






17
Aug
【中文分词系列】 1. 基于AC自动机的快速分词
By 苏剑林 | 2016-08-17 | 107192位读者 | 引用前言:这个暑假花了不少时间在中文分词和语言模型上面,碰了无数次壁,也得到了零星收获。打算写一个专题,分享一下心得体会。虽说是专题,但仅仅是一些笔记式的集合,并非系统的教程,请读者见谅。
中文分词
关于中文分词的介绍和重要性,我就不多说了,matrix67这里有一篇关于分词和分词算法很清晰的介绍,值得一读。在文本挖掘中,虽然已经有不少文章探索了不分词的处理方法,如本博客的《文本情感分类(三):分词 OR 不分词》,但在一般场合都会将分词作为文本挖掘的第一步,因此,一个有效的分词算法是很重要的。当然,中文分词作为第一步,已经被探索很久了,目前做的很多工作,都是总结性质的,最多是微弱的改进,并不会有很大的变化了。
目前中文分词主要有两种思路:查词典和字标注。首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。查词典的方法简单高效(得益于动态规划的思想),尤其是结合了语言模型的最大概率法,能够很好地解决歧义问题,但对于中文分词一大难度——未登录词(中文分词有两大难度:歧义和未登录词),则无法解决;为此,人们也提出了基于字标注的思路,所谓字标注,就是通过几个标记(比如4标注的是:single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾),把句子的正确分词法表示出来。这是一个序列(输入句子)到序列(标记序列)的过程,能够较好地解决未登录词的问题,但速度较慢,而且对于已经有了完备词典的场景下,字标注的分词效果可能也不如查词典方法。总之,各有优缺点(似乎是废话~),实际使用可能会结合两者,像结巴分词,用的是有向无环图的最大概率组合,而对于连续的单字,则使用字标注的HMM模型来识别。
1
Jul
从Boosting学习到神经网络:看山是山?
By 苏剑林 | 2016-07-01 | 71583位读者 | 引用前段时间在潮州给韩师的同学讲文本挖掘之余,涉猎到了Boosting学习算法,并且做了一番头脑风暴,最后把Boosting学习算法的一些本质特征思考清楚了,而且得到一些意外的结果,比如说AdaBoost算法的一些理论证明也可以用来解释神经网络模型这么强大。
AdaBoost算法
Boosting学习,属于组合模型的范畴,当然,与其说它是一个算法,倒不如说是一种解决问题的思路。以有监督的分类问题为例,它说的是可以把弱的分类器(只要准确率严格大于随机分类器)通过某种方式组合起来,就可以得到一个很优秀的分类器(理论上准确率可以100%)。AdaBoost算法是Boosting算法的一个例子,由Schapire在1996年提出,它构造了一种Boosting学习的明确的方案,并且从理论上给出了关于错误率的证明。
以二分类问题为例子,假设我们有一批样本{xi,yi},i=1,2,…,n,其中xi是样本数据,有可能是多维度的输入,yi∈{1,−1}为样本标签,这里用1和-1来描述样本标签而不是之前惯用的1和0,只是为了后面证明上的方便,没有什么特殊的含义。接着假设我们已经有了一个弱分类器G(x),比如逻辑回归、SVM、决策树等,对分类器的唯一要求是它的准确率要严格大于随机(在二分类问题中就是要严格大于0.5),所谓严格大于,就是存在一个大于0的常数ϵ,每次的准确率都不低于12+ϵ。
18
Aug
【中文分词系列】 2. 基于切分的新词发现
By 苏剑林 | 2016-08-18 | 131497位读者 | 引用上一篇文章讲的是基于词典和AC自动机的快速分词。基于词典的分词有一个明显的优点,就是便于维护,容易适应领域。如果迁移到新的领域,那么只需要添加对应的领域新词,就可以实现较好地分词。当然,好的、适应领域的词典是否容易获得,这还得具体情况具体分析。本文要讨论的就是新词发现这一部分的内容。
这部分内容在去年的文章《新词发现的信息熵方法与实现》已经讨论过了,算法是来源于matrix67的文章《互联网时代的社会语言学:基于SNS的文本数据挖掘》。在那篇文章中,主要利用了三个指标——频数、凝固度(取对数之后就是我们所说的互信息熵)、自由度(边界熵)——来判断一个片段是否成词。如果真的动手去实现过这个算法的话,那么会发现有一系列的难度。首先,为了得到n字词,就需要找出1∼n字的切片,然后分别做计算,这对于n比较大时,是件痛苦的时间;其次,最最痛苦的事情是边界熵的计算,边界熵要对每一个片段就行分组统计,然后再计算,这个工作量的很大的。本文提供了一种方案,可以使得新词发现的计算量大大降低。
19
Aug
【中文分词系列】 3. 字标注法与HMM模型
By 苏剑林 | 2016-08-19 | 91082位读者 | 引用在这篇文章中,我们暂停查词典方法的介绍,转而介绍字标注的方法。前面已经提到过,字标注是通过给句子中每个字打上标签的思路来进行分词,比如之前提到过的,通过4标签来进行标注(single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾。均只取第一个字母。),这样,“为人民服务”就可以标注为“sbebe”了。4标注不是唯一的标注方式,类似地还有6标注,理论上来说,标注越多会越精细,理论上来说效果也越好,但标注太多也可能存在样本不足的问题,一般常用的就是4标注和6标注。
