






27
Feb
纠缠的时空(二):洛仑兹变换的矩阵(续)
By 苏剑林 | 2013-02-27 | 20722位读者 | 引用在上一篇文章中,我们以矩阵的方式推导出了洛仑兹变换。矩阵表述不仅仅具有形式上的美,还具有很重要的实用价值,比如可以很方便地寻找各种不变量。当洛仑兹变换用矩阵的方式表达出来后,很多线性代数中已知的理论都可以用在上边。在这篇小小的续集中,我们将尝试阐述这个思想。
本文中,继续设光速$c=1$。
我们已经得到了洛仑兹变换的矩阵形式:
\begin{equation}\left[\begin{array}{c} x\\t \end{array}\right]=\frac{1}{\sqrt{1-v^2}}\left[\begin{array}{c c}1 & v\\ v & 1 \end{array}\right]\left[\begin{array}{c}x'\\t' \end{array}\right]\end{equation}
1
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(一)
By 苏剑林 | 2015-12-01 | 84596位读者 | 引用熵的概念
作为一名物理爱好者,我一直对统计力学中“熵”这个概念感到神秘和好奇。因此,当我接触数据科学的时候,我也对最大熵模型产生了浓厚的兴趣。
熵是什么?在通俗的介绍中,熵一般有两种解释:(1)熵是不确定性的度量;(2)熵是信息的度量。看上去说的不是一回事,其实它们说的就是同一个意思。首先,熵是不确定性的度量,它衡量着我们对某个事物的“无知程度”。熵为什么又是信息的度量呢?既然熵代表了我们对事物的无知,那么当我们从“无知”到“完全认识”这个过程中,就会获得一定的信息量,我们开始越无知,那么到达“完全认识”时,获得的信息量就越大,因此,作为不确定性的度量的熵,也可以看作是信息的度量,说准确点,是我们能从中获得的最大的信息量。
15
Oct
【理解黎曼几何】3. 测地线
By 苏剑林 | 2016-10-15 | 57216位读者 | 引用测地线
黎曼度量应该是不难理解的,在微分几何的教材中,我们就已经学习过曲面的“第一基本形式”了,事实上两者是同样的东西,只不过看待问题的角度不同,微分几何是把曲面看成是三维空间中的二维子集,而黎曼几何则是从二维曲面本身内蕴地研究几何问题。
几何关心什么问题呢?事实上,几何关心的是与变换无关的“客观实体”(或者说是在变换之下不变的东西),这也是几何的定义。根据Klein提出的《埃尔朗根纲领》,几何就是研究在某种变换(群)下的不变性质的学科。如果把变换局限为刚性变换(平移、旋转、反射),那么就是欧式几何;如果变换为一般的线性变换,那就是仿射几何。而黎曼几何关心的是与一切坐标都无关的客观实体。比如说,我有一个向量,方向和大小都确定了,在直角坐标系是$(1, 1)$,在极坐标系是$(\sqrt{2}, \pi/4)$,虽然两个坐标系下的分量不同,但它们都是指代同一个向量。也就是说向量本身是客观存在的实体,跟所使用的坐标无关。从代数层面看,就是只要能够通过某种坐标变换相互得到的,我们就认为它们是同一个东西。
因此,在学习黎曼几何时,往“客观实体”方向思考,总是有益的。

