






9
Aug
线性Transformer应该不是你要等的那个模型
By 苏剑林 | 2021-08-09 | 166018位读者 |在本博客中,我们已经多次讨论过线性Attention的相关内容。介绍线性Attention的逻辑大体上都是:标准Attention具有$\mathcal{O}(n^2)$的平方复杂度,是其主要的“硬伤”之一,于是我们$\mathcal{O}(n)$复杂度的改进模型,也就是线性Attention。有些读者看到线性Attention的介绍后,就一直很期待我们发布基于线性Attention的预训练模型,以缓解他们被BERT的算力消耗所折腾的“死去活来”之苦。
然而,本文要说的是:抱有这种念头的读者可能要失望了,标准Attention到线性Attention的转换应该远远达不到你的预期,而BERT那么慢的原因也并不是因为标准Attention的平方复杂度。
BERT之反思 #
按照直观理解,平方复杂度换成线性复杂度不应该要“突飞猛进”才对嘛?怎么反而“远远达不到预期”?出现这个疑惑的主要原因,是我们一直以来都没有仔细评估一下常规的Transformer模型(如BERT)的整体计算量。
很多读者都已经知道,Transformer的结构大体上是Embedding层加若干个Transformer层,Embedding层的计算量很少,我们主要关心Transformer层。忽略残差、Layer Normalization等计算量比较小的层不计,每个Transformer层主要组成就是两个子层:Self Attention(简称SA)和FeedForward Network(简称FFN)。虽然Transformer的开山之作声称“Attention is all you need”,但是也有不少工作论证了残差、FFN等模块的必要性了,比如《Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth》。
现在问大家一个问题:
你觉得是SA计算量大还是FFN计算量大?
评估计算量 #
毋庸置疑,SA的复杂度是$\mathcal{O}(n^2)$,而FFN的复杂度则是$\mathcal{O}(n)$,如果你直接凭此就想当然地说SA计算量比FFN大,那就错了!
我们知道加法比乘法快很多,所以在估计计算量的时候我们主要计算要做多少次乘法,神经网络里边,主要的运算是矩阵相乘,不难估计按照定义一个$a\times b$的矩阵乘以一个$b\times c$的矩阵要做$abc$次乘法,所以$abc$就是两个矩阵相乘的复杂度了,这是我们估算Transformer复杂度的依据。
设$n$为序列长度,$d$为head_size(base版是64),$h$为head的数目(base版是12),那么$hd$就是我们通常说的“hidden_size”(base版是768)。对于SA来说,一开始是$Q,K,V$的投影变换,即$n\times hd$的矩阵乘以$hd\times hd$的矩阵做3次,因此计算量是$3n(hd)^2$;然后是$h$个Attention头的运算,每个头先是$n\times d$的$Q$与$d\times n$的$K^{\top}$相乘得到$n\times n$的Attention矩阵(softmax和归一化的计算量暂且忽略),然后$n\times n$的矩阵与$n\times d$的$V$相乘得到$n\times d$的矩阵,这两步的计算量都是$n^2 d$,所以总计算量是$h(n^2 d + n^2 d)$;最后的输出还有一个投影变换,也是$n\times hd$的矩阵乘以$hd\times hd$的矩阵,计算量是$n(hd)^2$。所以,SA的总计算量是
\begin{equation}3n(hd)^2 + h(n^2 d + n^2 d) + n(hd)^2 = 4nh^2 d^2 + 2n^2 hd\end{equation}
至于FFN就比较简单了,它就是两个全连接层,也就是两个矩阵变换(激活函数的计算量也忽略不计),一般的参数设置是:第一层是$n\times hd$的矩阵乘以$hd\times 4hd$的矩阵,第二层就是$n\times 4hd$的矩阵乘以$4hd\times hd$的矩阵。所以总计算量是
\begin{equation}n\times hd\times 4hd + n\times 4hd\times hd = 8nh^2 d^2\end{equation}
这样一来,如果SA的计算量比FFN大,就意味着
\begin{equation}4nh^2 d^2 + 2n^2 hd > 8nh^2 d^2\quad\Leftrightarrow\quad n > 2hd\end{equation}
对于base版来说,这意味着$n > 1536$!也就是说,只有当序列长度超过1536时,SA的计算量才大于FFN,在这之前,都是线性复杂度的FFN占主导!
