






23
Mar
【通知转载】国家天文台信息技术类人才招聘
By 苏剑林 | 2010-03-23 | 18860位读者 | 引用文章来源:国家天文台
国家天文台LAMOST大科学工程面向全社会招聘信息技术类人才若干名,主要从事数据密集型天文学研究、数据库设计开发、天文应用软件服务开发、数据处理、数据挖掘、数值模拟、高性能计算、算法优化、网站网页设计维护、天文数据整理与管理、网络科普教育等工作。大天区面积多目标光纤光谱天文望远镜(LAMOST)是一项国家重大科学工程项目。该工程项目于2008年底竣工,2009年6月通过国家验收,正处于观测试运行阶段。LAMOST天文望远镜是我国已建成的最大、最先进的天文观测设备,是世界上光谱观测效率最高的望远镜,4米口径5度视场,每次可观测4000个目标,每晚可观测数万个目标,获得数十GB的数据,每年可获得数TB的科学数据。如何处理、分析、管理、发布、挖掘如此海量的数据,就是诚聘的上述人才所要面临的挑战。
1
May
我们打算飞到小行星上——但是,哪一颗好呢?
By 苏剑林 | 2010-05-01 | 37489位读者 | 引用
漫游在太空的小行星
站长:已经很久没有翻译过科普文章了。现在再来尝试一下,依旧是“Google+金山+搜索+理解”的模式,依旧是那么烂的水平,依旧是那么差的文采,呵呵。有任何意见欢迎提出。 4月15日,美国总统巴拉克·奥巴马视察了位于佛罗里达州的肯尼迪航天中心并发表演讲,提出美国航天新计划:美国未来航天的目的地是火星和小行星,终止布什政府提出的国家载人航天飞行项目。他强有力地回击了其政策的批评者,同时呼吁私营企业铺设飞往火星的创新之路,而不是以国家之力展示美国的优势。 众所周知,载人登小行星比载人登月难多了。除了苛刻的技术条件外,适合登录的小行星也不多,奥巴马的新方案真的可行吗?让我们拭目以待!
14
Jul
集训结束了——入选了IOAA
By 苏剑林 | 2010-07-14 | 33157位读者 | 引用
13
Nov
意犹未尽——继续光学曲线
By 苏剑林 | 2010-11-13 | 60284位读者 | 引用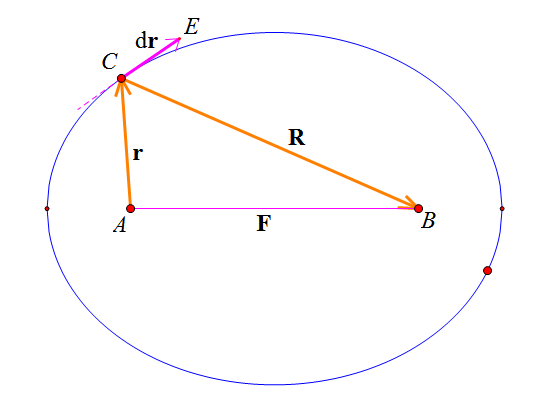
4
Dec
科学空间:2010年12月重要天象
By 苏剑林 | 2010-12-04 | 21698位读者 | 引用
月全食-2010-12-21
从2007年初到今天,笔者编写的天象预报已经陪伴了大家四年。如今又是一年即将过去,就让笔者以回顾今年的精彩天象的方式作为本期的幵篇。虽然缺少了在我国境内可观测的日全食,但今年天象的精彩程度毫不逊于前两年。1月15日的日环食再次掀起了一股天文热,我国环食带内大部分地区的观测也非常成功。希望12月的月全食发生时东北地区的天气可以一如既往地天随人愿。暑期的英仙座流星雨依旧表现抢眼,相信大家必然对年末的双子座流星雨充满了期待。此外,6月26日的月偏食和8月中旬的四星伴月或许也给您留下了深刻的印象。彗星方面,非周期彗星C2009 R1相当惊艳,不但亮度一度达4等左右,在许多爱好者拍摄的照片中两条彗尾也清晰可见。10月103P彗星经过近日点,也达到了肉眼可见的亮度,但彗尾很不明显。总之,2010年不乏颇具看点的精彩天象,作为天文爱好者的你一定是收获颇丰。接下来,我们就来看看2010年最后一个月即将发生的精彩天象吧。
