






22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 214968位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
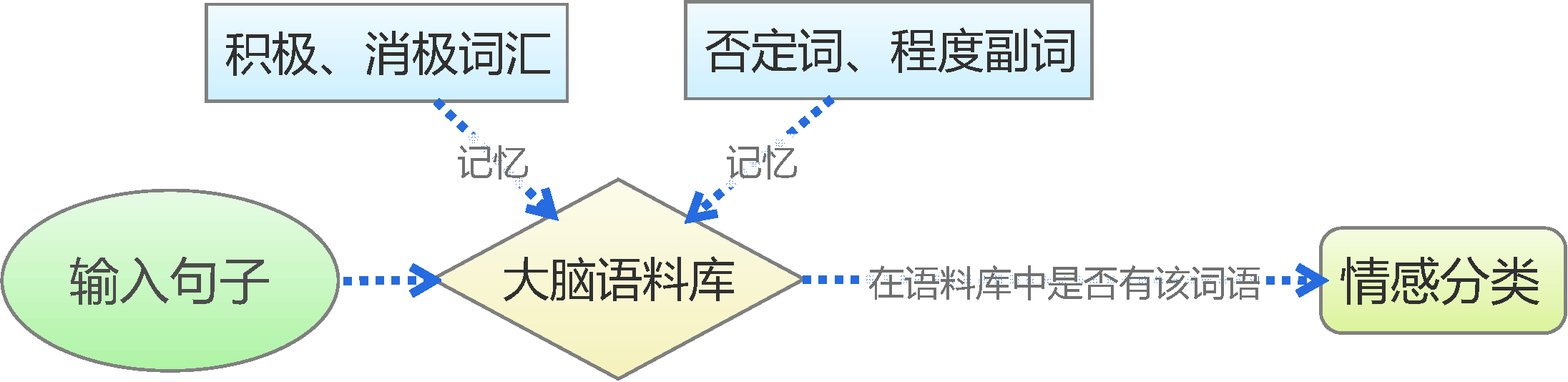
人的最简单的判断思维
4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 586057位读者 | 引用
5
Oct
2015诺贝尔医学奖:中国人在内
By 苏剑林 | 2015-10-05 | 22944位读者 | 引用
21
Oct
把Python脚本放到手机上定时运行
By 苏剑林 | 2015-10-21 | 40550位读者 | 引用毫无疑问,数据是数据分析的基础,而对于我等平民来说,获取大量数据的方式自然是通过爬虫采集,而对于笔者来说,写爬虫最自然的方式就是用Python写了。短短几行代码,就可以完成一个实用的爬虫,多清爽。(请参考:《记录一次爬取淘宝/天猫评论数据的过程》)
爬虫要住在哪里?
接下来的一个问题是,这个爬虫放到哪里运行?为了爬取每天更新的数据,往往需要每天都要运行一次爬虫,特别地,是在某个点定时运行。这样的话,老挂在自己的电脑运行是不大现实,因为自己的电脑总有关机的时候。也许有读者会想到放在云服务器里边,这是个方法,但是需要额外的成本。受到小虾大神的启发,我开始想把它放到路由器里边运行,某些比较好的路由器是可以外接U盘,且可以刷open-wrt系统的(一个Linux内核的路由器系统,可以像普通Linux那样装Python)。这对我来说是一种很吸引人的做法,但是我对Linux环境下的编译并不熟悉,尤其是路由器环境下的操作;另外路由器配置很低,一般都只是16M闪存、64M内存,如果没有耐心,那么是很难受得了的。
28
Oct
朋友们,来瓶汽水吧!有趣的换汽水问题
By 苏剑林 | 2015-10-28 | 31560位读者 | 引用————怀念我曾经参加过的小学数学竞赛。
从一道小学竞赛题谈起
笔者小学五年级时参加了第一次数学竞赛,叫“育苗杯”,大多数题目都记不清楚了,唯一记得很清楚的是如下这道题目(不完全相同,意思类似):
假设汽水一块钱一瓶,而且4个空瓶子可以换一瓶汽水喝。如果我有30块钱,我最多可以喝到多少瓶汽水?

来瓶汽水吧
当然,这道题并不困难,30块钱能买30瓶汽水,然后留下30个空瓶子,这30个空瓶子可以换来7瓶汽水,剩下2个空瓶子;喝完汽水后,剩下9个空瓶子,可以换来2瓶汽水,剩下1个空瓶子;喝完汽水后,剩下3个空瓶子。算算看,这时候我们已经喝了30+7+2=39瓶汽水了。(不考虑撑着啊,也可以分给别人喝^_^)整个过程如下表:
$$\begin{array}{c|cccc}
\hline
\text{空瓶子数} & 30 & 2+7 & 1+2 & ? \\
\hline
\text{已喝汽水数} & 30 & 7 & 2 & ? \\
\hline \end{array}$$
7
Mar
通过ssh动态端口转发共享校园资源(附带干货)
By 苏剑林 | 2016-03-07 | 34474位读者 | 引用众所周知,校园网最宝贵的资源应该有两样:一是IPv6,IPv6是访问Google等网站的最理想途径,当然IPv6并非所有高校都有;二是论文库,一般高校都会买了一部分论文库(知网、万方等)的下载权,供校园用户使用。如果说访问Google还有VPN等诸多方式的话,那么对于校外用户来说访问知网等资源就显得格外宝贵了,一般只是叫校内用户下载,或者就只能付费了(那个贵呀!)。
站长还是学生,在学校同时享用着IPv6和论文库资源,确实很爽。自从用上Openwrt的路由之后,一直想着怎么把校园网资源共享出去。曾经考虑过搭建PPTP VPN,但是感觉略有复杂(当然,跟其他VPN相比,搭建PPTP VPN算是非常简单的了,可是我还是不怎么喜欢。),而且当时还没解决内网穿透的问题。最近借助ssh反向代理的方式实现了内网穿透,继而认识到,通过ssh动态端口转发,居然还可以搭建代理,并且实现远程访问内网(校园网)资源,而且几乎不用在路由器本身上面做任何配置。不得不说,ssh真是一个极其强大的东西呀。
添加普通帐号
既然要共享,就没理由把root账户都分享出去了,因此,第一步要实现的是在Openwrt上添加一个代理账号,而且为了安全和保密,这个账号不允许真的登陆服务器进行操作,而只允许进行端口转发。
20
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(三)
By 苏剑林 | 2015-12-20 | 64348位读者 | 引用上集回顾
在上一篇文章中,笔者分享了自己对最大熵原理的认识,包括最大熵原理的意义、最大熵原理的求解以及一些简单而常见的最大熵原理的应用。在上一篇的文末,我们还通过最大熵原理得到了正态分布,以此来说明最大熵原理的深刻内涵和广泛意义。
本文中,笔者将介绍基于最大熵原理的模型——最大熵模型。本文以有监督的分类问题来介绍最大熵模型,所谓有监督,就是基于已经标签好的数据进行的。
事实上,第二篇文章的最大熵原理才是主要的,最大熵模型,实质上只是最大熵原理的一个延伸,或者说应用。
最大熵模型
分类:意味着什么?
在引入最大熵模型之前,我们先来多扯一点东西,谈谈分类问题意味着什么。假设我们有一批标签好的数据:
$$\begin{array}{c|cccccccc}
\hline
\text{数据}x & 1 & 2 & 3 & 4 & 5 & 6 & \dots & 100 \\
\hline
\text{标签}y & 1 & 0 & 1 & 0 & 1 & 0 & \dots & 0\\
\hline \end{array}$$

最近评论