这还不止,由上面的结果我们可以得到Transformer层总的计算量为
\begin{equation}4nh^2 d^2 + 2n^2 hd + 8nh^2 d^2 = 12nh^2 d^2 + 2n^2 hd\end{equation}
它是关于$n$的一次项和二次项的求和,当$n$足够大时,复杂度自然是$\mathcal{O}(n^2)$,然而二次项占主导的条件是
\begin{equation}2n^2 hd > 12nh^2 d^2\quad\Leftrightarrow\quad n > 6hd\end{equation}
对于base版来说,这意味着$n > 4608$!也就是说,当序列长度接近5000时,Transformer的复杂度才真正体现出二次性!
综合的结论 #
综合上述结果,我们可以得到结论:对于base版来说,当序列长度不超过1536时,Transformer的复杂度都是近乎线性的;当序列长度超过1536时,Transformer的计算量逐渐以Attention为主,复杂度慢慢趋于二次方,直到长度超过4608,才真正以二次项为主。当然这个边界只是一个估计,实际情况可能有所偏差,大家就此感知一下范围和数量级就好。
笔者以前也建议过很多读者,对于不超过2000长度的“长文本”任务,直接用NEZHA或者RoFormer这种不限长度的模型试试,不要想太多的技巧,原因也是如此。你想再多技巧,也顶多是降到线性复杂度,而在这个长度范围内模型本身就是近乎线性的,各种技巧也省不了多少。
对于老老实实用BERT base的读者来说,maxlen一般不超过512,远低于上述界限,因此就不要再说Attention的平方复杂度费硬件之类的吐槽了,因为事实是:
BERT之所以慢,主要是因为它真的大,而不是因为Attention的平方复杂度。
“线性”含义 #
至于对线性Attention“远远达不到预期”而感到疑惑的另一个原因,则是没有从实际情况分析线性Attention的计算量,以至于对线性Attention期待过高。
