






3
Mar
T5 PEGASUS:开源一个中文生成式预训练模型
By 苏剑林 | 2021-03-03 | 182102位读者 | 引用去年在文章《那个屠榜的T5模型,现在可以在中文上玩玩了》中我们介绍了Google的多国语言版T5模型(mT5),并给出了用mT5进行中文文本生成任务的例子。诚然,mT5做中文生成任务也是一个可用的方案,但缺乏完全由中文语料训练出来模型总感觉有点别扭,于是决心要搞一个出来。
经过反复斟酌测试,我们决定以mT5为基础架构和初始权重,先结合中文的特点完善Tokenizer,然后模仿PEGASUS来构建预训练任务,从而训练一版新的T5模型,这就是本文所开源的T5 PEGASUS。

T5 PEGASUS的训练数据示例
29
Jun
UniVAE:基于Transformer的单模型、多尺度的VAE模型
By 苏剑林 | 2021-06-29 | 70785位读者 | 引用
10
Sep
曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果
By 苏剑林 | 2021-09-10 | 53835位读者 | 引用在五花八门的预训练任务设计中,NSP通常认为是比较糟糕的一种,因为它难度较低,加入到预训练中并没有使下游任务微调时有明显受益,甚至RoBERTa的论文显示它会带来负面效果。所以,后续的预训练工作一般有两种选择:一是像RoBERTa一样干脆去掉NSP任务,二是像ALBERT一样想办法提高NSP的难度。也就是说,一直以来NSP都是比较“让人嫌弃”的。
不过,反转来了,NSP可能要“翻身”了。最近的一篇论文《NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task--Next Sentence Prediction》(下面简称NSP-BERT)显示NSP居然也可以做到非常不错的Zero Shot效果!这又是一个基于模版(Prompt)的Few/Zero Shot的经典案例,只不过这一次的主角是NSP。
背景回顾
曾经我们认为预训练纯粹就是预训练,它只是为下游任务的训练提供更好的初始化,像BERT的预训练任务有MLM(Masked Language Model和NSP(Next Sentence Prediction),在相当长的一段时间内,大家都不关心这两个预训练任务本身,而只是专注于如何通过微调来使得下游任务获得更好的性能。哪怕是T5将模型参数训练到了110亿,走的依然是“预训练+微调”这一路线。
17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 64478位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
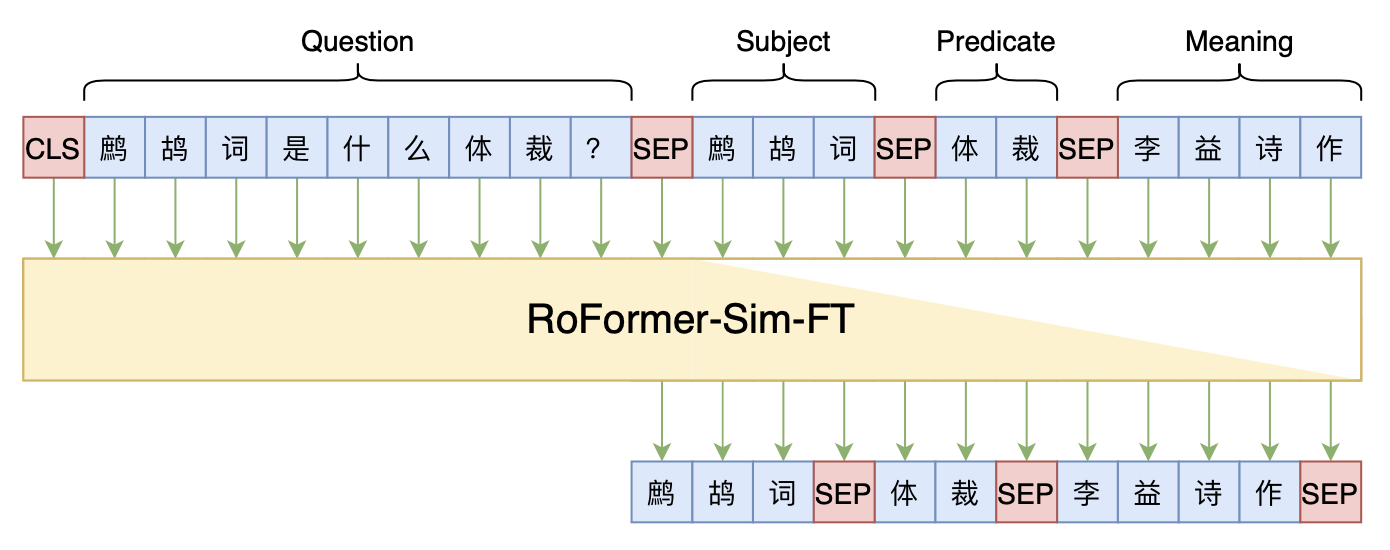
本文baseline模型示意图
25
Dec
写了个刷论文的辅助网站:Cool Papers
By 苏剑林 | 2023-12-25 | 87185位读者 | 引用写在开头
一直以来,笔者都有日刷Arxiv的习惯,以求尽可能跟上领域内最新成果,并告诫自己“不进则退”。之前也有不少读者问我是怎么刷Arxiv的、有什么辅助工具等,但事实上,在很长的时间里,笔者都是直接刷Arxiv官网,并且没有用任何算法过滤,都是自己一篇篇过的。这个过程很枯燥,但并非不能接受,之所以不用算法初筛,主要还是担心算法漏召,毕竟“刷”就是为了追新,一旦算法漏召就“错失先机”了。
自从Kimi Chat发布后,笔者就一直计划着写一个辅助网站结合Kimi来加速刷论文的过程。最近几个星期稍微闲了一点,于是在GPT4、Kimi的帮助下,初步写成了这个网站,并且经过几天的测试和优化后,已经逐步趋于稳定,于是正式邀请读者试用。
Cool Papers:https://papers.cool
2
Feb
更便捷的Cool Papers打开方式:Chrome重定向扩展
By 苏剑林 | 2024-02-02 | 42721位读者 | 引用一些铺垫
自Cool Papers上线以来,很多用户就建议笔者加入搜索功能,后面也确实在前端用JS简单做了个页面内搜索,解决了部分用户的需求,但仍有读者希望引入更完整的全局搜索。诚然,笔者理解这个需求确实是存在,但Cool Papers的数据是逐天累积的,目前才上线一个月,论文数并不多,建立一个大而全的搜索引擎意义不大,其次做搜索也不是笔者的强项,以及并没有很好的利用LLM优化搜索的思路,等等。总而言之,暂时没有条件实现一个全面而又有特色的搜索,所以不如不做(也欢迎大家在评论区集思广益)。
后来,经过和同事讨论,想出了一个“借花献佛”的思路——写一个Chrome的重定向扩展,可以从任意页面重定向到Cool Papers。这样我们可以用任意方式(如Google搜索或者直接Arxiv官方搜索)找到Arxiv上的论文,然后右击一下就转到Cool Papers了。前两周这个扩展已经在Chrome应用商店上线,上周服务器配合做了一些调整,如今大家可以尝试使用了。
14
Jul


最近评论