






8
Oct
《哈勃太空望远镜超高清原始片源》VeryCD资源
By 苏剑林 | 2009-10-08 | 35234位读者 | 引用
17
Oct
关于e是无理数的证明
By 苏剑林 | 2009-10-17 | 41986位读者 | 引用
17
Oct
【NASA每日一图】星系M33的亮星云
By 苏剑林 | 2009-10-17 | 29014位读者 | 引用
1
Nov
本站域名Spaces.Ac.Cn的PR为2了
By 苏剑林 | 2009-11-01 | 26091位读者 | 引用
7
Nov
爱恩斯坦的狭义相对论论文(中文/图片)
By 苏剑林 | 2009-11-07 | 32537位读者 | 引用说明:这篇文章是通过翻拍而来,请读者勿用于商业用途。如果原著作者(或者译者)认为此举侵犯了您的权利,请留言或者来信BoJone@Spaces.Ac.Cn告知,本人会尽快删除!
\begin{aligned}E=mc^2 \\ \sqrt{1-{v^2}/{c^2}}\end{aligned}
本文不是通用的相对论教程,适合已经有一定物理学基础的读者阅读。
相对论是关于时空和引力的基本理论,主要由阿尔伯特·爱因斯坦(Albert Einstein)创立,分为狭义相对论(特殊相对论)和广义相对论(一般相对论)。相对论的基本假设是相对性原理,即物理定律与参照系的选择无关。狭义相对论和广义相对论的区别是,前者讨论的是匀速直线运动的参照系(惯性参照系)之间的物理定律,后者则推广到具有加速度的参照系中(非惯性系),并在等效原理的假设下,广泛应用于引力场中。
11
Nov
【宇宙驿站】拼音输入法天文学词库
By 苏剑林 | 2009-11-11 | 19910位读者 | 引用
14
Nov
科学空间相册上线,与你分享科学图片
By 苏剑林 | 2009-11-14 | 17308位读者 | 引用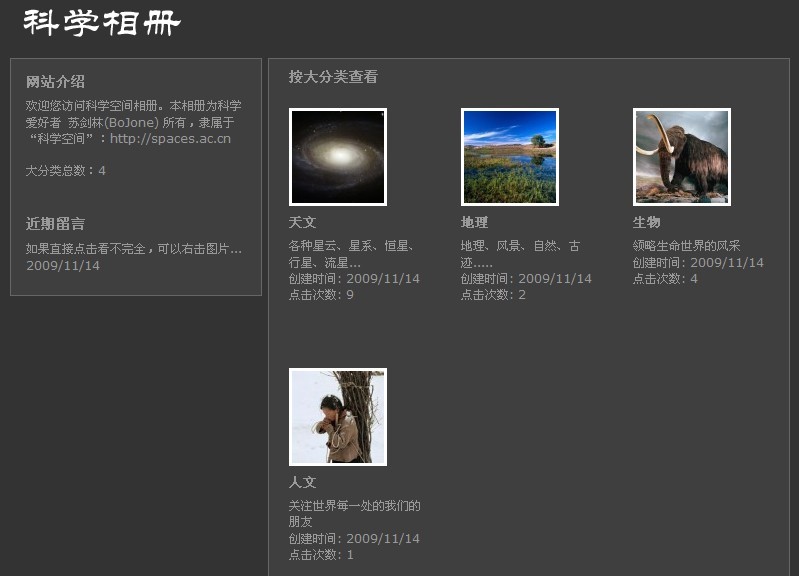
22
Nov

最近评论