线性Attention的介绍可以参考《线性Attention的探索:Attention必须有个Softmax吗?》,这里不做重复。简单来说,线性Attention就是按照$Q(K^{\top} V)$的顺序算注意力。所以按照前面的估算方法,线性Attention每个头运算的计算量就是$2nd^2$,而标准Attention则是$2n^2 d$,因此如果$n > d$,那么线性Attention是比标准Attention要省计算量的。(注:实现线性效率的Attention也不止这一种思路,但总的而言复杂度是相似的,因此下面的结论也有代表性。)
对于base版来说,那就是$n > 64$,这个界还是很容易达到的,所以有些读者可能会想“能省一点是一点”、“不用白不用”。然而,这是假设了标准Attention与线性Attention都用同一个$d$的前提下得出的结果。而认真琢磨过《Performer:用随机投影将Attention的复杂度线性化》、《Transformer升级之路:3、从Performer到线性Attention》的读者都知道,线性Attention有着比标准Attention更严重的“低秩瓶颈”,所以如果切换为线性Attention后还用同一个$d$,那么线性Attention的效果将会明显下降,而如果要保留大致相同的效果,那么线性Attention要用更大的$d$(一般是原来的4倍左右)。
这样一来,线性Attention的计算量应该是$2n(4d)^2$,如果线性Attention要比标准Attention快,那么就要$n > 16d$,对于base版来说,就是$n > 1024$,这也超出了一般读者所能用到的范围了。况且换成线性Attention后,前面关于SA和FFN的计算量结论依然存在,即大部分序列长度下占主导计算量的还是FFN等线性运算,换了线性Attention后也无法感觉到明显的速度提升。所以,总的来说
你要不是成千上万的序列长度,就不要想着换线性Attention了。
再翻翻论文 #
事实上,就算不进行上述分析,只要认真读过关于Attention效率改进相关工作的读者,从论文中的某些图片就可以得到类似的结论:所谓更“高效”的Attention,一般都只适用于成千上万的序列长度,只有在这个场景下性能才有明显提升。
比如较早的工作Sparse Transformers,里边有一张图显示出处理的序列长度都是3000+的:
