Wasserstein距离本身并没有体现出它能提升GAN效果的必然性,该论文的结论则肯定了该疑惑,所以GAN能成功的原因依然很迷~
22
Apr
Transformer升级之路:3、从Performer到线性Attention
By 苏剑林 | 2021-04-22 | 57012位读者 | 引用看过笔者之前的文章《线性Attention的探索:Attention必须有个Softmax吗?》和《Performer:用随机投影将Attention的复杂度线性化》的读者,可能会觉得本文的标题有点不自然,因为是先有线性Attention然后才有Performer的,它们的关系为“Performer是线性Attention的一种实现,在保证线性复杂度的同时保持了对标准Attention的近似”,所以正常来说是“从线性Attention到Performer”才对。
然而,本文并不是打算梳理线性Attention的发展史,而是打算反过来思考Performer给线性Attention所带来的启示,所以是“从Performer到线性Attention”。
激活函数
线性Attention的常见形式是
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})_i = \frac{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)} = \frac{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)}\end{equation}
27
Sep
关于维度公式“n > 8.33 log N”的可用性分析
By 苏剑林 | 2021-09-27 | 40651位读者 | 引用在之前的文章《最小熵原理(六):词向量的维度应该怎么选择?》中,我们基于最小熵思想推导出了一个词向量维度公式“$n > 8.33\log N$”,然后在《让人惊叹的Johnson-Lindenstrauss引理:应用篇》中我们进一步指出,该结果与JL引理所给出的$\mathcal{O}(\log N)$是吻合的。
既然理论上看上去很完美,那么自然就有读者发问了:实验结果如何呢?8.33这个系数是最优的吗?本文就对此问题的相关内容做一个简单汇总。
词向量
首先,我们可以直接,当$N$为10万时,$8.33\log N\approx 96$,当$N$为500万时,$8.33\log N\approx 128$。这说明,至少在数量级上,该公式给出的结果是很符合我们实际所用维度的,因为在词向量时代,我们自行训练的词向量维度也就是100维左右。可能有读者会质疑,目前开源的词向量多数是300维的,像BERT的Embedding层都达到了768维,这不是明显偏离了你的结果了?
24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 61701位读者 | 引用大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:
29
Jun
UniVAE:基于Transformer的单模型、多尺度的VAE模型
By 苏剑林 | 2021-06-29 | 74141位读者 | 引用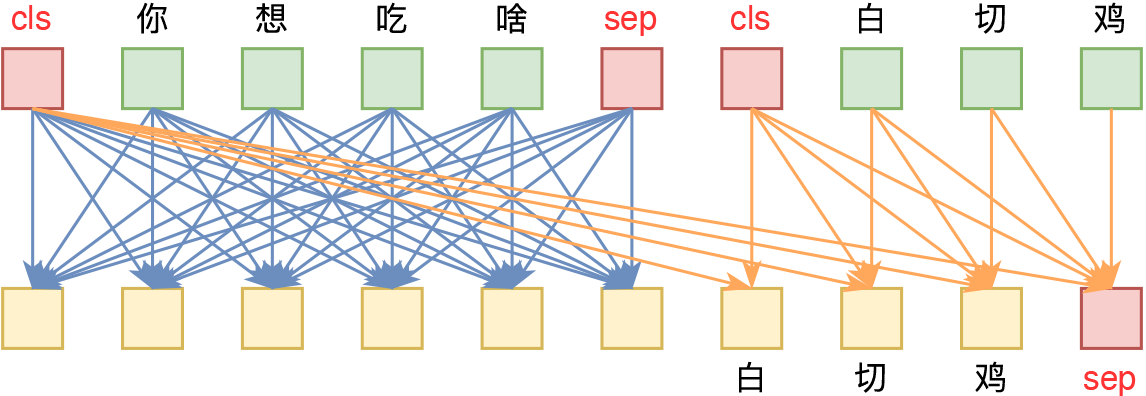
22
Jul
概率视角下的线性模型:逻辑回归有解析解吗?
By 苏剑林 | 2021-07-22 | 78719位读者 | 引用我们知道,线性回归是比较简单的问题,它存在解析解,而它的变体逻辑回归(Logistic Regression)却没有解析解,这不能不说是一个遗憾。因为逻辑回归虽然也叫“回归”,但它实际上是用于分类问题的,而对于很多读者来说分类比回归更加常见。准确来说,我们说逻辑回归没有解析解,说的是“最大似然估计下逻辑回归没有解析解”。那么,这是否意味着,如果我们不用最大似然估计,是否能找到一个可用的解析解呢?
