






28
Nov
《自然极值》系列——4.费马点问题
By 苏剑林 | 2010-11-28 | 89924位读者 | 引用通过上面众多的文字描述,也许你还不大了解这两个原理有何美妙之处,也或者你已经迫不及待地想去应用它们却不知思路。为了不至于让大家产生“审美疲劳”,接下来我们将试图利用这两个原理对费马点问题进行探讨,看看原理究竟是怎么发挥作用的。运用的关键在于:如何通过适当的变换将其与光学或势能联系起来。
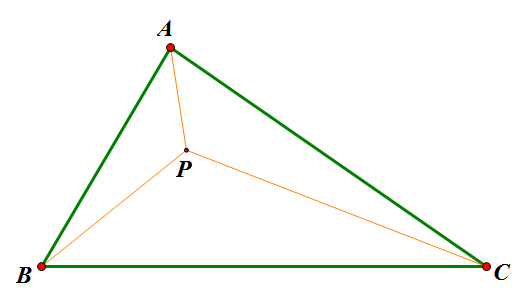
费马点问题
传统费马点问题是指在ΔABC中寻找点P,使得$AP+BP+CP$最小的问题;而广义的费马点则改成使$k_1 AP+k_2 BP+k_3 CP$最小。这是很具有现实意义的,是“在三个村庄之间建立一个中转站,如何才能使运送成为最低”之类的最优问题。我们将从光学和势能两个角度对这个问题进行探讨(也许有的读者已经阅读过了利用重力的原理来求解费马点,但是我想光学的方法依然会是你眼前一亮的。)
10
Dec
《自然极值》系列——6.最速降线的解答
By 苏剑林 | 2010-12-10 | 64543位读者 | 引用通过上一小节的小故事,我们已经能够基本了解最速降线的内容了,它就是要我们求出满足某一极值条件的一个未知函数,由于函数是未知的,因此这类问题被称为“泛分析”。其中还谈到,伯努利利用费马原理巧妙地得出了答案,那么我们现在就再次回顾历史,追寻伯努利的答案,并且寻找进一步的应用。
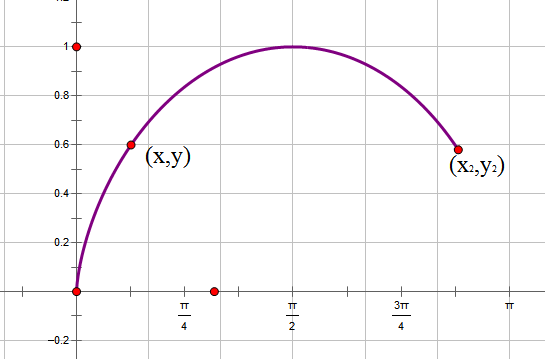
最速降线-1
为了计算方便,我们把最速降线倒过来,把初始点设置在原点。在下落过程中,重力势能转化为动能,因此,在点(x,y)处有$\frac{1}{2} mv^2=mgy\Rightarrow v=\sqrt{2gy}$,由于纯粹为了探讨曲线形状,所以我们使g=0.5,即$v=\sqrt{y}$。在点(x,y)处所走的路程为$ds=\sqrt{dy^2+dx^2}=\sqrt{\dot{y}^2+1}dx$,所以时间为$dt=\frac{ds}{v}=\frac{\sqrt{\dot{y}^2+1}dx}{\sqrt{y}}$,于是最速降线问题就是求使$t=\int_0^{x_2} \frac{\sqrt{\dot{y}^2+1}dx}{\sqrt{y}}$最小的函数。
3
Mar
指数梯度下降 + 元学习 = 自适应学习率
By 苏剑林 | 2022-03-03 | 31700位读者 | 引用前两天刷到了Google的一篇论文《Step-size Adaptation Using Exponentiated Gradient Updates》,在其中学到了一些新的概念,所以在此记录分享一下。主要的内容有两个,一是非负优化的指数梯度下降,二是基于元学习思想的学习率调整算法,两者都颇有意思,有兴趣的读者也可以了解一下。
指数梯度下降
梯度下降大家可能听说得多了,指的是对于无约束函数$\mathcal{L}(\boldsymbol{\theta})$的最小化,我们用如下格式进行更新:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta\nabla_{\boldsymbol{\theta}}\mathcal{L}(\boldsymbol{\theta}_t)\end{equation}
其中$\eta$是学习率。然而很多任务并非总是无约束的,对于最简单的非负约束,我们可以改为如下格式更新:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t \odot \exp\left(- \eta\nabla_{\boldsymbol{\theta}}\mathcal{L}(\boldsymbol{\theta}_t)\right)\label{eq:egd}\end{equation}
这里的$\odot$是逐位对应相乘(Hadamard积)。容易看到,只要初始化的$\boldsymbol{\theta}_0$是非负的,那么在整个更新过程中$\boldsymbol{\theta}_t$都会保持非负,这就是用于非负约束优化的“指数梯度下降”。
11
Apr
熵不变性Softmax的一个快速推导
By 苏剑林 | 2022-04-11 | 19691位读者 | 引用在文章《从熵不变性看Attention的Scale操作》中,我们推导了一版具有熵不变性质的注意力机制:
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{\kappa \log n}{d}QK^{\top}\right)V\label{eq:a}\end{equation}