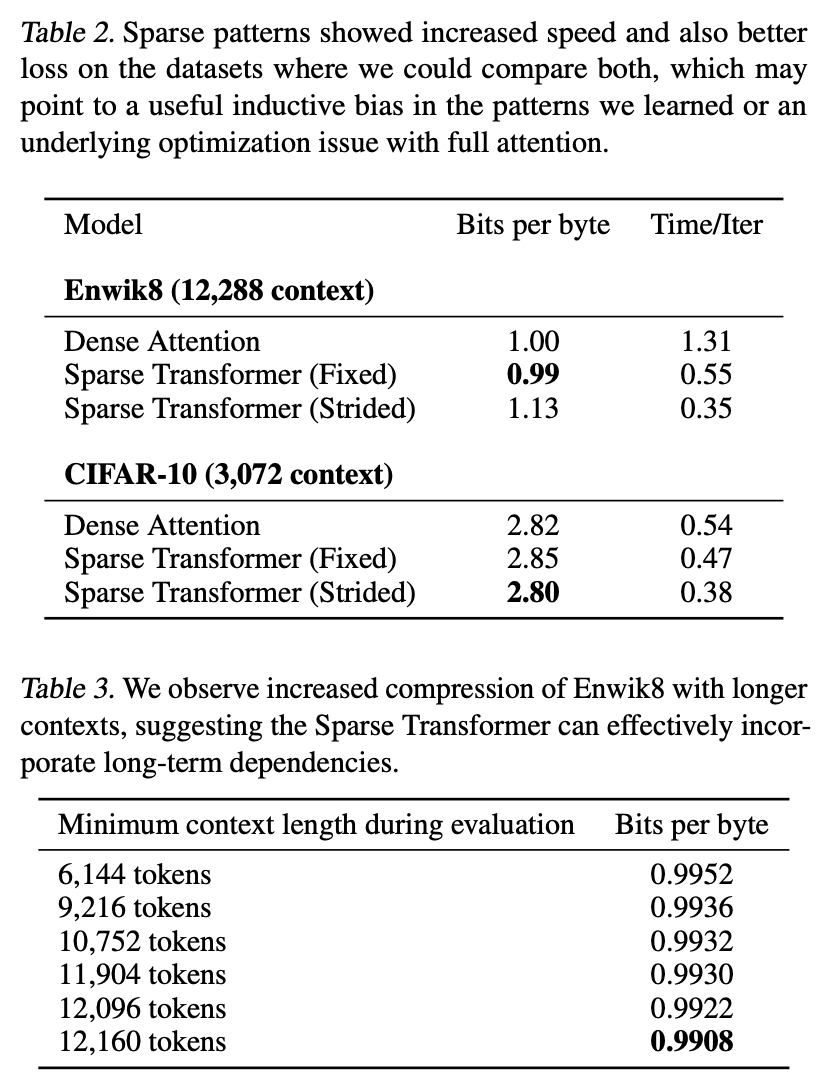
Sparse Transformer处理的长度都是3000+
比如大名鼎鼎的Reformer,演示性能的序列长度都是以K为单位的:

Reformer演示性能的序列长度都是以K为单位的
大家颇多好评的Longformer也是如此:
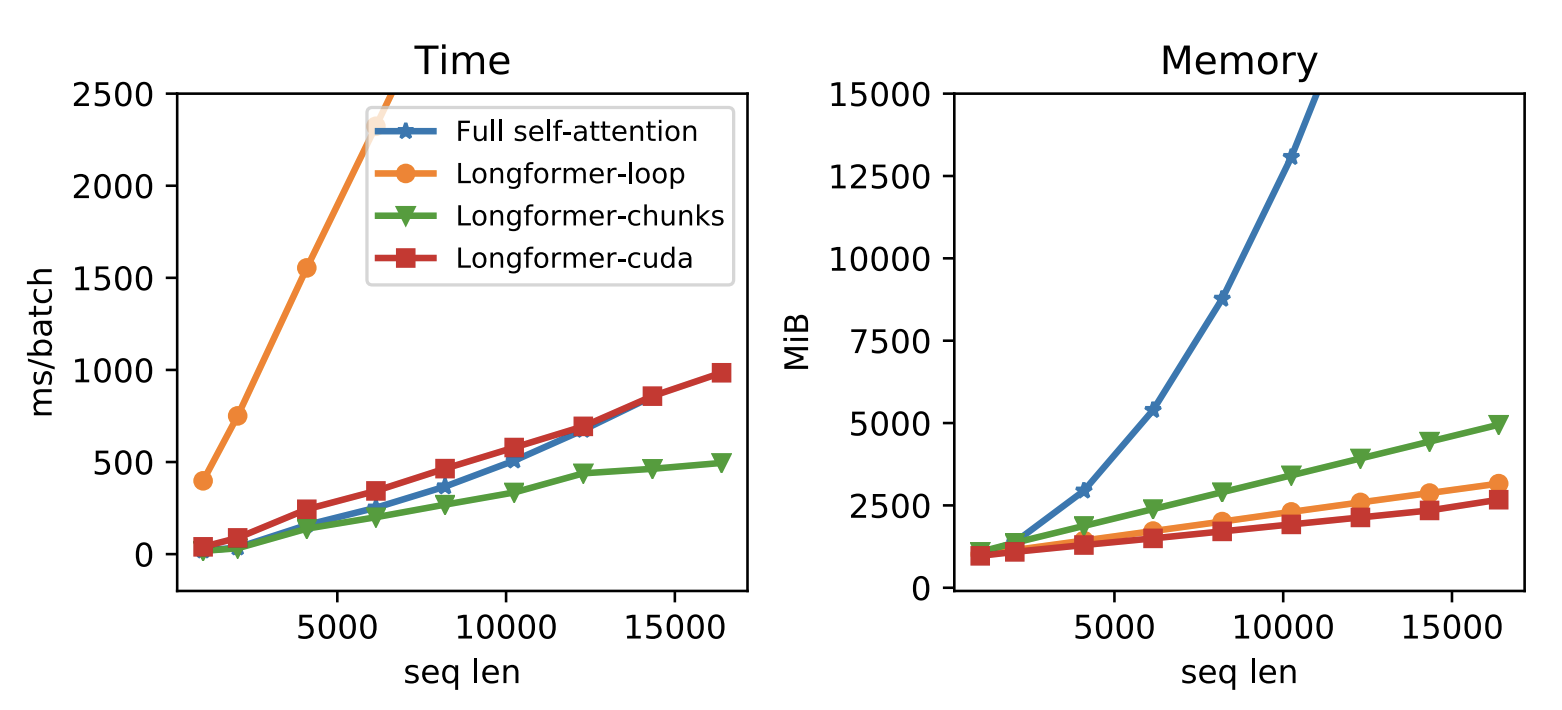
Longformer演示性能的序列长度都是几千甚至上万
还有Google关于线性Attention的经典之作Performer,显示出哪怕序列长度是$2^{12}=4096$,Performer与Transformer的差距也不能说特别显著:

Performer的性能曲线
最后是比较新的工作Luna,提供了一个比较综合的对比表格,同样支持我们的结论:
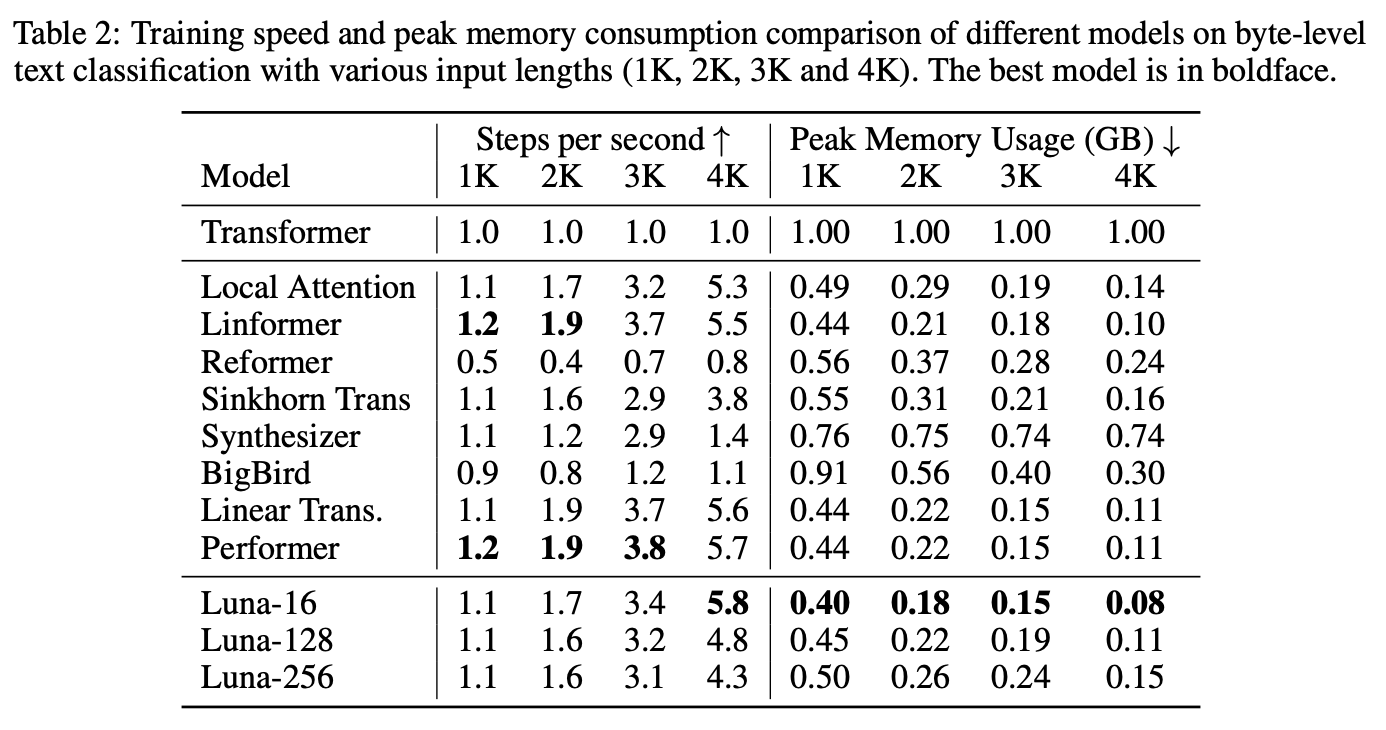
Luna里边关于各个改进版Attention机制的性能对比
从已有的各个高效Attention的工作中,我们可以得出结论:这些改进工作所关心的序列长度主要都是以千为单位的,有明显计算效率提升的序列长度基本上都要好几千;当然,我们前面的讨论主要针对的还是时间复杂度,对于空间复杂度,也就是显存占用量,降低的幅度一般要比时间复杂度提升的幅度的要大,但总体而言都是长序列才有价值。
换个期待吧 #
所以,如果你的序列长度还只是一两百,那么就完全不要期望Attention本身的改进了,老老实实换个小点的模型就好。你可以期望未来会有更小的模型能达到同样好的效果,但是不要期望同样大的模型通过修改Attention来提升效率,因为说白了,就算把Attention完全去掉,也提升不了多少性能。
转载到请包括本文地址:https://spaces.ac.cn/archives/8610
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Aug. 09, 2021). 《线性Transformer应该不是你要等的那个模型 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8610
@online{kexuefm-8610,
