






21
Oct
把Python脚本放到手机上定时运行
By 苏剑林 | 2015-10-21 | 42581位读者 | 引用毫无疑问,数据是数据分析的基础,而对于我等平民来说,获取大量数据的方式自然是通过爬虫采集,而对于笔者来说,写爬虫最自然的方式就是用Python写了。短短几行代码,就可以完成一个实用的爬虫,多清爽。(请参考:《记录一次爬取淘宝/天猫评论数据的过程》)
爬虫要住在哪里?
接下来的一个问题是,这个爬虫放到哪里运行?为了爬取每天更新的数据,往往需要每天都要运行一次爬虫,特别地,是在某个点定时运行。这样的话,老挂在自己的电脑运行是不大现实,因为自己的电脑总有关机的时候。也许有读者会想到放在云服务器里边,这是个方法,但是需要额外的成本。受到小虾大神的启发,我开始想把它放到路由器里边运行,某些比较好的路由器是可以外接U盘,且可以刷open-wrt系统的(一个Linux内核的路由器系统,可以像普通Linux那样装Python)。这对我来说是一种很吸引人的做法,但是我对Linux环境下的编译并不熟悉,尤其是路由器环境下的操作;另外路由器配置很低,一般都只是16M闪存、64M内存,如果没有耐心,那么是很难受得了的。
6
Dec
人生苦短,我用Python!
By 苏剑林 | 2015-12-06 | 57486位读者 | 引用
20
Jan
简单的迅雷VIP账号获取器(Python)
By 苏剑林 | 2016-01-20 | 32503位读者 | 引用在Windows工作的时候,经常会用迅雷下载东西,如果速度慢或者没资源,尤其是一些比较冷门的视频,迅雷的VIP会员服务总能够帮上大忙。后来无意间发现了有个“迅雷VIP账号获取器”的软件,可以获取一些临时的VIP账号供使用,这可是个好东西,因为开通迅雷会员虽然不贵,但是我又不经常下载,所以老感觉有点浪费,而有了这个之后,我随时下点东西都可以免费用了。
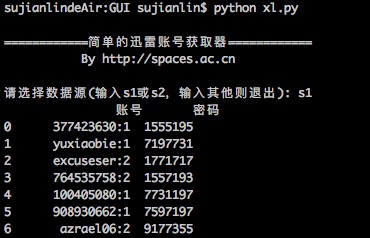
简单的迅雷VIP账号获取器
最近转移到了Mac上,而Mac也有迅雷,但那个账号获取器是exe的,不能在Mac运行。本以为获取器的构造会很复杂,谁知道,经过抓包研究,发现那个账号获取器的原理极其简单,说白了,就是一个简单的爬虫,以下这两个网站提供账号,它就到相应的抓取账号而已:
http://yunbo.xinjipin.com/
http://www.fenxs.com
据此,我也用Python简单写了一个,主要是方便我在Mac使用。读者如果有需要,也可以下载使用,代码兼容2.x和3.x的版本。主要的库是requests和re,pandas和sys的使用只不过是为了更加人性化。本来想用Tkinter写一个简单的GUI的,但是想想看,还是没必要了~~
19
Feb
Python的多进程编程技巧
By 苏剑林 | 2017-02-19 | 38631位读者 | 引用过程
在Python中,如果要多进程运算,一般是通过multiprocessing来实现的,常用的是multiprocessing中的进程池,比如:
from multiprocessing import Pool
import time
def f(x):
time.sleep(1)
print x+1
return x+1
a = range(10)
pool = Pool(4)
b = pool.map(f, a)
pool.close()
pool.join()
print b
这样写简明清晰,确实方便,有趣的是,只需要将multiprocessing换成multiprocessing.dummy,就可以将程序从多进程改为多线程了。
7
Jun
python简单实现gillespie模拟
By 苏剑林 | 2018-06-07 | 72127位读者 | 引用
8
Sep
有限内存下全局打乱几百G文件(Python)
By 苏剑林 | 2021-09-08 | 72231位读者 | 引用这篇文章我们来做一道编程题:
如何在有限内存下全局随机打乱(Shuffle)几百G的文本文件?
题目背景其实很明朗,现在预训练模型动辄就几十甚至几百G语料了,为了让模型能更好地进行预训练,对训练语料进行一次全局的随机打乱是很有必要的。但对于很多人来说,几百G的语料往往比内存还要大,所以如何能在有限内存下做到全局的随机打乱,便是一个很值得研究的问题了。
已有工具
假设我们的文件是按行存储的,也就是一行代表一个样本,我们要做的就是按行随机打乱文件。假设我们只有一个文件,并且这个文件大小明显小于内存,那么我们可以用linux自带的shuf命令:
shuf input.txt -o output.txt
14
Jan
旁门左道之如何让Python的重试代码更加优雅
By 苏剑林 | 2024-01-14 | 39588位读者 | 引用这篇文章我们讨论一个编程题:如何更优雅地在Python中实现重试。
在文章《新年快乐!记录一下 Cool Papers 的开发体验》中,笔者分享了开发Cool Papers的一些经验,其中就提到了Cool Papers所需要的一些网络通信步骤。但凡涉及到网络通信,就有失败的风险(谁也无法保证网络不会间歇性抽风),所以重试是网络通信的基本操作。此外,当涉及到多进程、数据库、硬件交互等操作时,通常也需要引入重试机制。
在Python中,实现重试并不难,但如何更加简单而又不失可读性地实现重试,还是有一定技巧的。接下来笔者分享一下自己的尝试。
循环重试
完整的重试流程大致上包含循环重试、异常处理、延时等待、后续操作等部分,其标准写法就是用for循环,用“try ... except ...”来捕捉异常,一个参考代码是:
7
Sep
BytePiece:更纯粹、更高压缩率的Tokenizer
By 苏剑林 | 2023-09-07 | 55096位读者 | 引用目前在LLM中最流行的Tokenizer(分词器)应该是Google的SentencePiece了,因为它符合Tokenizer的一些理想特性,比如语言无关、数据驱动等,并且由于它是C++写的,所以Tokenize(分词)的速度很快,非常适合追求效率的场景。然而,它也有一些明显的缺点,比如训练速度慢(BPE算法)、占用内存大等,同时也正因为它是C++写的,对于多数用户来说它就是黑箱,也不方便研究和二次开发。
事实上,Tokenizer的训练就相当于以往的“新词发现”,而笔者之前也写过中文分词和最小熵系列文章,对新词发现也有一定的积累,所以很早之前就有自己写一版Tokenizer的想法。这几天总算腾出了时间初步完成了这件事情,东施效颦SentencePiece,命名为“BytePiece”。

最近评论