可以观察到,它主要是往Softmax里边引入了长度相关的缩放因子$\log n$来实现的。原来的推导比较繁琐,并且做了较多的假设,不利于直观理解,本文为其补充一个相对简明快速的推导。
推导过程
我们可以抛开注意力机制的背景,直接设有$s_1,s_2,\cdots,s_n\in\mathbb{R}$,定义
$$p_i = \frac{e^{\lambda s_i}}{\sum\limits_{i=1}^n e^{\lambda s_i}}$$
14
Aug
Transformer升级之路:13、逆用Leaky ReRoPE
By 苏剑林 | 2023-08-14 | 21904位读者 | 引用上周在《Transformer升级之路:12、无限外推的ReRoPE?》中,笔者提出了ReRoPE和Leaky ReRoPE,诸多实验结果表明,它们能够在几乎不损失训练效果的情况下免微调地扩展LLM的Context长度,并且实现了“longer context, lower loss”的理想特性,此外跟NTK-aware Scaled RoPE不同的是,其中ReRoPE似乎还有表现出了无限的Context处理能力。
总之,ReRoPE看起来相当让人满意,但美中不足的是会增加推理成本,具体表现为第一步推理需要算两次Attention,以及后续每步推理需要重新计算位置编码。本文试图通过在训练中逆用Leaky ReRoPE的方法来解决这个问题。
回顾
让我们不厌其烦地重温一下:RoPE形式上是一种绝对位置编码,但实际达到的效果是相对位置编码,对应的相对位置矩阵是:
\begin{equation}\begin{pmatrix}0 & \\
1 & 0 & \\
2 & 1 & 0 &\\
3 & 2 & 1 & 0 & \\
\ddots & 3 & 2 & 1 & 0 & \\
\ddots & \ddots & 3 & 2 & 1 & 0 & \\
\ddots & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots \\
\small{L - 2} & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots \\
\small{L - 1} & \small{L - 2} & \ddots & \ddots & \ddots & 3 & 2 & 1 & 0 & \\
\end{pmatrix}\label{eq:rope}\end{equation}
29
Nov
我在Performer中发现了Transformer-VQ的踪迹
By 苏剑林 | 2023-11-29 | 47276位读者 | 引用前些天我们在《VQ一下Key,Transformer的复杂度就变成线性了》介绍了“Transformer-VQ”,这是通过将Key序列做VQ(Vector Quantize)变换来实现Attention复杂度线性化的方案。诚然,Transformer-VQ提供了标准Attention到线性Attentino的一个非常漂亮的过渡,给人一种“大道至简”的美感,但熟悉VQ的读者应该能感觉到,当编码表大小或者模型参数量进一步增加时,VQ很可能会成为效果提升的瓶颈,因为它通过STE(Straight-Through Estimator)估计的梯度大概率是次优的(FSQ的实验结果也算是提供了一些佐证)。此外,Transformer-VQ为了使训练效率也线性化所做的梯度截断,也可能成为将来的效果瓶颈之一。
为此,笔者花了一些时间思考可以替代掉VQ的线性化思路。从Transformer-VQ的$\exp\left(QC^{\top}\right)$形式中,笔者联想到了Performer,继而“顺藤摸瓜”地发现原来Performer可以视为Soft版的Transformer-VQ。进一步地,笔者尝试类比Performer的推导方法来重新导出Transformer-VQ,为其后的优化提供一些参考结果。
30
Jun
简单做了个Logo~
By 苏剑林 | 2014-06-30 | 26682位读者 | 引用
在生活上,我是一个比较传统的人,因此每到节日我都会尽量回家跟家人团聚。也许会让大家比较吃惊的是,今年的国庆是我第一个不在家的国庆。的确,从小学到高中,上学的地方离家都比较近,每周回去一次都是不成问题的。现在来到了广州,就不能太随心了。虽然跟很多同学相比,我离家还是比较近的,但是来回也要考虑车费、时间等等。国庆假期时间虽然很长,但是中秋已经回去一趟了,所以我决定国庆就不再回去了。
对我来说,中秋跟国庆相比,中秋的意义更大些。所以我选择了国庆不回家。对家人而言,看到自己平安就好,因此哪一天回去他们都会很高兴,当然,对于农村人来说,中秋的味道更浓,更希望团聚。

最近评论