title={线性Transformer应该不是你要等的那个模型},
author={苏剑林},
year={2021},
month={Aug},
url={\url{https://spaces.ac.cn/archives/8610}},
}

July 7th, 2023
https://arxiv.org/abs/2307.02486 LongNet: Scaling Transformers to 1,000,000,000 Tokens
微软新出炉的作品, 把序列长度扩充到了10亿.
October 22nd, 2023
请教大神,我目前的需求是处理生物数据,也是一个embedding序列,类似于nlp,序列长度差不多在1500左右正太分布,90%的序列长度小于3072,现在是用talking head attention + rope进行处理,不过在A100 80G上,超过1500左右的序列长度时batch size就变成2或者1了。
您的这篇文章主要进行的是运算时间的分析,但是我想的是,如果换作linear transformer可以省点gpu vram,让我的batch size可以变大一点吗?
或者说,从空间上分析,linear transformer有好一些吗
短时间内,可能去掉talking head,换回标准attention,然后上flash attention收益最高~
感谢。。。
个人认为生物领域需要先提点而不是加速,涉及到DNA序列、癌症相关,准确才是人们需要的东西,当然不否定又快又好
December 19th, 2023
线性attention省得不是矩阵计算?是softmax mask?
是省矩阵计算量
December 26th, 2023
受益匪浅!苏神如何看待今年清华在linear attention方面的新工作《FLatten Transformer: Vision Transformer using Focused Linear Attention》呢?
CV的效果尚可,但NLP未知,而且不是做Causal的,没多大意思呀。
May 22nd, 2024
“投影变换,即n×hd的矩阵乘以hd×hd的矩阵做3次”后面那个应该是hd*d呀
忽略