值得一提的是,这种通过给每个字打标签、进而将问题转化为序列到序列的学习,不仅仅是一种分词方法,还是一种解决大量自然语言问题的思路,比如命名实体识别等任务,同样可以用标注的方法来做。回到分词来,通过字标注法来进行分词的模型有隐马尔科夫模型(HMM)、最大熵模型(ME)、条件随机场模型(CRF),它们在精度上都是递增的,据说目前公开评测中分词效果最好的是4标注的CRF。然而,在本文中,我们要讲解的是最不精确的HMM。因为在我看来,它并非一个特定的模型,而是解决一大类问题的通用思想,一种简化问题的学问。
这一切,还得从概率模型谈起。
6
Sep
基于双向LSTM和迁移学习的seq2seq核心实体识别
By 苏剑林 | 2016-09-06 | 173903位读者 | 引用暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下。模型的效果不是最好的,但是胜在“端到端”,迁移性强,估计对大家会有一定的参考价值。
比赛的主题是“核心实体识别”,其实有两个任务:核心识别 + 实体识别。这两个任务虽然有关联,但在传统自然语言处理程序中,一般是将它们分开处理的,而这次需要将两个任务联合在一起。如果只看“核心识别”,那就是传统的关键词抽取任务了,不同的是,传统的纯粹基于统计的思路(如TF-IDF抽取)是行不通的,因为单句中的核心实体可能就只出现一次,这时候统计估计是不可靠的,最好能够从语义的角度来理解。我一开始就是从“核心识别”入手,使用的方法类似QA系统:
1、将句子分词,然后用Word2Vec训练词向量;
2、用卷积神经网络(在这种抽取式问题上,CNN效果往往比RNN要好)卷积一下,得到一个与词向量维度一样的输出;
3、损失函数就是输出向量跟训练样本的核心词向量的cos值。
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 89134位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量Aμ时,严格来讲应该还要注明是在\boldsymbol{x}位置测量的:A^{\mu}(\boldsymbol{x}),只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如A^{\mu}是在\boldsymbol{x}处测量的,而\boldsymbol{x}处的模长计算公式为ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu},因此,A^{\mu}的模长为\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}},它是一个客观实体。
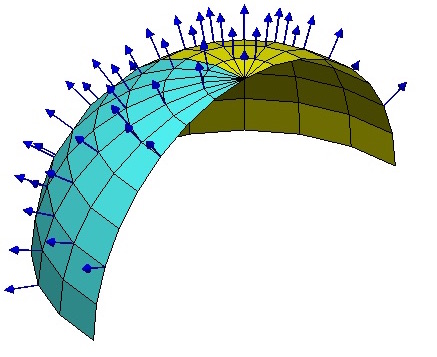
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。
12
Sep
【中文分词系列】 5. 基于语言模型的无监督分词
By 苏剑林 | 2016-09-12 | 161399位读者 | 引用迄今为止,前四篇文章已经介绍了分词的若干思路,其中有基于最大概率的查词典方法、基于HMM或LSTM的字标注方法等。这些都是已有的研究方法了,笔者所做的就只是总结工作而已。查词典方法和字标注各有各的好处,我一直在想,能不能给出一种只需要大规模语料来训练的无监督分词模型呢?也就是说,怎么切分,应该是由语料来决定的,跟语言本身没关系。说白了,只要足够多语料,就可以告诉我们怎么分词。
看上去很完美,可是怎么做到呢?《2.基于切分的新词发现》中提供了一种思路,但是不够彻底。那里居于切分的新词发现方法确实可以看成一种无监督分词思路,它就是用一个简单的凝固度来判断某处该不该切分。但从分词的角度来看,这样的分词系统未免太过粗糙了。因此,我一直想着怎么提高这个精度,前期得到了一些有意义的结果,但都没有得到一个完整的理论。而最近正好把这个思路补全了。因为没有查找到类似的工作,所以这算是笔者在分词方面的一点原创工作了。
语言模型
首先简单谈一下语言模型。
18
Oct
【理解黎曼几何】5. 黎曼曲率
By 苏剑林 | 2016-10-18 | 58418位读者 | 引用现在我们来关注黎曼曲率。总的来说,黎曼曲率提供了一种方案,让身处空间内部的人也能计算自身所处空间的弯曲程度。俗话说,“不识庐山真面目,只缘身在此山中”,还有“当局者迷,旁观者清”,等等,因此,能够身处空间之中而发现空间中的弯曲与否,是一件很了不起的事情,就好像我们已经超越了我们现有的空间,到了更高维的空间去“居高临下”那样。真可谓“心有多远,路就有多远,世界就有多远”。
如果站在更高维空间的角度看,就容易发现空间的弯曲。比如弯曲空间中有一条测地线,从更高维的空间看,它就是一条曲线,可以计算曲率等,但是在原来的空间看,它就是直的,测地线就是直线概念的一般化,因此不可能通过这种途径发现空间的弯曲性,必须有一些迂回的途径。可能一下子不容易想到,但是各种途径都殊途同归后,就感觉它是显然的了。
怎么更好地导出黎曼曲率来,使得它能够明显地反映出弯曲空间跟平直空间的本质区别呢?为此笔者思考了很长时间,看了不少参考书(《引力与时空》、《场论》、《引力论》等),比较了几种导出黎曼曲率的方式,简要叙述如下。

最近评论