平面上的测地线
有了度规,可以很自然地引入“测地线”这一实体。狭义来看,它就是两点间的最短线——是平直空间的直线段概念的推广(实际的测地线不一定是最短的,但我们先不纠结细节,而且这不妨碍我们理解它,因为测地线至少是局部最短的)。不难想到,只要两点确定了,那么不管使用什么坐标,两点间的最短线就已经确定了,因此这显然是一个客观实体。有一个简单的类比,就是不管怎么坐标变换,一个函数$f(x)$的图像极值点总是确定的——不管你变还是不变,它就在那儿,不偏不倚。
5
Nov
【外微分浅谈】4. 微分不微
By 苏剑林 | 2016-11-05 | 31719位读者 | 引用外微分
向量的外积一般只定义于不超过3维的空间。为了在更高维空间中使用反对称运算,我们需要下面描述的微分形式与外微分。
我们知道,任意$x$的函数的微分都可以写成$dx^{\mu}$的线性组合,在这里,各$dx^{\mu}$实则上扮演了一个基的角色,因此,我们不妨把$dx^{\mu}$看成是一组基,并且把任意函数称为微分0形式,而诸如$\omega_{\mu}dx^{\mu}$的式子,称为微分1形式。
在$dx^{\mu}$这组基之上,我们定义外积$\land$,即有反对称的运算$dx^{\mu}\land dx^{\nu}$,并且把诸如$\omega_{\mu\nu}dx^{\mu}\land dx^{\nu}$的式子,称为微分2形式。注意到这是$n$维空间中的外积,$dx^{\mu}\land dx^{\nu}$事实上是一个新空间的基,而不能用$dx^{\mu}$的线性组合来表示。
23
Feb
SVD分解(三):连Word2Vec都只不过是个SVD?
By 苏剑林 | 2017-02-23 | 98209位读者 | 引用这篇文章要带来一个“重磅”消息,如标题所示,居然连大名鼎鼎的深度学习词向量工具Word2Vec都只不过是个SVD!
当然,Word2Vec的超级忠实粉丝们,你们也不用太激动,这里只是说模型结构上是等价的,并非完全等价,Word2Vec还是有它的独特之处。只不过,经过我这样解释之后,估计很多问题就可以类似想通了。
词向量=one hot
让我们先来回顾一下去年的一篇文章《词向量与Embedding究竟是怎么回事?》,这篇文章主要说的是:所谓Embedding层,就是一个one hot的全连接层罢了(再次强调,这里说的完全等价,而不是“相当于”),而词向量,就是这个全连接层的参数;至于Word2Vec,就通过大大简化的语言模型来训练Embedding层,从而得到词向量(它的优化技巧有很多,但模型结构就只是这么简单);词向量能够减少过拟合风险,是因为用Word2Vec之类的工具、通过大规模语料来无监督地预训练了这个Embedding层,而跟one hot还是Embedding还是词向量本身没啥关系。
有了这个观点后,马上可以解释我们以前的一个做法为什么可行了。在做情感分类问题时,如果有了词向量,想要得到句向量,最简单的一个方案就是直接对句子中的词语的词向量求和或者求平均,这约能达到85%的准确率。事实上这也是facebook出品的文本分类工具FastText的做法了(FastText还多引入了ngram特征,来缓解词序问题,但总的来说,依旧是把特征向量求平均来得到句向量)。为什么这么一个看上去毫不直观的、简单粗暴的方案也能达到这么不错的准确率?
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 137173位读者 | 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$三个向量序列的交互和融合,其中$\boldsymbol{Q},\boldsymbol{K}$的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把$\boldsymbol{V}$按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}
20
Aug
最小熵原理(六):词向量的维度应该怎么选择?
By 苏剑林 | 2020-08-20 | 103001位读者 | 引用随着NLP的发展,像Word2Vec、Glove这样的词向量模型,正逐渐地被基于Transformer的BERT等模型代替,不过经典始终是经典,词向量模型依然在不少场景发光发热,并且仍有不少值得我们去研究的地方。本文我们来关心一个词向量模型可能有的疑惑:词向量的维度大概多少才够?
先说结论,笔者给出的估算结果是
\begin{equation}n > 8.33\log N\label{eq:final}\end{equation}
更简约的话可以直接记$n > 8\log N$,其中$N$是词表大小,$n$就是词向量维度,$\log$是自然对数。当$n$超过这个阈值时,就说明模型有足够的容量容纳这$N$个词语(当然$n$越大过拟合风险也越大)。这样一来,当$N=100000$时,得到的$n$大约是96,所以对于10万个词的词向量模型来说,维度选择96就足够了;如果要容纳500万个词,那么$n$大概就是128。
4
Dec
层次分解位置编码,让BERT可以处理超长文本
By 苏剑林 | 2020-12-04 | 124914位读者 | 引用大家都知道,目前的主流的BERT模型最多能处理512个token的文本。导致这一瓶颈的根本原因是BERT使用了从随机初始化训练出来的绝对位置编码,一般的最大位置设为了512,因此顶多只能处理512个token,多出来的部分就没有位置编码可用了。当然,还有一个重要的原因是Attention的$\mathcal{O}(n^2)$复杂度,导致长序列时显存用量大大增加,一般显卡也finetune不了。
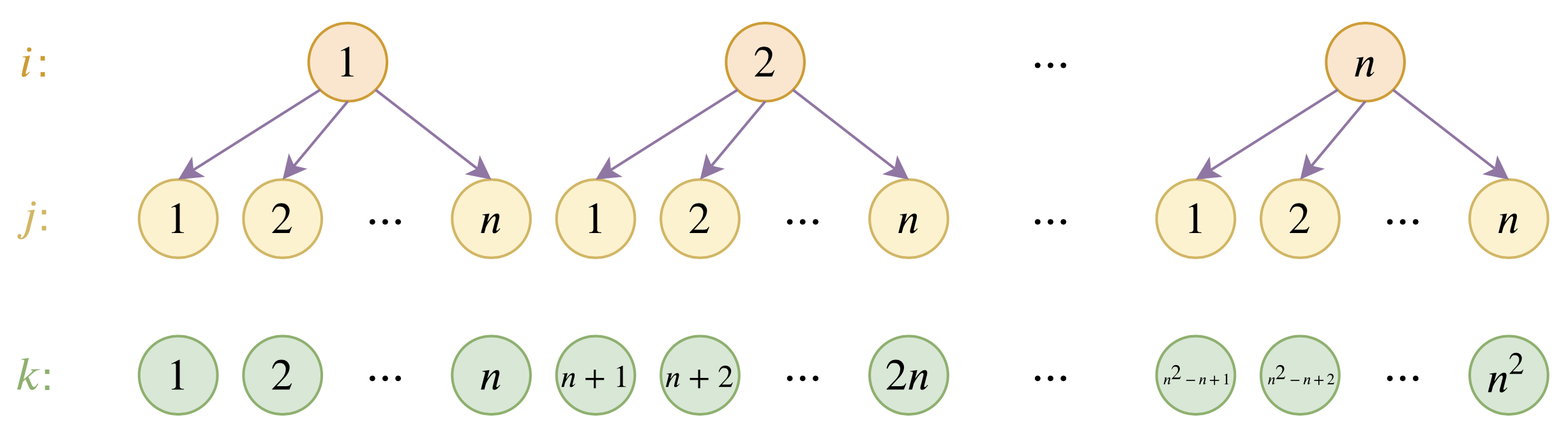
位置编码的层次分解示意图
本文主要面向前一个原因,即假设有足够多的显存前提下,如何简单修改当前最大长度为512的BERT模型,使得它可以直接处理更长的文本,主要思路是层次分解已经训练好的绝对位置编码,使得它可以延拓到更长的位置。

最近评论