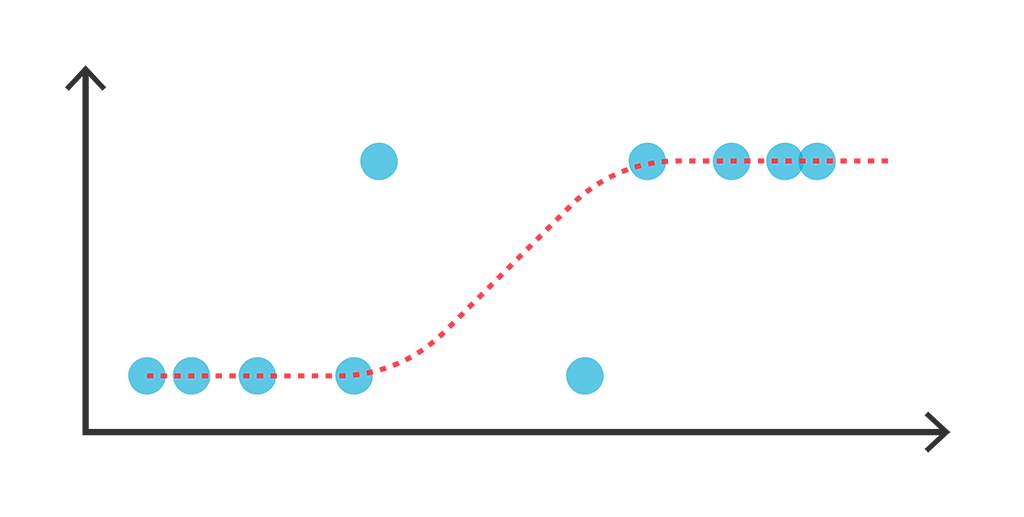
逻辑回归示意图
本文将会从非最大似然的角度,推导逻辑回归的一个解析解,简单的实验表明它效果不逊色于梯度下降求出来的最大似然解。此外,这个解析解还易于推广到单层Softmax多分类模型。
22
Oct
CAN:借助先验分布提升分类性能的简单后处理技巧
By 苏剑林 | 2021-10-22 | 149499位读者 | 引用顾名思义,本文将会介绍一种用于分类问题的后处理技巧——CAN(Classification with Alternating Normalization),出自论文《When in Doubt: Improving Classification Performance with Alternating Normalization》。经过笔者的实测,CAN确实多数情况下能提升多分类问题的效果,而且几乎没有增加预测成本,因为它仅仅是对预测结果的简单重新归一化操作。
有趣的是,其实CAN的思想是非常朴素的,朴素到每个人在生活中都应该用过同样的思想。然而,CAN的论文却没有很好地说清楚这个思想,只是纯粹形式化地介绍和实验这个方法。本文的分享中,将会尽量将算法思想介绍清楚。
思想例子
假设有一个二分类问题,模型对于输入$a$给出的预测结果是$p^{(a)} = [0.05, 0.95]$,那么我们就可以给出预测类别为$1$;接下来,对于输入$b$,模型给出的预测结果是$p^{(b)}=[0.5,0.5]$,这时候处于最不确定的状态,我们也不知道输出哪个类别好。
21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 117571位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在$Q,K$转置相乘之后还要除以一个$\sqrt{d}$再做Softmax(下面均不失一般性地假设$Q,K,V\in\mathbb{R}^{n\times d}$):
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{QK^{\top}}{\sqrt{d}}\right)V\label{eq:std}\end{equation}
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以$\sqrt{d}$的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
\begin{equation}\boldsymbol{o}_i = \sum_{j=1}^n a_{i,j}\boldsymbol{v}_j,\quad a_{i,j}=\frac{e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_{j=1}^n e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}
其中$\lambda$是缩放因子,它跟$\boldsymbol{q}_i,\boldsymbol{k}_j$无关,但原则上可以跟长度$n$、维度$d$等参数有关,目前主流的就是$\lambda=1/\sqrt{d}$。

最近评论