28
May
科学空间:2011年6月重要天象
By 苏剑林 | 2011-05-28 | 29282位读者 | 引用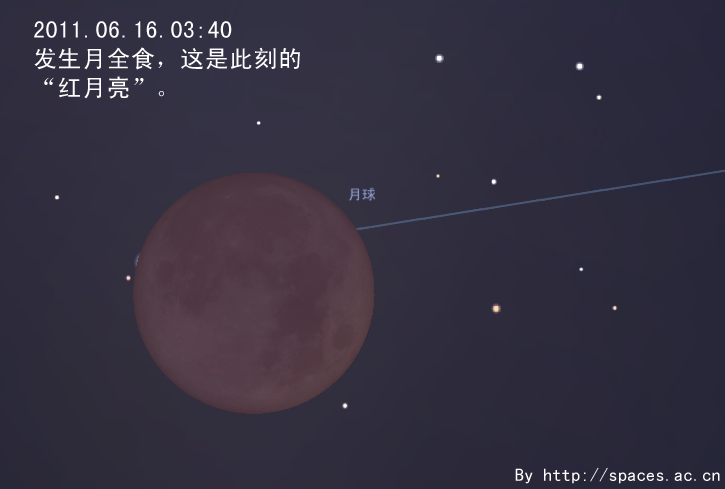
月全食-201106160340
6月中下旬,是北半球一年中黑夜最短的时期。今年6月22日是夏至节气,以北纬40°地区为例,当天天文昏影终到次日天文晨光始的间隔只有不到4小时50分钟。黑夜短暂会使我们可用于天文观测的时间缩短。但在夏至前后,午夜时分太阳也会在地平线下不太低的位置,这样我们就有可能整夜观测到一些类似国际空间站这样的低轨道人造天体。有兴趣的朋友可以查询相关的过境预报,挑战在一晚可以观测到多少次国际空间站过境这类的观测项目。发生在六月的日偏食和月全食,是今年天象的重头戏。接下来笔者就日偏食讲起,跟大家聊聊发生在6月的天象。
25
Jun
高中数学联赛题目和答案
By 苏剑林 | 2011-06-25 | 28396位读者 | 引用2011年的高中数学联赛拉开帷幕了...
前些天数学老师找了我们两个重点班的8个人,商量了参加今年数学联赛预赛的事情。大家都同意尝试,同时在我的强烈要求之下,增加了两位同学(一位是我的同桌,另外一位是我心目中的“天才生”)。只是老师也没有组织经验,而我上一年有过参赛经验(本来那是高三的玩意儿,我那时一个高二生瞎搅和进去,居然把高三的几个师兄师姐P下去了,意外呀...^_^),老师就把辅导其他九位同学的任务交给我(艰巨...)。
其实我也没有累积多少数学竞赛的知识,我最感兴趣的数学,几乎都不能在数学竞赛中用到。不过既然报名了,还是得准备准备,因此在网上找了最近几年的高中数学联赛试题和答案来看。顺便放到这里共享,供有需要的朋友下载。
10
Jul
明天就出发去夏令营了
By 苏剑林 | 2011-07-10 | 28526位读者 | 引用明天就要飞去北京参加北京大学天文夏令营了。
参加夏令营本来就是喜事,我满怀着喜悦。然而,喜悦之中却有点伤感。伤感的不是夏令营,而是一种别绪,一种难以看到想见的人的无奈。不管怎样,带着想念,好好参与这次的活动,希望能够收获更多的阅历和经验,同时也是一次对许多人梦寐以求的高校——北京大学的旅游和认识,也算是为明年的高考埋下美丽的伏笔
另一方面,暑假的到来意味着高二的结束,其实,当高考结束的那一天起,我们已经是“准高三”学生了。不少人讨论过高三怎么过,也有不少师兄师姐们向我们描述过高三的死板生活,而我的答案只有五个字:高三,好好活!

最近评论